 634
634 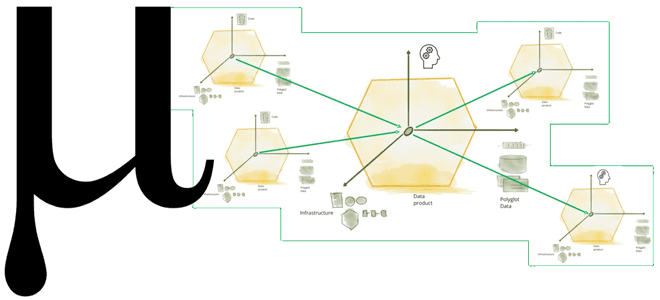
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь машинное обучение.
От линейных конвейеров к распределенной сетке данных
Сетка данных (Data Mesh) – одна из современных децентрализованных дата-архитектур, цель которой создать основу для получения ценности от аналитических данных и исторических фактов в масштабе. Масштабирование применяется к постоянному изменению ландшафта данных, распространению источников и потребителей данных, разнообразию преобразования и обработки, которые требуются в разных сценариях использования с различной скоростью изменений.
Этот децентрализованный социотехнический подход к обмену, доступу и управлению аналитическими данными в сложных и крупномасштабных средах отлично подходит для внутрикорпоративного применения, а также может стать основой интеграции данных между разными организациями. Data Mesh лежит в основе нового архитектурного подхода, направленного на работу с пассивными запросами и активными данными. Хотя эту идею уже давно использует потоковая парадигма обработки данных, в μ-архитектуре она приобретает еще более выраженный характер. В традиционной пакетной парадигме данные пассивно ждут, пока приложение или пользователь отправит запросы, на которые будет получен ответ. В потоковой обработке это происходит наоборот: данные представляют собой непрерывный активный поток событий, направляемый на пассивные запросы, которые просто реагируют и обрабатывают этот поток.
Таким образом, в классической пакетной парадигме работа сводится к тому, чтобы написать запрос, который подходит для приложения или API, поскольку типичная архитектура корпоративных данных состоит из набора приложений, производящих данные, с их локальными моделями или хранилищами и некоторым централизованным DWH. Локальная модель данных здесь в основном предназначена для обслуживания OLTP-процессов, а DWH — единственный источник истины. Поэтому в традиционной парадигме нужно написать запрос так, чтобы он возвращал результат, ожидаемый пользователем. Но потоковая передача данных, облачные и бессерверные вычисления позволяет обеспечивать непрерывный поток данных, чтобы они были практически везде, почти в одно и то же время. Поэтому следует сконцентрироваться на данных как на динамической среде, а не на статическом объекте для анализа.
Таким образом, данные становятся транзитивными, перемещаясь во время запроса. Это обуславливает две проблемы потоковой парадигмы:
- часть данных передается из удаленного источника как часть запроса, что типично для интеграционных платформ, таких как ESB;
- часть данных находится «в пути» во время выполнения запроса, например, запрос работает с базой, где еще нет ценных данных, что характерно для DWH.
Чтобы решить эти проблемы, в архитектуре и инженерии данных возник переход от линейной модели конвейерной обработке к распределенной топологии. Изначально линейный конвейер был преобладающим паттерном, основанный на транспортировке данных из точки А в точку Б. Большую часть времени обе этих точки, А и Б, являются конечными состояниями: А – это источник происхождения данных, а Б — место назначения, где производится некая ценность: визуализация, вычисление и пр.
Однако, линейная модель конвейеров, предполагающая взаимосвязь всех систем друг с другом усложняла внесение изменений, а также сотрудничество между разными командами.
Мю-архитектура и Data Mesh
Поэтому на смену конвейерной модели пришла сетка данных (Data Mesh), которая предполагает совместную работу в распределенной топологии вместо создания очередного конвейера. Взаимосвязь систем не такая прямолинейная, как при традиционной конвейерной обработке. Даже если речь не идет про вычисления в реальном времени, потоковая передача данных позволяет обрабатывать данные непрерывно, а не в отдельных временных окнах, например, ночные пакеты в DWH. Этот подход фактически упрощает обработку, т.к. не требуется точной подстройки временных окон между собой. Также снижается потребность в высоких вычислительных мощностях из-за снижения объема обрабатываемых данных. Кроме того, результаты становятся более точными, т.к. расхождения, вызванные временными задержками, сведены к минимуму.
В итоге Data Mesh становится основой для новой архитектуры данных, называемой μ (Мю). Мю-модель — это рекурсивно повторяющийся шаблон микропроцессоров данных, состоящий из триплетов соединения μ-продуктов: источника, процессора и приемника данных. Эти μ-продукты создают сетку, через которую проходят данные, трансформируясь в рамках потоков. Этот шаблон позволяет распределить сложность обработки данных по сетке за счет их распределения и масштабируемости. Фактически, Data Mesh становится способом перейти от ETL-конвейеров к µ-архитектуре через лямбда и каппа-модели. О том, что они собой представляют, мы писали здесь и здесь.
Идея μ-продукта приводит к инициативам по устранению технологической неоднородности отдельных технологий, чтобы построить базовую сетку данных. Сегодня для этого отлично подходят платформы потоковой передачи событий, такие как Apache Kafka. Таким образом, архитектура Мю позволяет создавать продукты данных как представление топологии.
Примечательно, что принцип работы µ-архитектуры похож на топологию нейросети. Поэтому можно применить основные идеи машинного обучения к этой архитектуре данных. Например, создается поток данных, из которого извлекаются фичи путем их публикации в новом топике Kafka, чтобы затем обогатить их другими данными и метаданными. Такая архитектура сочетает в себе сложность потока и высокие требования к производительности системы. Лучше всего для реализации этого подходит облачная среда.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

