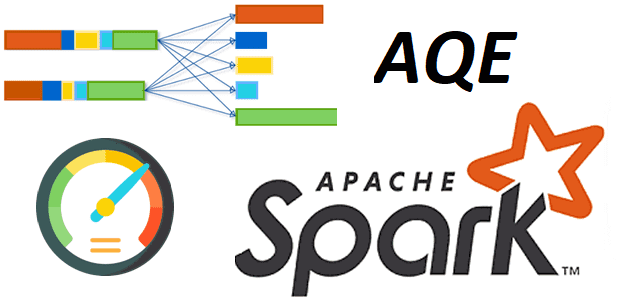
Недавно мы рассматривали практический пример разделения большого датафрейма Apache Spark на несколько разделов. Сегодня поговорим о том, как их объединить с помощью механизм AQE и динамической настройки конфигурации spark.sql.shuffle.partitions. Разделы и оптимизация распределенных вычислений в Spark-приложениях Распределение данных по разделам сильно влияет на скорость работы Spark-приложений. Распределенное приложение выполняется наиболее...
Чем инженерия данных отличается от разработки ПО, как организовать оркестрацию конвейеров обработки данных и внедрить лучшие практики CI/CD. Почему дата-инженерия отличается от разработки ПО При том, что между инженерией данных и разработкой программного обеспечения (ПО) очень много общего, эти ИТ-дисциплины довольно сильно отличаются. Хотя в обоих направлениях используется облачная инфраструктура,...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
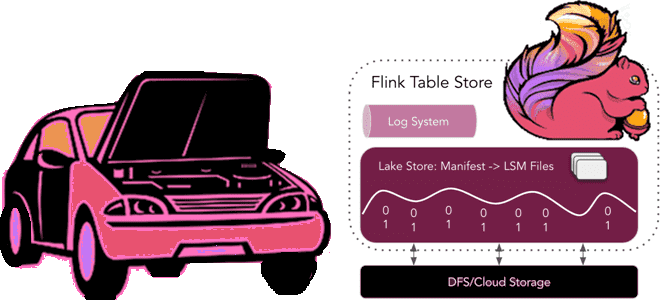
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов. Архитектура и принципы работы Flink Table Store Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма...
Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто. Как работает ksqlDB: практический пример Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных...
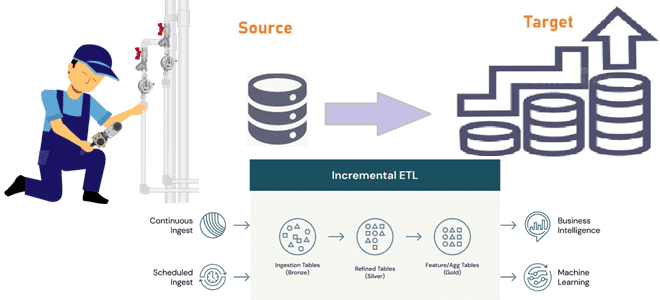
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
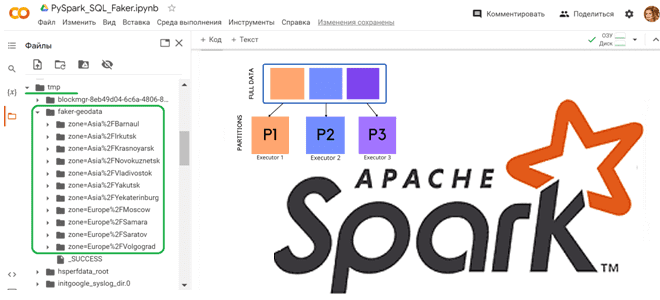
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...

Мы уже писали про тестирование приложений Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Сегодня рассмотрим, как с помощью тестовых наборов тестировать UDF-функции, использующих состояние и таймеры. Модульное тестирование UDF-функций Flink-приложения с помощью тестовых наборов При работе с Apache Flink разработчики часто сталкиваются с проблемами при...
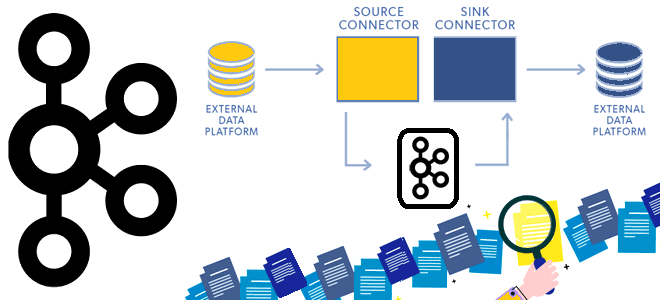
Сегодня рассмотрим принципы работы компонента экосистемы Apache Kafka под названием Connect и разберемся, как он устроен. Программная архитектура коннекторов и способы избежать дубликатов при зависании внешней системы-приемника. Архитектура и принципы работы Kafka Connect Apache Kafka не зря считается платформой потоковой передачи, а не просто брокером сообщений. Вокруг нее выстроена целая...

Как сделать запуск UDF-функций Python или R на узлах сегмента Greenplum более быстрым и безопасным с помощью Docker-контейнеров и расширения PL/Container. Что такое PL/Container и как это использовать в Greenplum Запуск пользовательского кода для базы данных всегда имеет риск нарушения информационной безопасности. Если речь идет о стеке Big Data, ущерб...
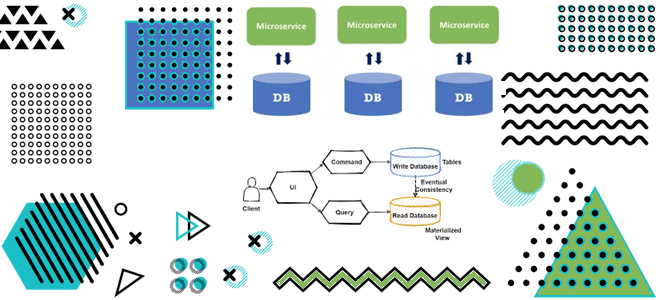
Как материализованные представления в потоковой базе данных с CDC-подходом и шаблоном CQRS позволяют реализовать масштабируемую и высокопроизводительную систему с микросервисной архитектурой для транзакций и аналитики данных в реальном времени. Разбираемся с паттернами проектирования микросервисов на примере интернет-магазина. Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в...
Обогащение потока данных информацией из внешнего API без остановки вычислений: 3 способа реализовать это средствами Apache Flink на примере сервиса геолокации. Зачем обогащать потоковые данные через внешний API и как это сделать для Flink-приложения? Иногда необходимо обогатить потоки данных, т.е. дополнить потоковые данные в реальном времени, т.е. на лету, не...
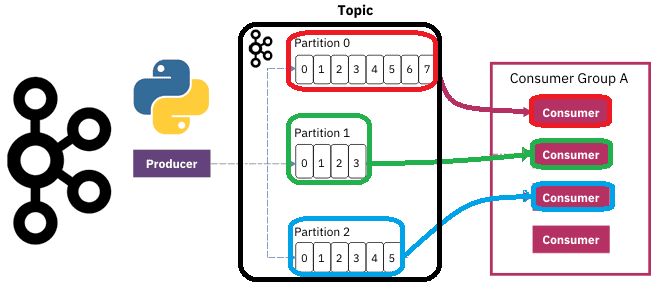
Чтобы разобраться, как на самом деле работают разделы и потребители Apache Kafka, сегодня рассмотрим небольшой демонстрационный пример, иллюстрирующий потребление сообщений. Пишем Python-скрипты публикации и потребления сообщений из разных разделов топика Kafka с занесением данных в несколько вкладок Google-таблицы. Как сообщения распределяются по разделам топика Kafka Напомним, в Apache Kafka раздел...

12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...
Через какие интерфейсы пользователи и клиентские приложения могут подключиться к базе данных Greenplum, как происходит подключение, какие параметры и конфигурации надо задать при этом, а также почему для этого так важна библиотека libpq. Параметры подключения к Greenplum Пользователи могут подключаться к базе данных Greenplum с помощью клиентской программы, совместимой с...
Мы уже писали о важности отслеживания системных метрик приложений Apache Flink и RocksDB, используемой этим фреймворком для хранения состояния stateful-заданий. Сегодня рассмотрим, как отследить потребление ресурсов ЦП средствами встроенной визуализации Flame Graphs. Что такое Flame Graph и зачем это нужно? Помимо мониторинга длительности выполнения задач и заданий, дата-инженерам и разработчикам...
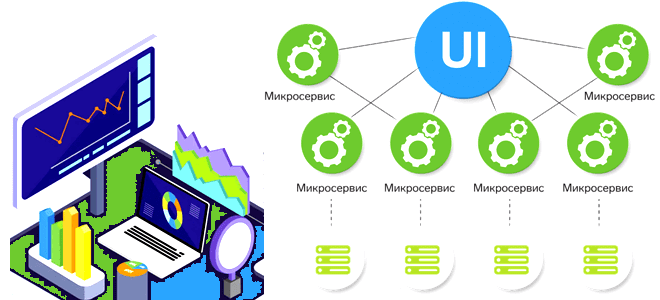
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...

Чем тип JSONB отличается от JSON и почему это так важно для хранения и обработки данных гибкой структуры в Greenplum. Примеры SQL-запросов к JSON-данным и особенности синтаксиса JSONPath. Чем JSONB отличается от JSON и почему это так важно? Будучи основанной на PostgreSQL, Greenplum имеет множество аналогичных возможностей, включая поддержку работы...
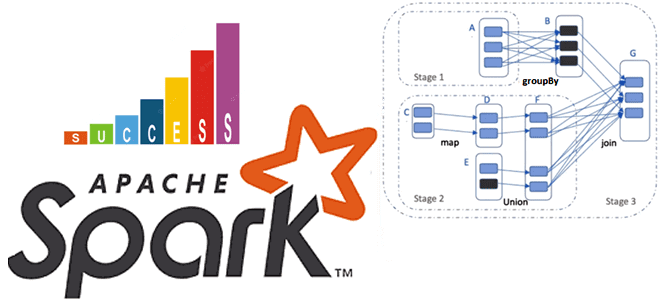
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...
Что не так с механизмом контрольных точек в Apache Flink, и как журнал изменений состояния справляется с ростом сквозной задержки в потоковой обработке данных средствами этого фреймворка. Проблемы контрольных точек в Apache Flink Одной из наиболее важных характеристик систем потоковой обработки данных является сквозная задержка, которая в Apache Flink зависит...