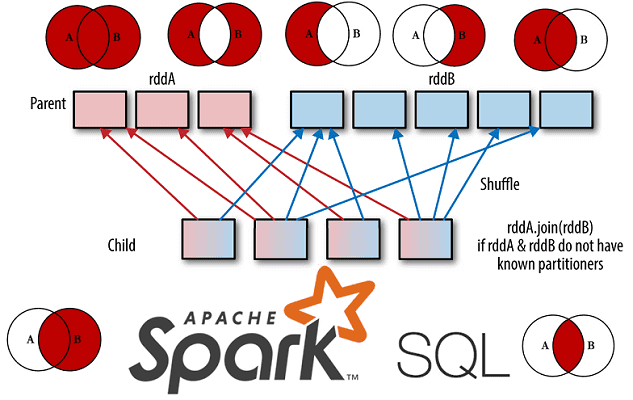
Развивая наши новые курсы по Apache Spark, сегодня мы рассмотрим Join-операции в SQL-модуле этого популярного фреймворка для аналитики больших данных. Читайте далее, чем отличаются разные Join-соединения друг от друга, как они реализуются в Spark SQL, какие существуют механизмы для их выполнения и от чего зависит выбор того или иного способа...

Обучение Apache Spark, Kafka, Hadoop и прочим технологиям Big Data – это не только курсы, теоретические статьи и практические задания, но и проверка полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по основам Спарк для начинающих. Проверьте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного...
Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...
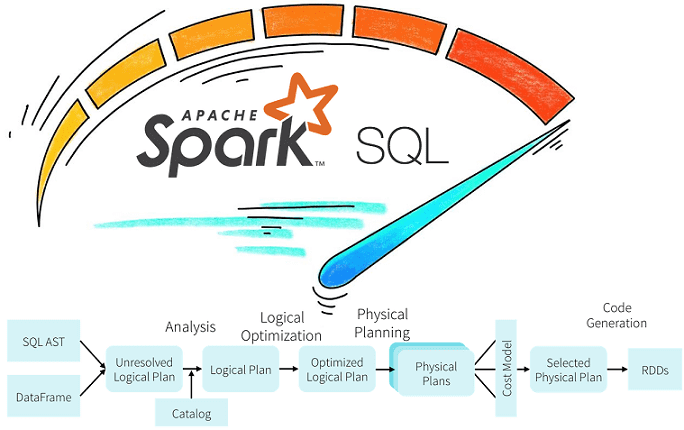
Продолжая разбирать практические особенности аналитики больших данных с Apache Spark, сегодня рассмотрим возможности оптимизации SQL-запросов в этом Big Data фреймворке с помощью механизмов предикатного и проекционного сжатия. Читайте далее про реализацию Predicate Pushdown и Projection Pushdown в Apache Spark 3, а также их связь с форматами Parquet и AVRO. Механизмы...
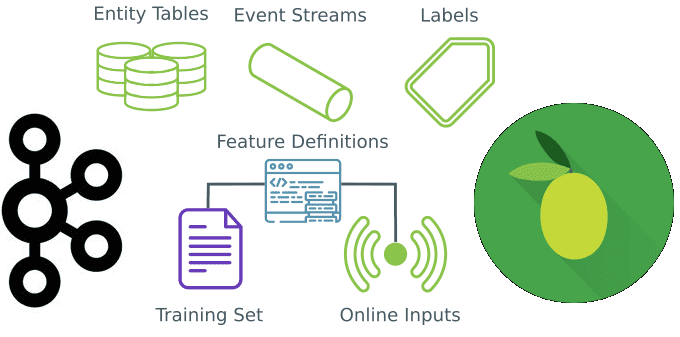
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

В продолжение вчерашнего материала про потоковую аналитику больших данных с Apache Kafka и Spark, сегодня рассмотрим особенности совместного использования этих технологий Big Data. В этой статье мы собрали для вас 5 лучших практик эффективного применения Apache Kafka и Spark Streaming для разработки распределенных приложений аналитики больших данных в режиме реального...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...