 974
974 
Содержание
YARN считается самым распространенным диспетчером ресурсов в кластерах Apache Hadoop и Spark, отвечая за выделение ресурсам распределенным приложениям. Сегодня в рамках обучения дата-инженеров и администраторов Hadoop рассмотрим достоинства и недостатки 3-х вариантов планирования ресурсов в YARN. Читайте далее, что такое иерархия очереди и как вычисляется ее мгновенная справедливая доля.
Планирование ресурсов в Apache YARN: типы планировщиков
Напомним, Apache YARN (Another Resource Negotiator) – это платформа управления ресурсами кластера для распределенных вычислений, которая чаще всего используется с Hadoop, но благодаря своей универсальности может применяться и с другими платформами. YARN отвечает не только за выделение ресурсам распределенным приложениям, но сегодня мы рассмотрим именно этот его аспект: планировщик (Sheduler). Итак, планировщик обрабатывает распределение ресурсов для заданий, отправленных в YARN, согласно политике выделения, установленной для его типа. Различают 3-х типа планировщиков [1]:
- FIFO (First In First Out) – самый простой, который запускает приложения в порядке подачи, помещая их в очередь. Приложение, отправленное первым, сначала получает ресурсы, а по его завершении планировщик обслуживает следующее приложение в очереди. FIFO не подходит для общих кластеров, поскольку большие приложения будут занимать все ресурсы, а очереди станут длиннее из-за более низкой скорости обслуживания.
- Capacity – более сложный вариант FIFO, который позволяет совместно использовать кластер Hadoop между группами внутри организации, выделяя каждой команде выделяется определенную емкость общего кластера. Очереди могут быть дополнительно разделены иерархически, но приложения в них по умолчанию планируются с использованием расписания FIFO. Отдельная выделенная очередь позволяет запускать небольшие задания сразу после их отправки.
- Fair – самый продвинутый вариант планировщика с учетом приоритетности заданий, который стремится распределить ресурсы так, чтобы все запущенные приложения получили одинаковую долю. Fair Scheduler позволяет приложениям YARN совместно и динамически использовать ресурсы в большом кластере Hadoop без предварительного указания их емкости.
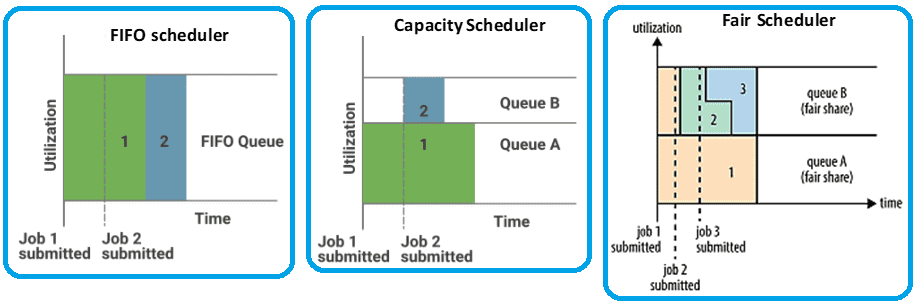
Итак, FIFO-планировщик блокирует небольшое задание до завершения большого задания. Capacity-планировщик поддерживает отдельную очередь для небольших заданий, чтобы запускать их сразу после поступления запроса. Однако в этом случае выполнение больших заданий требует больше времени из-за лимитов емкости кластера, ограниченной очередью. Так Capacity-планировщик гарантирует, что приоритетные и мелкие задания не будут слишком долго задерживаться по сравнению с планировщиком FIFO. Но при наличии свободных ресурсов, Capacity-планировщик может выделить их для заданий в очереди, даже если это повысит ее емкость. Это называется эластичностью очереди.
У Fair-планировщика нет требований к резервированию емкости: он динамически распределяет ресурсы по всем принятым заданиям. Когда задание запускается, оно получает все ресурсы кластера, если является единственным. Следующее запущенное задание получит ресурсы при высвобождении контейнеров – фиксированного объема ОЗУ и ЦП. По завершении небольшого задания планировщик назначает ресурсы большому. Таким образом, Fair-планировщик устраняет недостатки FIFO и Capacity, позволяя своевременно завершать небольшие задания с высокой степенью утилизации кластера, которая показывает эффективность использования его ресурсов. На практике именно этот вариант используется чаще всего, поэтому его мы рассмотрим далее подробно [2].
Примечательно, что в свежем релизе Apache Hadoop 3.3.1, о котором мы писали здесь, для очереди Capacity-планировщика добавлена конфигурация на основе API. Теперь пользователи могут вызвать REST API для изменения конфигураций очереди, а администратор кластера Hadoop может автоматизировать управление конфигурацией очереди в ACL-списках.
Fair Scheduler: иерархия очередей и политики планирования
Fair Scheduler использует иерархические очереди. Очереди являются одноуровневыми очередями, если у них один и тот же родительский элемент. Все очереди являются дочерними по отношению к корневой, даже. Для расчета доли выделения ресурсов Big Data кластера очереди имеют веса. Веса — это не совсем то же самое, что проценты, хотя часто для простоты понимания используются числа, которые в сумме дают 100. Вес, связанный с очередью, определяет количество ресурсов, которых очередь заслуживает по сравнению с соседними очередями. Это называется справедливая доля ресурсов очереди (Steady FairShare) и рассчитывается как произведение родительской Steady FairShare на вес очереди, деленный на сумму весов всех очередей ее уровня иерархии.
Однако, вычисленное таким образом число является лишь потенциальной стоимостью, обеспечивая только горизонт ожидаемых ресурсов, но не используется при планировании решений, включая приоритетное прерывание. Для реального выделения ресурсов с учетом эластичности очередей в многопользовательском кластере, Fair Scheduler позволяет им потреблять больше ресурсов, чем их справедливая доля при наличии свободных резервов. Поэтому в реальности вместо Steady FairShare используется Instantaneous FairShare — значение FairShare для каждой очереди, основанное только на активных очередях, где имеется хотя бы 1 запущенное приложение. Instantaneous FairShare не означает, что это количество ресурсов зарезервировано для конкретной очереди. Этот показатель рассчитывается как произведение родительского Instantaneous FairShare на вес очереди, деленный на сумму весов всех очередей ее уровня иерархии.
Мгновенная справедливая доля изменяется со временем, и все, что выше этого значения, будет вытеснено в соответствии с условиями вытеснения. Вытеснение позволяет восстанавливать ресурсы из очередей, превышающих их FairShare, не дожидаясь, пока они сами освободят ресурсы. По умолчанию для всех очередей установлено значение true, которое можно заменить на false, если в кластере запущены очереди с приоритетом.
Вытеснение работает при выполнении следующих условий:
- включено на уровне обслуживания YARN через конфигурацию yarn.scheduler.fair.preemption с использованием тайм-аута приоритетного прерывания в секундах;
- использование ресурсов на уровне кластера превышает порог использования вытеснения Fair-планировщика – параметр scheduler.fair.preemption.cluster-utilization-threshold, который по умолчанию составляет 80%.
Например, для очереди prod тайм-аут прерывания справедливой доли ресурсов составляет 30 секунд, а порог прерывания равен 0,9. Это означает, что в течение 30 секунд, если емкость очереди составляет менее 90% ее Instantaneous FairShare, то задачи в этой очереди будут вытеснены другими. Такое вытеснение позволяет сделать время, необходимое для запуска задания, было более предсказуемым с учетом их приоритета. В частности, когда задание отправляется в пустую очередь в занятом кластере, оно не может быть запущено, пока ресурсы не освободятся от заданий, которые уже выполняются в кластере. Вытеснение позволяет планировщику уничтожать контейнеры для очередей, которые работают с большей долей ресурсов, чем им положено. Поэтому ресурсы могут быть выделены другой очереди. Однако, вытеснение снижает общую эффективность кластера из-за повторного выполнения некоторых уже завершенных контейнеров [3]. С вытеснением в Fair-планировщике YARN связаны 2 важных параметра [2]:
- fairSharePreemptionTimeout – количество секунд, в течение которых очередь находится ниже своего порогового значения справедливого распределения, прежде чем она попытается вытеснить контейнеры, чтобы взять ресурсы из других очередей. Если не установлен, очередь наследует это значение из родительской.
- fairSharePreemptionThreshold – порог вытеснения справедливой доли для очереди. Если очередь ожидает fairSharePreemptionTimeout без получения ресурсов, равных произведению fairSharePreemptionThreshold на FairShare, то она может вытеснять контейнеры, чтобы взять ресурсы из других очередей.
Очереди могут иметь разные политики планирования, заданные в элементе defaultQueueSchedulingPolicy верхнего уровня. Если этот параметр не определен, используется Fair-планирование. Несмотря на свое название, Fair Scheduler также поддерживает политику FIFO для очередей, а также Dominant Resource Fairness (DRF), которая позволяет вычислить оптимальное для каждого приложения количество памяти и ЦП с учетом доминирующего ресурса каждого пользователя как меры использования кластера. Наконец, помимо настройки иерархии и емкости очередей, существуют параметры для управления максимальным количеством ресурсов, которое может быть выделено для одного пользователя или приложения, количеством приложений, которые могут быть запущены одновременно, а также ACL-списками [3].
Таким образом, внутри YARN работают слаженные механизмы эффективного выделения вычислительных ресурсов работающим и запускаемым распределенным приложениям. Именно поэтому этот менеджер ресурсов чаще всего используется в современных кластерах экосистемы Apache Hadoop.
Освойте администрирование и эксплуатацию Apache Hadoop для хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://towardsdatascience.com/schedulers-in-yarn-concepts-to-configurations-5dd7ced6c214
- https://karthiksharma1227.medium.com/deep-dive-into-yarn-scheduler-options-cf3f29e1d20d
- https://www.corejavaguru.com/bigdata/hadoop-tutorial/yarn-scheduler

