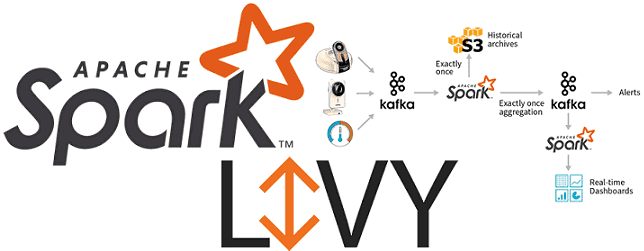
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...

Чтобы наглядно показать, как аналитика больших данных и машинное обучение помогают быстро решить актуальные бизнес-проблемы, сегодня мы рассмотрим кейс компании Леруа Мерлен. Читайте в нашей статье про нахождение аномалий в сведениях об остатках товара на складах и в магазинах с помощью моделей Machine Learning, а также про прикладное использование Apache...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...
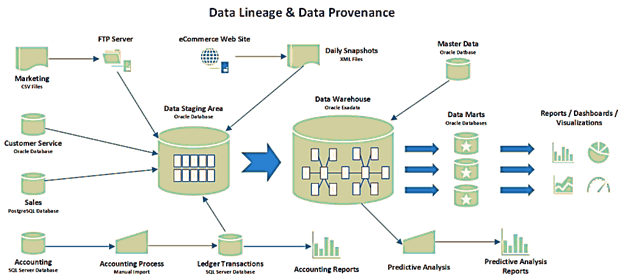
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...

Управление данными не сводится к выделению роли дата стюарда и обеспечению Data Quality. Сегодня мы расскажем, что такое мастер-данные, как искусственный интеллект помогает решать проблемы управления НСИ и почему эффективный Master Data Management (MDM) особенно важен в мире Big Data. Что такое мастер-данные или зачем управлять НСИ Начнем с определения:...

Сегодня мы поговорим про качество данных – что это за показатель, в чем он измеряется и почему так важен для машинного обучения и других приложений Big Data. Читайте в нашей статье про процессы и инструменты управления качеством данных, а также профессию Data Quality инженера. Почему большие данные должны быть качественными...
Не претендуя на лавры Мэри и Тома Поппендиков, которые впервые освятили применение Lean в разработке ПО, сегодня мы расскажем, как идеи бережливого производства реализуются в области Big Data. Читайте в нашей статье про принцип вытягивания в Apache Kafka, концепцию «точно вовремя» в Apache Spark, SMED в Kubernetes и облачных кластерах...
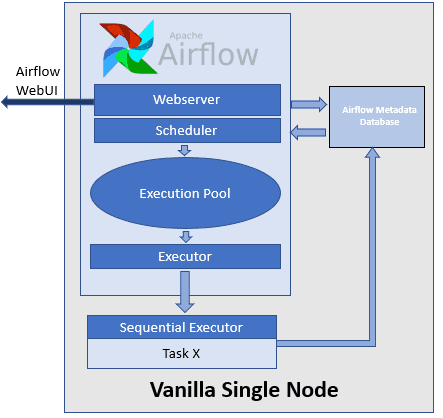
Недавно мы рассказывали про Airflow Kubernetes Executor, который позволяет выполнять задачи DAG-графа Эйрфлоу в среде Kubernetes, развертывая Docker-контейнер на отдельном пользовательском модуле (pod). Сегодня рассмотрим, какие еще есть исполнители задач в Apache Airflow, как они используются при автоматизации batch-процессов обработки больших данных и с какими проблемами можно столкнуться при их...
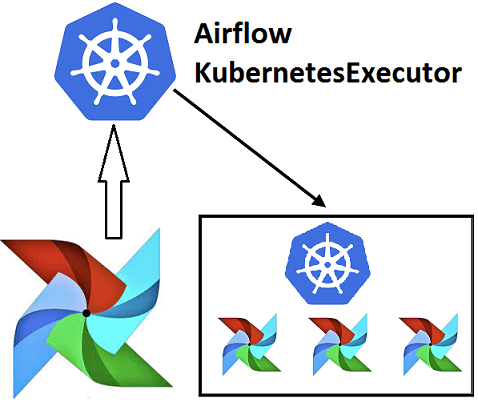
Эффективное обучение AirFlow, также как курсы по Spark, Hadoop, Kafka и другим технологиям больших данных (Big Data) также включают нюансы интеграции этого фреймворка с другими средами. Например, вчера мы рассматривали преимущества DevOps-подхода к разработке Data Flow на примере взаимосвязи Apache Airflow с Kubernetes посредством специальных операторов. Продолжая эту тему, сегодня...