 1397
1397 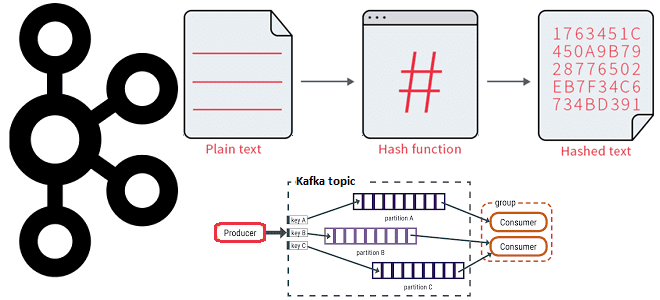
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии.
3 стратегии распределения сообщений по разделам в Apache Kafka
В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в кластере и потребителей. Упорядоченность сообщений по принципу FIFO (First In First Out) гарантируется в рамках раздела. Как мы уже рассматривали здесь, Kafka поддерживает несколько стратегий (принципов) партиционирования, т.е. распределения входящих сообщений по разделам топика:
- круговой перебор, используемый по умолчанию;
- ключ партиционирования, от которого берется хэш-функция для вычисления номера раздела;
- пользовательский разделитель с явным указанием раздела согласно бизнес-логике потоковой системы.
Как и пользовательский разделитель с явным указанием раздела, стратегия разделения по ключу партиционирования является детерминированной. Это означает, что сообщения с одним и тем же ключом последовательно назначаются одному и тому же разделу, сохраняя порядок связанных сообщений внутри раздела. Если ключ имеет значение NULL или не указан, механизм циклического перебора распределяет сообщения равномерно по доступным разделам.
Тонкости хэширования
Из всех вышеперечисленных стратегий принцип действия ключа партиционирования с вычислением хэша является самым непрозрачным способом из-за неявного вычисления хэш-функции от значения, определенного в коде приложения-потребителя. При этом алгоритм хэширования может зависеть от языка разработки. В частности, Java-библиотека для продюсеров Kafka для вычисления хэш-значения ключа партиционирования использует 32-битный алгоритм хэширования murmur2. Это простая и быстрая хеш-функция общего назначения, разработанная Остином Эпплби. Она не является криптографически-безопасной и возвращает 32-разрядное беззнаковое число. Ее главными достоинствами является простота, хорошее распределение, мощный лавинный эффект, высокая скорость и сравнительно высокая устойчивость к коллизиям. Текущие версии алгоритма murmur2 оптимизированы под Intel-совместимые процессоры.
Однако, далеко не все разработчики используют Java для создания продюсеров Kafka. Например, написать код для работы с Kafka на Python, Go, .NET, C# и других языках программирования помогает библиотека librdkafka. Она предоставляет высокопроизводительную, легкую и многофункциональную реализацию протокола Kafka, позволяя клиентским приложениям взаимодействовать с кластерами Kafka.
Однако, librdkafka по умолчанию использует другой алгоритм хэширования — CRC32 — 32-битная циклическая проверка контрольной суммы (Cyclic Redundancy Check). Этот алгоритм представляет собой способ цифровой идентификации некоторой последовательности данных, который заключается в вычислении контрольного значения её циклического избыточного кода. Он тоже довольно прост в реализации и подходит для обнаружения пакетных ошибок: непрерывных последовательностей ошибочных символов данных в сообщениях.
В общем виде контрольная сумма представляет собой некоторое значение, вычисленное по определённой схеме на основе кодируемого сообщения. Проверочная информация при систематическом кодировании приписывается к передаваемым данным. На принимающей стороне абонент знает алгоритм вычисления контрольной суммы, поэтому программа может проверить корректность принятых данных. Сущность алгоритма в том, что ошибка в сообщении приведёт к изменению его контрольной суммы. Если исходная и вычисленная суммы не равны между собой, принимается решение о недостоверности принятых данных, и можно запросить повторную передачу пакета.
Как и murmur2, алгоритм CRC32 также генерирует 32-битное хэш-значение фиксированного размера для заданных входных данных. Однако, поскольку функции хеширования разные, они дают разные результаты. Поэтому сообщения с одним и тем же ключом партиционирования, созданные Java-продюсером могут быть направлены в другие разделы, чем те же самые сообщения, отправленные приложением, написанным на другом языке.
Поэтому если продюсер Python и коннектор источника на основе Java создают данные для разных топиков в Kafka, их соединение с использованием API Kafka Streams или ksqlDB не будет работать корректно, поскольку значения разделов будут отличаться. Это иллюстрирует таблица с примерами хэшей, вычисленных для одних и тех же ключей с помощью разных алгоритмов:
|
Ключ сообщения |
Murmur2 |
CRC32 |
||
|
Хэш |
Раздел |
Хэш |
Раздел |
|
|
my_key_1 |
1322862588 |
0 |
2133006026 |
2 |
|
my_key_2 |
201614428 |
4 |
3861530480 |
2 |
|
my_key_3 |
273244397 |
5 |
2435676134 |
2 |
|
my_key_4 |
1336656080 |
2 |
256500293 |
5 |
Поскольку Kafka часто используется как средство асинхронной интеграции между несколькими сервисами в крупномасштабной системе, подобное несоответствие назначения разделов может привести к ошибкам и некорректным вычислениям. Поэтому необходимо устранить риск неоднозначного назначения разделов при использовании разных языков программирования для разработки продюсеров.
Для этого в языках на основе библиотеки librdkafka есть свойство конфигурации, называемое разделителем (partitioner). Чтобы он соответствовал Java, ему следует установить значение murmur2_random.
Например, в моей любимой Python-библиотеке kafka-python разделитель можно задать при объявлении объекта класса KafkaProducer, определив параметр partitioner. Он по умолчанию использует murmur2 — тот же алгоритм хэширования, что и Java клиент. Поэтому ничего дополнительно задавать не нужно, достаточно объявить объект класса KafkaProducer. Это демонстрирует пример создания объекта продюсера, который будет отправлять в кластер Kafka сообщения с полезной нагрузкой в JSON-формате:
!pip install kafka-python
#импорт модулей
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['........адрес или название виртуального хоста вашего сервера с портом 9092 для защищенного соединения'],
sasl_mechanism='SCRAM-SHA-256',
security_protocol='SASL_SSL',
sasl_plain_username='......... имя пользователя',
sasl_plain_password='.......... пароль для этого пользователя',
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
А эта инструкция отвечает за публикацию сообщения в топик с названием InputsTopic с ключом, равным значению переменной mes_key.
future = producer.send(topic='InputsTopic', value=data, partition=None, key=mes_key)
Поскольку в этом вызове метода send() не задан явно раздел, т.е. значение параметра partition = None, то сообщения с одним и тем же ключом будут доставлены в один и тот же раздел, вычисленный с помощью хэш-функции ключа с использованием алгоритма murmur2. При этом ключ должен иметь тип byte или быть сериализуемым в байты с помощью настроенного key_serializer, тоже задаваемого при создании объекта класса продюсер, например,
producer = KafkaProducer(key_serializer=str.encode)
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

