
Поскольку Apache NiFi является распределенной системой стека Big Data, для него очень значимы вопросы балансировки нагрузки. Поэтому сегодня разберем важную для обучения дата-инженеров и администраторов кластера NiFi тему по балансировке нагрузки и распространению данных в этом потоковом ETL-фреймворке. Как происходит балансировка нагрузки в кластере Apache NiFi До версии 1.8 в...
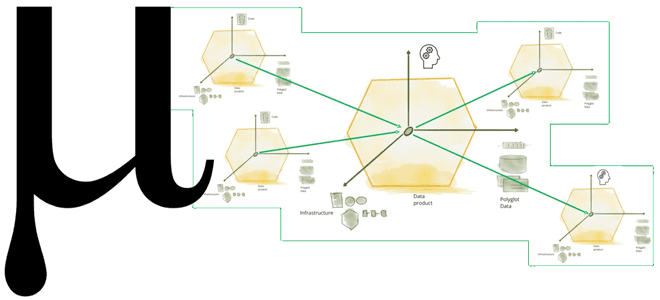
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...
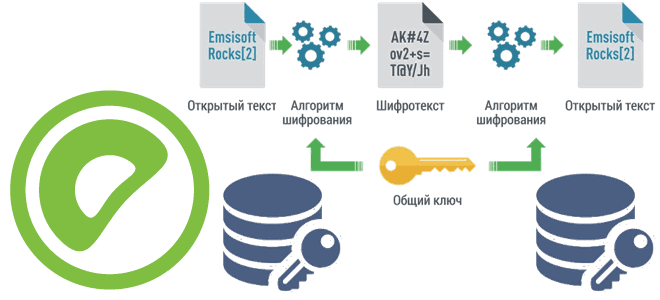
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...
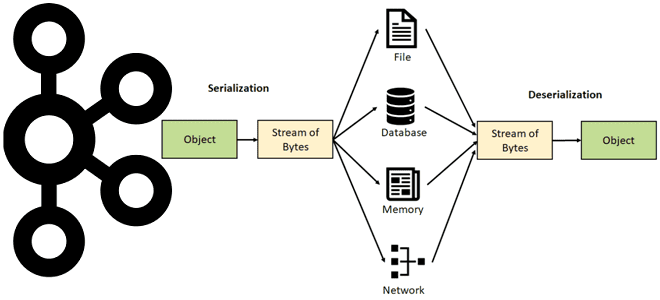
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...