Недавно мы писали про устранение серьезной уязвимости PostgreSQL в свежем выпуске Greenplum 6.21.1. Продолжая тему cybersecurity, сегодня разберем другие значимые угрозы, которые были устранены в этой MPP-СУБД в 2022 и 2021 годах. Угрозы безопасности Greenplum и PostgreSQL Будучи основанной на объектно-реляционной СУБД PostgreSQL, что мы разбирали здесь, Greenplum подвержен многим...

Для практического обучения дата-инженеров и архитекторов Big Data систем сегодня рассмотрим трудности изоляции и распределения в кластере Apache HBase и способы их обхода. С какими проблемами изоляции и сбалансированного распространения данных столкнулись инженеры индийской e-commerce компании Flipkart при организации мультиарендного кластера Apache HBase и как их решили. Изоляция данных и...

В этой статье для обучения дата-инженеров и администраторов SQL-on-Hadoop рассмотрим способы обеспечения информационной безопасности и защиты данных от несанкционированного доступа в Apache Hive. Классический security-набор: аутентификация, авторизация и шифрование. Авторизация и аутентификация в Apache Hive Будучи популярным инструментом стека SQL-on-Hadoop, Apache Hive поддерживает все механизмы обеспечения информационной безопасности, поддерживаемый базовой...

Недавно мы рассматривали производительность ETL-конвейеров на Apache Spark с озером данных на MinIO. Сегодня разберем, чем это легковесное объектное хранилище отличается от распределенной файловой системы Apache Hadoop и как перейти на него с HDFS. Зачем переходить на MinIO Хотя HDFS до сих пор активно используется во многих Big Data проектах...

В связи с активным переходом от локальной ИТ-инфраструктуры в облачные полностью управляемые сервисы многие ИТ-архитекторы и дата-инженеры задумываются о замене собственного кластера Apache Kafka ее Cloud-альтернативами. Читайте, что общего у Apache Kafka с AWS Kinesis, чем они отличаются и какую платформу выбрать для потоковой передачи событий. Потоковая обработка событий с...

Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
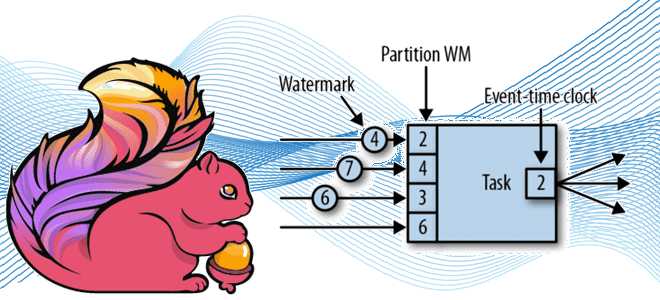
Продолжая разговор про оконные операции в Apache Flink для потоковой аналитики больших данных, сегодня рассмотрим, как это связано с другим важным концептом потоковой обработки событий – водяным знаком. Что такое Watermark и каковы стратегии его генерации в Apache Flink: самое главное для дата-инженера. Потоковая синхронизация данных c SQL для Flink...
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем особенности работы оператора MERGE во встроенном SQL-подобном языке запросов Cypher популярной NoSQL-СУБД Neo4j. Чем он отличается от запросов CREATE и MATCH, а также когда этот оператор более всего полезен. Как работает MERGE-запрос в Neo4j Data Scientist’ы и аналитики данных знают,...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...
Продолжая разбираться с популярными MLOps-инструментами, сегодня рассмотрим, как MLflow реализует управление версиями модели и данных, а также чем это отличается от DVC. Преимущества и недостатки популярных MLOps-инструментов с возможностями их совместного использования. Плюсы и минусы MLflow для MLOps-инженера Концепция MLOps, направленная на сокращение разрыва между различными специалистами, участвующими в процессах...