Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения.
Сериализация и десериализация данных в Apache Kafka
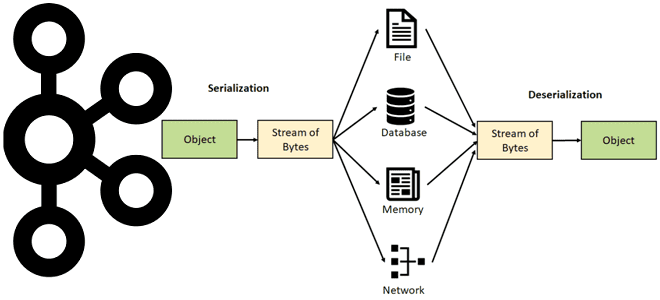
Выполняя роль интеграционной платформы, Apache Kafka может принимать сообщения от приложений-продюсеров в разных форматах: JSON, AVRO, Protobuf, о чем мы рассказывали здесь. Эти сообщения считывают приложения-потребители, причем некоторым из них необходимо считывать данные разнородных форматов из топиков Kafka, попутно выполняя преобразования или валидацию. Однако, в каждый топик поддерживает свой формат сообщений, хотя фактически в Kafka все данные хранятся в сериализованном виде, т.е. как набор байтов. Обратный процесс восстановления объекта из потока байтов, хранящихся в топике Kafka, называется десериализацией. Рекомендуется использовать формат сериализации с поддержкой схемы данных, которая выступает в качестве API, чтобы обеспечить взаимодействие автономных сервисов и приложения. Чтобы уменьшить потребность в специальной настройке и обеспечить устойчивость к внешним ошибкам, десериализация может быть выполнена через автоматическое определение исходного формата данных на основе первых байтов каждого сообщения.
Изначально в Kafka десериализатор схемы JSON может возвращать экземпляр определенного класса Java или экземпляр JsonNode. Если десериализатор схемы JSON не может определить конкретный тип, возвращается универсальный тип. Один из способов вернуть определенный тип — использовать явное свойство. Для десериализатора схемы JSON можно настроить свойство KafkaJsonSchemaDeseriaizerConfig.JSON_VALUE_TYPE или KafkaJsonSchemaDeserializerConfig.JSON_KEY_TYPE.
Чтобы разрешить десериализатору схемы JSON работать с топиками, где хранятся данные различных типов, необходимо предоставить дополнительную информацию для схемы. Для этого следует настроить десериализатор со значением свойства type.property, которое указывает имя свойства верхнего уровня в схеме JSON, задающее полный тип Java. Например, если type.property=javaType, схема JSON может указывать «javaType»: «org.acme.MyRecord» на верхнем уровне.
При десериализации полезной нагрузки JSON десериализатор KafkaJsonSchemaDeserializer использует указанный тип для выполнения десериализации, если задан <json.key.type> или <json.value.type>. Но эта конфигурация не будет работать для RecordNameStrategy, если в топике может существовать несколько типов сообщений JSON. В этом случае поможет настройка десериализатора type.property со значением, указывающим имя свойства верхнего уровня в схеме JSON, которое определяет полностью определенный тип Java для десериализации. Например, если <type.property>=javaType, ожидается, что схема JSON будет иметь дополнительное свойство верхнего уровня с именем javaType, указывающее полный тип Java.
Рассмотрим несколько сценариев, когда приложениям-потребителям необходимо десериализовать сообщения из Kafka в JSON-формат:
- пересылка данных в Kafka из внешнего источника;
- отправка данных в место назначения, которое ожидает сообщения JSON, например, веб-сервис с REST или GraphQL API или другой топик Kafka, определенный для хранения данных JSON;
- при применении правил и валидации JSON для измерения качества данных.
В этих случаях нужно настроить десериализаторы для приложений-потребителей, например, чтобы преобразовать данные из AVRO в JSON, когда изначально топик предназначен для AVRO, или строку в формате JSON.
JSON использует человеко-читаемый синтаксис, в отличие от бинарного формата Apache AVRO. В частности, JSON-сообщение всегда начинается с фигурной скобки { и заканчивается ей же }. Аналогичным образом в JSON кодируется объект, а массив заключается в квадратные скобки [].
Поэтому для автоматической идентификации формата исходных данных можно разработать собственный десериализатор, который проверяет первый байт десериализованного сообщения. Например, если это квадратная или фигурная скобка, то объект представляет собой строку JSON. Если десериализатор не может определить тип, выдается ошибка десериализации.
На стороне потребителя, после получения полезной нагрузки, сперва извлекается идентификатор схемы (байты полезной нагрузки с 1 по 5), который используется для поиска/выборки схемы данных в реестр схем. Обычно клиенты кэшируют идентификатор схемы для отображения схемы при первом обращении к реестру и используют его для последующих поисков. Имея схему записи и текущую схему чтения, приложение-потребитель может десериализовать полезную нагрузку. Аналогично предыдущему шагу, вся эта оркестровка выполняется автоматически десериализаторами AVRO, Protobuf и JSON на клиентах Kafka.
Таким образом, благодаря автоматической десериализации пользователям не нужно указывать исходный формат топика и даже можно использовать разные форматы в рамках одного топика, хотя это и не рекомендуется, но фактически возможно, поскольку десериализатор работает в контексте события. Кроме того, пользователи всегда могут переопределить формат данных, выбрав правильный десериализатор. Однако, при этом возрастают накладные расходы на вычисление того, какой десериализатор следует использовать. Также снижается отказоустойчивость из-за возможности применения неправильного формата данных. Этот подход был реализован компанией Adevinta в приложениях Duratro и Pipes.
Больше подробностей про администрирование и эксплуатацию Apache Kafka в системах аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники