 996
996 
Содержание
В этой статье для дата-инженеров и администраторов Apache Kafka рассмотрим, зачем Confluent выпустил премиум коннектор Splunk S2S Source и как на базе этих платформ построить эффективную систему потоковой аналитики больших данных. Также читайте далее, что такое универсальный сервер рассылки Splunk и какие конфигурации коннектора позволяют автоматически создавать топик Kafka для сбора и анализа системных событий в реальном времени.
Что такое Splunk и зачем Confluent выпустила премиум-коннектор к нему
Прежде всего отметим, что Splunk – это популярная платформа сбора и анализа машинных данных (логов) из любых источников. Отсутствие необходимости в предварительной разметке логов и встроенный язык запросов SPL (Search Processing Language) позволяют быстро найти в данных нужную информацию и представить ее в наглядной форме (отчеты, графики). Благодаря поддержке множества источников данных, пользователь может объединить события из разных систем, найти в них закономерности и увидеть полезные результаты аналитики больших данных. Задав пороговые значения по определенному параметру, можно генерировать оповещения об инцидентах или автоматически реагировать на них запуском скриптов по заданным правилам. Это полезно при управлении ИТ-инфраструктурой, аналитике работы программных продуктов, обеспечения информационной безопасности, мониторинга клиентского опыта и других вопросах анализа продуктовых метрик в различных бизнес-приложениях и системах интернета вещей [1]. В 2018 году Gartner объявила Splunk одной из наиболее популярных SIEM-систем, о которых мы подробно рассказываем здесь.
Надежный и безопасный сбор данных из удаленных источников и их пересылку в Splunk для индексации и консолидации обеспечивают универсальные сервера (Universal Forwarders, UF). Они могут масштабироваться до десятков тысяч удаленных систем, собирая терабайты данных . Можно установить тысячи таких UF-серверов на различных вычислительных платформах и архитектурах без потери производительность сети и хоста [2].
При том, что Splunk считается лучшей в своем классе платформой данных для таких случаев использования, таких как управление информацией о безопасности и событиями (SIEM, Security Information and Event Management), отправка в него всех логов не является оптимальной. Хотя в Splunk есть несколько механизмов для экспорта необработанных данных, он в первую очередь предназначен для приема больших объемов логов для их архивирования и анализа, а не для потоковой передачи в другие последующие системы и приложения. Поэтому компания Confluent, которая занимается коммерциализацией Apache Kafka, в июле 2021 года выпустила премиальный коннектора Splunk S2S Source Connector. Он позволяет экономично и эффективно отправлять логи в Splunk, а также другие последующие приложения и системы. А бесшовная интеграция этого коннектора с другими компонентами Kafka Confluent, включая более 120 коннекторов для других приложений и систем, можно построить гибкую систему мониторинга и анализа служебных данных с оперативным реагированием на любые отклонения и инциденты. В частности, аналитики больших данных могут дополнить Splunk возможностями ksqlDB и потоковой обработкой для создания SIEM и SOAR приложений реального времени, чтобы обеспечить улучшенное управление логами, обнаружение аномалий, антифрод-мониторинг средствами машинного обучения и пр [3].
Таким образом, главными преимуществами Splunk S2S Source Connector от Confluent являются следующие:
- Сокращение расходов на TCO (Total Cost Ownership) — снижение совокупной стоимости владения инфраструктурой данных за счет фильтрации объема малоценных данных, принимаемых платформой, и уменьшения нагрузки на инфраструктуру. Это также позволяет масштабировать сбор данных журнала и избегать ограничений на прием данных.
- Повышенная доступность, переносимость и функциональная совместимость данных за счет интеграции Splunk с Confluent и возможности их использования другими приложениями и системами. Отправляя данные в платформу Confluent, можно собирать, преобразовывать, фильтровать и очищать данные логов, прежде чем анализировать эти расширенные данные, чтобы увеличить гибкость поставщика данных и сократить затраты.
- Экономия около 12-24 и более месяцев работы дата-инженеров за счет использования готового настраиваемого коннектора источника Splunk. Отсутствие необходимости тратить время специалистов Big Data на это снижает технический долг и высвобождает ценные ресурсы, позволяя сосредоточиться на создании и улучшении бизнес-приложений реального времени.
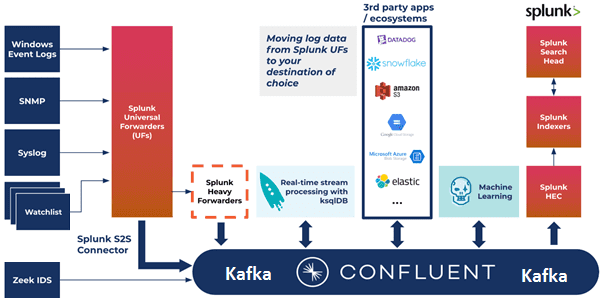
В качестве практического примера рассмотрим кейс записи сообщений из лог-файлов в топик Kafka, под названием splunk-s2s-events.
Потоковая аналитика больших данных с Apache Kafka и Splunk S2S Source Connector
Предположим, необходимо с помощью Splunk быстро обнаруживать угрозы кибербезопасности и незамедлительно реагировать на них в масштабах крупного предприятия. Но невозможно анализировать сырые данные напрямую из UF-сервера Splunk: сперва их следует обогатить, отфильтровать и обработать перед отправкой в следующие системы. При этом данные поступают из разных источников и в разных форматах. Решить эти проблемы можно с помощью коннектора Splunk S2S Source, который требует следующих пререквизитов [4]:
- Kafka Broker: Confluent Platform 6.0.0 или выше;
- Connect: Confluent Platform 6.0.0 или выше;
- Java 1.8;
- Splunk UF: 8.x.
Коннектор Splunk S2S Source поддерживает синтаксический анализ полей метаданных (хост, источник, тип источника и индекс) вместе с необработанным событием. Коннектор также поддерживает синтаксический анализ настраиваемых мета-полей, которые можно настроить на стороне сервера пересылки с помощью тега _meta:
[monitor://$SPLUNK_HOME/splunk-s2s-test.log] sourcetype = test disabled = false _meta = testField::testValue
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, сообщение в топике Apache Kafka будет выглядеть следующим образом:
{
"event": "sample log event",
"time": 1623175216,
"host": "sample host",
"source": "/opt/splunkforwarder/splunk-s2s-test.log",
"index": "default",
"sourcetype": "test",
"testField": "testValue"
}
Благодаря наличию множества конфигурационных параметров, возможно автоматическое создание топика Kafka для сбора таких сообщений. В частности, topic.creation.$alias.replication.factor позволяет задать фактор репликации для новых топиков Kafka, созданных коннектором. Это значение должно быть меньше количества брокеров в кластере Kafka, иначе возникнет ошибка. А, например, свойство topic.creation.$alias.exclude определяет список топиков как набор строк с регулярными выражениями, чтобы исключить совпадение названий топиков Kafka в пределах группы. Таким образом, благодаря гибкому набору настроек Apache Kafka и source-коннектор Splunk, на базе этих платформ можно построить эффективную систему мониторинга системных событий в реальном времени с приложениями потоковой аналитики больших данных. Как отправить данные в Splunk, используя Apache NiFi, читайте в нашей новой статье.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Узнайте больше полезных кейсов с Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

