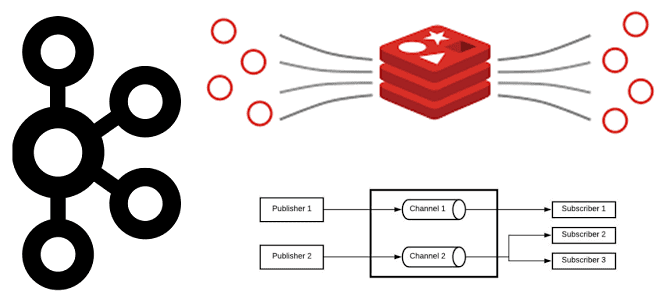
Как key-value СУБД Redis может работать с потоковыми данными и чем Pub/Sub и Streams отличаются от Apache Kafka. Сравнение и рекомендации по использованию. Потоковое сохранение данных Redis Будучи очень быстрым key-value хранилищем, NoSQL-СУБД Redis часто используется в качестве слоя кэширования для разгрузки основной базы данных. В отличие от многих других...

Насколько быстро ClickHouse выполняет SQL-запросы: тестирование СУБД в открытой онлайн-песочнице. Примеры запросов и время их выполнения. Работа с онлайн-песочницей Clickhouse: выполнение SQL-запросов Будучи реляционной аналитической СУБД, ClickHouse позволяет обрабатывать гигабайты данных в реальном времени. Архитектурные особенности, благодаря которым реализуется такая скорость, мы недавно разбирали здесь. Чтобы оценить это на практике,...

Сходства и различия популярных реляционных аналитических СУБД с открытым исходным кодом: что общего у Greenplum с ClickHouse, чем они отличаются, что и когда выбирать. Greenplum и Clickhouse: обзор возможностей для аналитики больших данных Обе СУБД являются реляционными и относятся к классу OLAP-систем, т.е. ориентированы на аналитические варианты использования, т.е. чтение...

Недавно мы писали об анонсированных новинках Apache NiFi 2.0. Наконец, 25 ноября 2023 года этот долгожданный мажорный релиз опубликован. Знакомимся с главными новостями версии 2.0, в которой более 900 обновлений, включая новые функции, улучшения и исправления ошибок. ТОП-7 новинок в Apache NiFi 2.0 Прежде всего, важной новинкой NiFi 2.0 является...
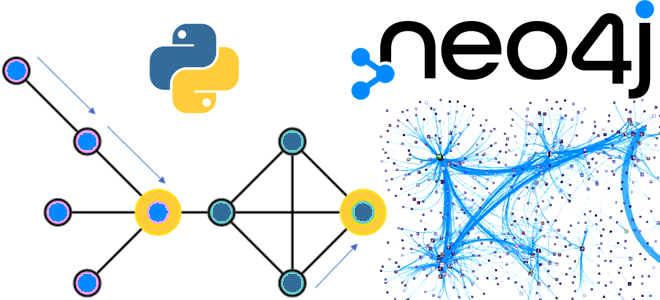
Что такое алгоритм k-medoids, чем он отличается от k-means и как этот метод кластеризации применяется для анализа графов: принципы и инструменты. Что такое медоид и как устроен алгоритм кластеризации k-medoids Кластеризация — это метод машинного обучения для поиска кластеров или сообществ в наборе данных. Цель в том, чтобы найти кластеры,...
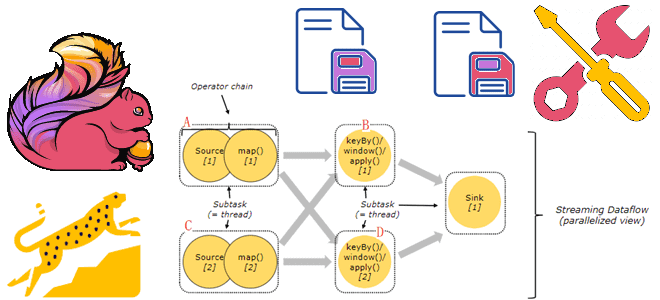
Почему хранить состояния Flink-приложений лучше на локальных SSD-диски, а не на твердотельных накопителях с удаленной файловой системой NFS или HDFS, зачем отключать блочный кэш RocksDB и как настроить параллелизм заданий. Проблемы сохранения состояния в RocksDB и способы их решения Как мы уже упоминали здесь, key-value хранилище RocksDB является самым популярным...
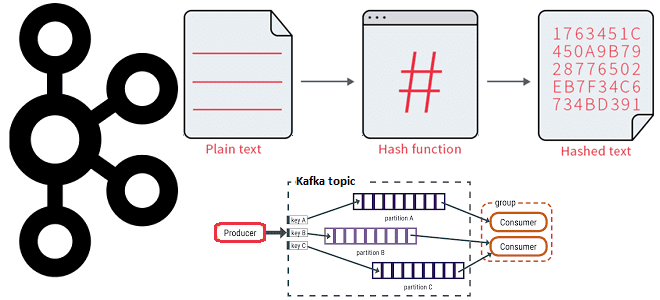
Как работает распределение сообщений по разделам топика Kafka с явно заданным ключом партиционирования и на что влияет язык разработки приложения-продюсера при использовании этой стратегии. 3 стратегии распределения сообщений по разделам в Apache Kafka В Apache Kafka единицей параллелизма выступает раздел топика. Используя несколько разделов, можно распределять нагрузку на брокеров в...

Ранее мы писали про проблемы повышения производительности Apache AirFlow и каковы их причины. В продолжение этой темы сегодня рассмотрим, как настроить этот ETL-оркестратор, чтобы избежать подобных ситуаций и масштабировать кластер в соответствии с нагрузкой. Настройка AirFlow на уровне среды Как мы уже отмечали, Apache AirFlow отлично масштабируется, обеспечивая высокую производительность...
Как отметки времени о событиях в архитектуре данных Lakehouse позволяют обеспечить безопасность Delta Lake: примеры извлечения и преобразования, а также лучшие практики. Почему отметки времени в логах системных событий так важны для архитектуры больших данных Архитектура Lakehouse построена на открытых стандартах и API, которые позволяют сочетать ACID-транзакции и управление данными...

Как управлять средой PySpark-приложения в распределенной вычислительной среде: проблемы зависимостей Python в кластере и способы их решения с помощью сеансов Spark Connect в версии 3.5.0. Управление зависимостями в Python и PySpark Каждый Python-разработчик хотя бы раз сталкивался с проблемой несовместимости пакетов. Эта ситуация называется ад зависимостей (dependency hell), когда вновь...