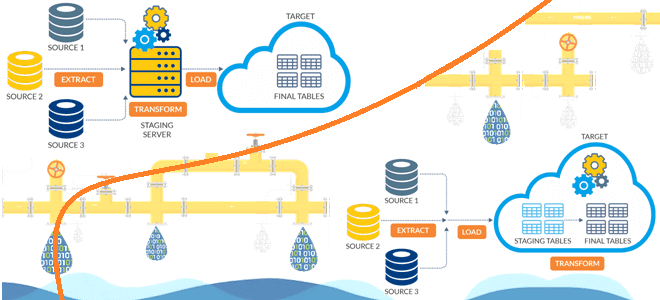
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов. Чем ETL отличается от ELT: ликбез для дата-инженера Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их...

Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...
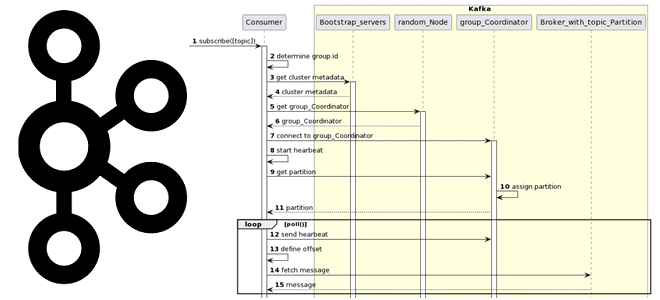
Вчера мы разбирали работу приложения-продюсера и строили UML-диаграмму последовательности. Сегодня рассмотрим, какие системные вызовы происходят при потреблении сообщений из Apache Kafka, при чем здесь группы потребителей и фиксация смещений. Как работает потребитель Kafka Аналогично разработке приложения-продюсера, при написании кода потребителя, который считывает данные из топика Apache Kafka, используются методы специальных...
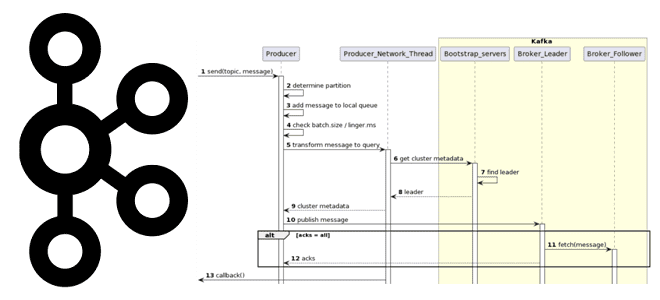
Как на самом деле работает приложение-продюсер Apache Kafka: разбираемся с конфигурациями и составляем UML-диаграмму последовательности системных вызовов при публикации сообщений в топик. Как работает продюсер Kafka Когда разработчик пишет приложение-продюсер, которое публикует сообщение в топик Apache Kafka, он использует методы специальных библиотек, таких как kafka-python и пр. Достаточно только создать...
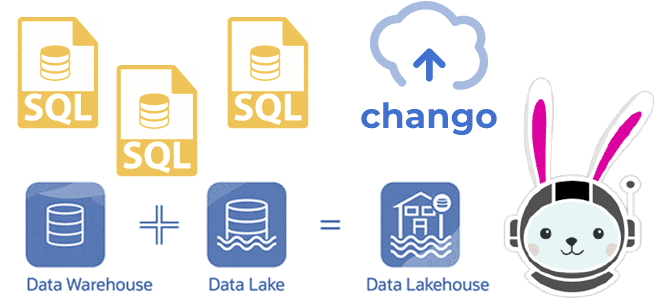
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...
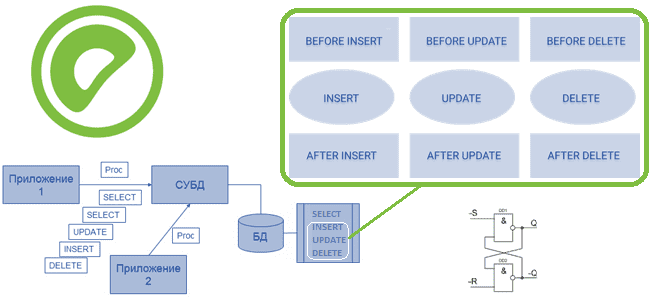
Где и как используются триггеры, чем они отличаются от хранимых процедур, как это реализуется в Greenplum. Создание, изменение и удаление триггеров и ограничения их применения в Greenplum. Что такое хранимые процедуры и триггеры Напомним, хранимые процедуры представляют собой именованные блоки SQL-команд, которые заранее откомпилированы и хранятся на сервере, чтобы ускорить...

Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN. Архитектура и режимы развертывания Spark-приложения Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на...
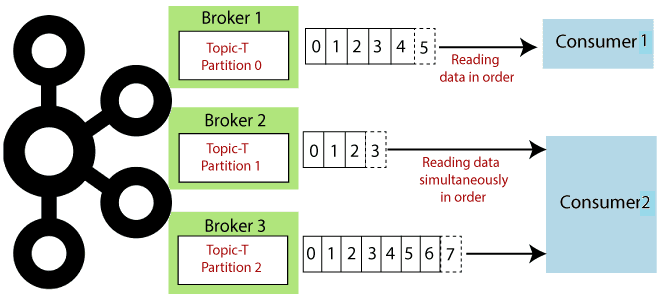
Что общего у Kafka Streams и Consumer API, чем они отличаются и что выбирать для практического использования: краткое руководство для разработчика приложений потоковой обработки событий. Возможности и ограничения Kafka Streams и Consumer API Поскольку Apache Kafka как огромная экосистема со множеством компонентов для потоковой передачи событий, обилие и разнообразие этих...
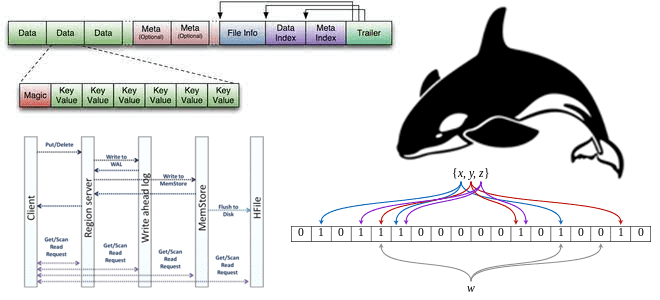
Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума. Роль HFile в Apache HBase Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок»...

Как не запутаться в многообразии коннекторов к Kafka, доступных во Flink Table API, и выбрать наиболее подходящий для своего сценария применения. Разница между Append Mode и Upsert-режимом коннектора Flink SQL к Kafka. 2 режима работы коннектора Kafka в Apache Flink Apache Flink поставляется с универсальным соединителем Kafka, который поддерживает последнюю...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Чего не хватает в PL/Python и зачем нужна еще одна библиотека для создания Python-скриптов обработки данных в Greenplum. Возможности API GreenplumPython и сравнение с pandas. Что такое PL/Python и как это работает в Greenplum Мы уже писали, что Greenplum изначально поддерживает Python, предоставляя PL/Python – загружаемый процедурный язык, который позволяет...
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
Какие проблемы характерны для распределенных очередей сообщений, почему они случаются и как с ними справиться. Разбираемся со сбоями, ошибками и перегрузками на примере Apache Kafka и RabbitMQ. Проблемы с распределенными очередями и главные причины их появления Хотя Apache Kafka — это целая экосистема со множеством компонентов для потоковой передачи событий,...
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue. 4 стратегии работы с DLQ-топиками в Apache Kafka Напомним, в Apache Kafka в очереди недоставленных...
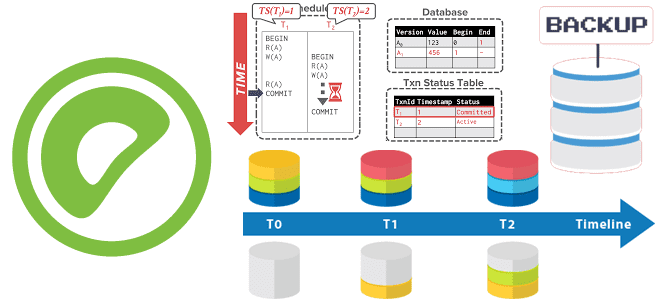
Как Greenplum расширяет MVCC-модель PostgreSQL для управления доступом к данным в многопользовательской среде, обеспечивая согласованность и изоляцию транзакций для нескольких сегментов в большом кластере. Преимущества моментальных снимков перед блокировками и их польза для резервного копирования. MVCC и транзакции в Greenplum с PostgreSQL Будучи основанной на PostgreSQL, о чем мы писали здесь,...

23 марта 2023 года вышел очередной релиз Apache Flink. Разбираемся с главными новинками выпуска 1.17.0: полезные фичи, исправленные ошибки и улучшения для дата-инженера и разработчика распределенных приложений. Новинки пакетной обработки В Apache Flink 1.17 внесено множество изменений в области пакетной и потоковой обработки. В частности, добавлен новый пакетный Streaming Warehouse...
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...
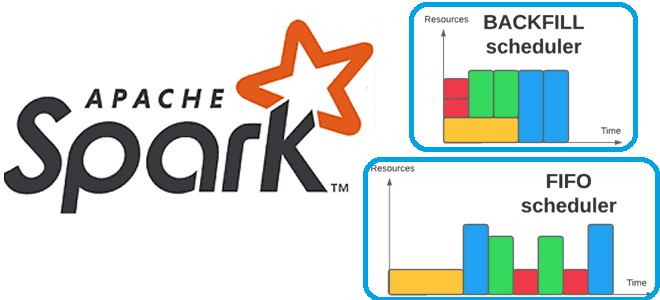
Что такое backfill-операции в конвейерах заданий Apache Spark, чем они отличаются от исторического заполнения датасетов, зачем их автоматизировать и как это сделать. Что такое backfilling для заданий Apache Spark Мы уже писали про понятие backfill на примере модификации DAG при добавлении новых заданий в конвейер Apache AirFlow. Эта функция полезна,...