 1513
1513 
Содержание
Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по оценке моделей. Читайте в нашей статье, что такое матрица ошибок (confusion matrix) и как она помогает измерить эффективность используемых ML-алгоритмов и других инструментов бизнес-аналитики, оценив потенциальные убытки и выгоды от возможных сценариев будущего в задаче прогнозирования спроса.
От ритейла до банка: 5 примеров применения Big Data и Machine Learning в задачах прогнозирования спроса и предложения
Вообще сегодня задача прогнозирования спроса стала довольно обыденным приложением методов Machine Learning (ML) в реальном бизнесе. В частности, в декабре 2019 года сервис объявлений «Юла» ускорил публикацию объявлений по продаже товаров с помощью функции их распознавания по фотографии. Помимо собственно распознавания того, что сфотографировано, нейросетевые модели предлагают пользователю уточнить характеристики продукта и оценивают его стоимость в среднем по рынку. При этом пользователю выдается прогноз, насколько быстро он продаст товар при различных ценах [1].
Другой пример, московский сервис приготовления и доставки еды навынос «Кухня на районе» с помощью нейросетей и ежедневной статистики продаж рассчитывает, сколько продуктов нужно привезти на каждую точку, чтобы минимизировать количество остатков. Анализируя данные по проданным позициям в разных локациях, нейросеть из 3 500 вариантов отбирает сотню блюд, которые будут максимально востребованы, чтобы готовить именно их на районных кухнях в течение следующей недели [2].
Подобным образом, на основе постоянного анализа продаж, машинное обучение позволяет эффективно решить задачу ценообразования, установив наиболее оптимальную стоимость на отдельные продукты и целые товарные категории. Например, именно это было сделано в отечественном интернет-магазине детских игрушек Babadu.ru, когда методы Machine Learning помогли разработать несколько маркетинговых стратегий, наиболее выгодных для ритейлера [3]. Аналогично строятся ML-модели эластичного спроса в другом российском гиганте интернет-торговли, Ozon.ru. Разработанный алгоритм анализирует значения более 150 признаков в истории продаж, чтобы на выходе предоставить точный прогноз по будущим заказам. При этом в модели заложена функция минимизации денежных потерь на покупку и хранение лишних товаров на складе или отток клиента (Churn Rate) из-за отсутствия нужного продукта [4].
Похожая задача прогнозирования спроса актуальна и для банков, которые стремятся оптимизировать процессы работы с наличными деньгами в своих банкоматах. Финансовые корпорации хотят, с одной стороны, чтобы средства не лежали в банкоматах «без дела»: гораздо выгоднее, например, разместить их на краткосрочном депозите. Но, клиенты будут недовольны, когда столкнутся с отказом из-за недостаточного количества денег в банкомате. Это грозит репутационными потерями, поэтому банк стремится решить данную проблему с помощью точного предсказания спроса на наличность в каждой точке расположения банкоматов. При этом нужно учитывать, что спрос на наличные зависит от множества параметров: макроэкономические факторы, политические новости, социальные события, расположение банкомата, прогноз погоды, время года, день недели и т.д. Чтобы предсказать завтрашнюю потребность в наличных для конкретного банкомата, Сбербанк, например, с 2016 года использует адаптивные алгоритмы машинного обучения вместе с классическими методами анализа временных рядов. Такие модели обеспечивают динамическое перестроение всех анализируемых параметров, предоставляя на выходе эффективный план оптимального распределения и перемещения наличных между банкоматами [5].
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
16 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Что такое матрица ошибок и зачем она нужна: пример расчета стоимости ошибки прогнозирования
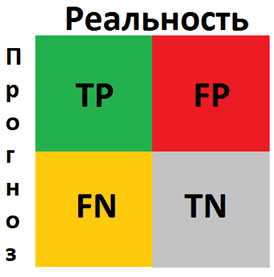
Поскольку в бизнесе поиск баланса между спросом и предложением напрямую конвертируется в деньги, возникает вопрос, насколько выгодно применение методов Machine Learning для решения этой задачи. С целью сопоставления предсказаний и реальности в Data Science используется матрица ошибок (confusion matrix) – таблица с 4 различными комбинациями прогнозируемых и фактических значений. Прогнозируемые значения описываются как положительные и отрицательные, а фактические – как истинные и ложные [6]. Вообще матрица ошибок используется для оценки точности моделей в задачах классификации. Но прогнозирование и распознавание образов можно рассматривать как частный случай этой проблемы, поэтому confusion matrix актуальна и для измерения точности предсказаний. Важно, что матрица ошибок позволяет оценить эффективность прогноза не только в качественном, но и в количественном выражении, т.е. измерить стоимость ошибки в деньгах. Например, каковы будут расходы на удержание пользователя, если машинное обучение предсказало, что он перестанет приносить компании пользу [7]? Аналогичный вопрос по предсказанию оттока (Churn Rate) актуален и в HR-сфере для удержания ключевых сотрудников, мотивация которых снижается. Впрочем, матрица ошибок может использоваться не только в рамках применения Machine Learning. По сути, этот метод оценки стоимости прогноза является универсальным аналитическим инструментом.
|
Прогноз |
Реальность |
|
|
+ |
— |
|
|
+ |
True Positive (истинно-положительное решение): прогноз совпал с реальностью, результат положительный произошел, как и было предсказано ML-моделью |
False Positive (ложноположительное решение): ошибка 1-го рода, ML-модель предсказала положительный результат, а на самом деле он отрицательный |
|
— |
False Negative (ложноотрицательное решение): ошибка 2-го рода – ML-модель предсказала отрицательный результат, но на самом деле он положительный |
True Negative (истинно-отрицательное решение): результат отрицательный, ML-прогноз совпал с реальностью |
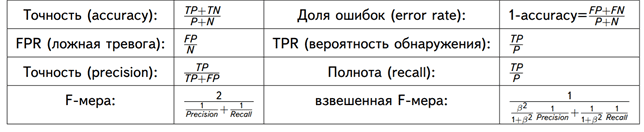
С математической точки зрения оценить точность ML-модели можно с помощью следующих метрик [8]:
- Точность – сколько всего результатов было предсказано верно;
- Доля ошибок;
- Полнота – сколько истинных результатов было предсказано верно;
- F-мера, которая позволяет сравнить 2 модели, одновременно оценив полноту и точность. Здесь используется среднее гармоническое вместо среднего арифметического, сглаживая расчеты за счет исключения экстремальных значений.
В количественном выражении это будет выглядеть так:
- P – число истинных результатов, P = TP + FN;
- N – число ложных результатов, N = TN + FP.
Рассмотрим матрицу ошибок на практическом примере для задачи прогнозирования спроса на скоропортящуюся продукцию, которая должна быть продана конечному пользователю в течение суток. Например, букеты цветов, продающиеся по цене k рублей при закупочной стоимости в p рублей. Предположим, с помощью Machine Learning было предложена 2 варианта:
- Положительный прогноз (+), что по цене k будут полностью раскуплены все цветы в количестве n букетов.
- Отрицательный прогноз (+), что по цене k будут полностью раскуплены не все цветы, останется m не проданных букетов.
Соответственно, матрица ошибок для этого случая будет выглядеть следующим образом:
|
Прогноз |
Реальность |
|
|
Проданы все букеты цветов |
Остались не проданные m букетов |
|
|
+: Проданы все n букетов по k рублей c ценой закупки p |
True Positive: прогноз совпал с реальностью, все закупленные n букетов проданы
Выручка = n*k Затраты = n*p Прибыль = n*(k-p) Стоимость ошибки = 0 |
False Positive: ошибка 1-го рода, ML-модель предсказала, что будет n продаж, а на самом деле их было (n-m), осталось m не проданных букетов, которые пропали и не вернули затраты на их покупку
Выручка = (n-m)*k Затраты = n*p Прибыль = n*(k-p) – m*k Стоимость ошибки = m*p |
|
—: Остались не проданные m букетов c ценой закупки p |
False Negative: ошибка 2-го рода – ML-модель предсказала, что n букетов не будет продано, поэтому закупили (n-m) букетов, но спрос был на n букетов. Эффект недополученной прибыли
Выручка = (n-m)*k Затраты = (n-m)*p Прибыль = (n-m)*(k-p) Стоимость ошибки = m*k |
True Negative: ML-прогноз совпал с реальностью, было раскуплено (n-m) букетов по цене k, сколько и было изначально закуплено по цене p
Выручка = (n-m)*k Затраты = (n-m)*p Прибыль = (n-m)*(k-p) Стоимость ошибки = 0 |
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Таким образом, с помощью confusion matrix можно измерить эффективность прогноза в денежном выражении, что весьма актуально для практического бизнес-приложения Machine Learning. Впрочем, отметим еще раз, что данный метод предварительной оценки будущих сценариев можно использовать и вне сферы Data Science, оценивая риски и перспективы в рамках классического бизнес-анализа.

Другие практические вопросы системного и бизнес-анализа рассматриваются в рамках нашей Школы прикладного бизнес-анализа. А особенности практического применения больших данных и машинного обучения разбираются на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://www.the-village.ru/village/city/news-city/371179-tseny
- https://www.the-village.ru/village/business/businessmen/371631-kuhnya-na-rayone
- https://chernobrovov.ru/articles/kak-mashinnoe-obuchenie-pomogaet-pravilno-ustanavlivat-pravilnye-ceny/
- https://habr.com/ru/company/ozontech/blog/431950/
- http://futurebanking.ru/post/3213
- https://hranalytic.ru/kak-ponyat-matrica-nesootvetstvij-confusion-matrix/
- https://chernobrovov.ru/articles/kak-izmerit-effektivnost-machine-learning-schitaem-metriki-i-dengi-na-primere-prognozirovaniya-ottoka-polzovatelej/
- http://www.machinelearning.ru/wiki/images/archive/5/54/20151001162720!Kitov-ML-05-Model_evaluation.pdf

