
Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...

Рассматривать обучение Кафка интереснее на практических примерах. Сегодня мы расскажем, как Apache Kafka применяется в одной из крупнейших промышленных компаний России - ПАО «Северсталь». Эта статья написана на основе выступления Доната Фетисова, главного архитектора «Северсталь Диджитал». Доклад был представлен 7 декабря 2019 года на очередном ИТ-митапе компании Авито по Big...

Вчера мы рассказывали, от чего зависит скорость работы Apache Kafka и как можно повысить. Сегодня рассмотрим подробнее, как именно конфигурация отправителей (производителей, producers) сообщений влияет на общую производительность этой распределенной Big Data системы потоковой агрегации событий. Что такое конфигурация производителей Apache Kafka Напомним, общая производительность Кафка зависит от следующих факторов:...

Продолжая практическое обучение Kafka, сейчас мы рассмотрим, от чего зависит производительность этой распределенной Big Data системы потоковой агрегации событий. Частично эту тему мы уже рассматривали в статье про применение Кафка в высоконагруженных проектах. Читайте в сегодняшнем материале, какие параметры влияют на скорость работы Кафка и как можно ее повысить. Как...
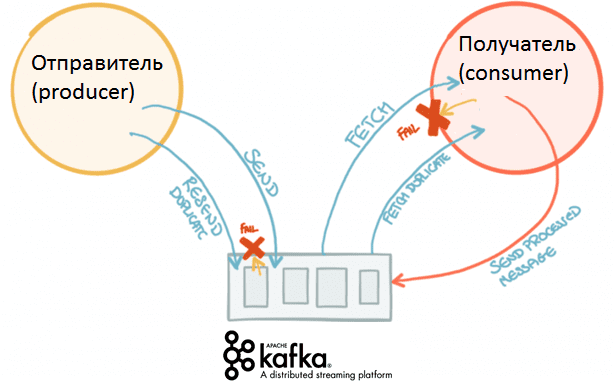
Вчера мы говорили про концепцию QaaS, очереди сообщений в Apache Kafka и другие проблемы производительности высоконагруженных систем с использованием этой Big Data платформы. Сегодня рассмотрим сложности многопоточной обработки событий в разном порядке: когда возникают подобные ситуации и как их решить. Для этого еще раз сравним Кафку с ее вечным конкурентом,...

При всех достоинствах Apache Kafka, для этого популярного Big Data средства управления сообщениями характерны определенные трудности в обеспечении производительности. Сегодня мы поговорим про некоторые проблемы использования этого распределенного брокера сообщений в высоконагруженных системах. В качестве реального примера рассмотрим особенности практического использования Кафка в отечественном сервисе объявлений Авито. Что такое высоконагруженная...
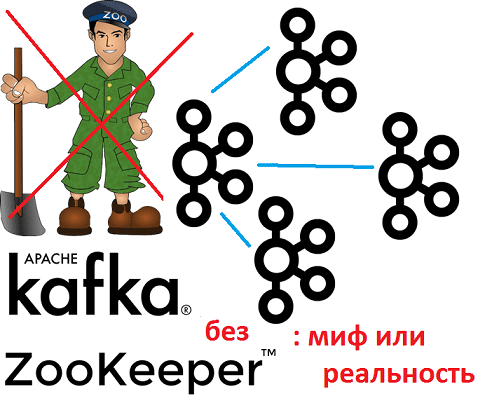
Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...
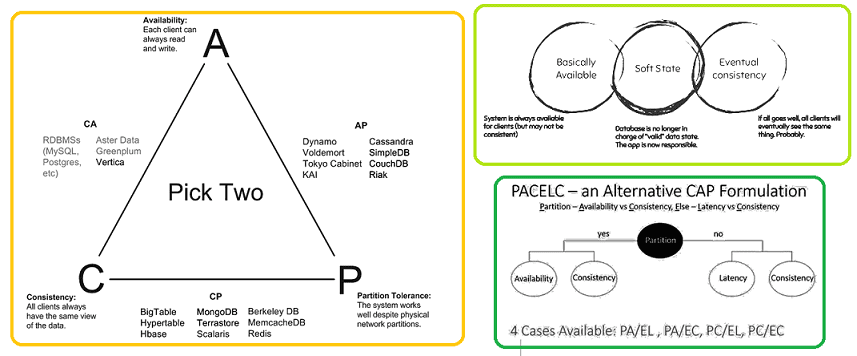
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...