 1100
1100 
Содержание
Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств.
Что общего между Apache Cassandra и HBase: 5 главных сходств
Прежде всего отметим, чем похожи HBase и Кассандра. Проанализировав главные достоинства и недостатки этих нереляционных СУБД, мы выделили следующие их общие качества:
- История разработки – обе рассматриваемые СУБД написаны на языке программирования Java примерно в одно время: Cassandra создана в 2008 в Facebook, а HBase – в 2007 в Powerset. Проектами верхнего уровня Apache Software Foundation эти продукты стали в 2009 и 2010 гг. соответственно.
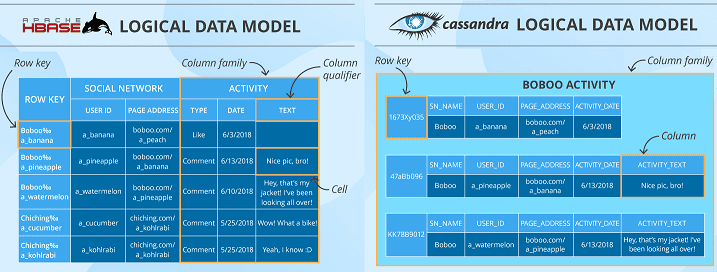
- Модель данных – обе системы основаны на концепциях Google Big Table и являются колоночно-ориентированными хранилищами, где информация хранится хранятся в ячейках, сгруппированных в столбцы, а не в строки данных [1]. При этом сами столбцы (колонки) группируются в семейства (Column Family), а в общем хранилища относятся к типу «ключ-значение» (key-value). Несмотря на общие термины, их реализация в рассматриваемых системах немного отличается: столбец Кассандры больше похож на ячейку в HBase, а семейство столбцов – на таблицу соответственно. Также в модели данных Cassandra реализуется понятие «пространство ключей» (keyspace), чего нет в другой СУБД. В свою очередь, в HBase есть концепция региона — диапазона записей, соответствующих определенному диапазону подряд идущих первичных ключей, что позволяет балансировать размером таблицы и распределением по узлам кластера. Однако, обе модели являются гибкими, поддерживают маркирование данных метками времени (timestamp) и отлично подходят для хранения больших объемов разреженных данных, допуская отсутствующие значения в определенной ячейке или столбце и не занимая при этом места для хранения. В обоих случаях необходимо указывать семейства столбцов при разработке схемы данных, которая потом не изменяется, тогда как в определении столбцов допустима гибкость в любое время [2].
- Высокая скорость работы – при том, что обе СУБД работают быстро, практически в режиме реального времени, в плане производительности операций чтения и записи они отличаются. В частности, благодаря своим архитектурным особенностям, о которых мы рассказывали здесь, Кассандра работает быстрее своего конкурента [3]. Однако, в случае произвольного доступа к данным в виде множества согласованных операций чтения HBase может работать эффективнее Cassandra благодаря блочному кэшу HDFS, Bloom-фильтрам и собственной системе индексов [2].
- Информационная безопасность – обе базы данных поддерживают аутентификацию, авторизацию и шифрование между узлами, обеспечивая не только общее управление доступом, но и детализацию на уровне отдельных элементов модели данных. В частности, Cassandra обеспечивает доступ на уровне строк, а HBase – даже на уровне отдельных ячеек. При этом Кассандра позволяет определять роли пользователей, устанавливая для них условия видимости данных. В HBase, наоборот, администратор назначают метку видимости для наборов данных, в последствие распространяя их на группы пользователей и отдельных клиентов [2].
- Масштабируемость и отказоустойчивость – HBase и Cassandra линейно масштабируются, позволяя добавлять новые серверы и наращивать таким образом кластеры до сотни узлов. При этом обе системы гарантируют сохранность информации, даже при сбое отдельных узлов за счет репликации данных [4].
Чем Apache HBase отличается от Кассандры: 5 ключевых различий
При всех вышеотмеченных сходствах, HBase и Cassandra существенно отличаются друг от друга по следующим характеристикам:
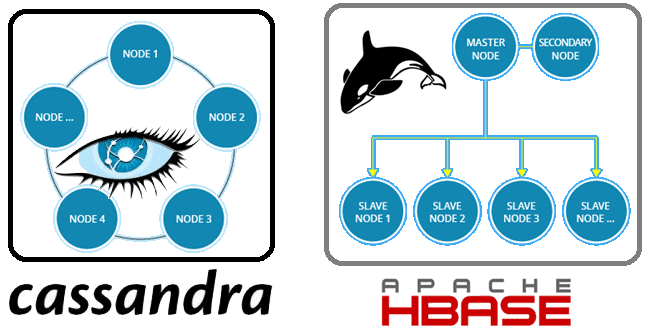
- Архитектура – кластер HBase работает по принципу ведущий/ведомый (master/slave), когда главный сервер (Master Node) управляет остальными узлами. Поэтому отказ главного сервера влечет за собой сбой всего кластера. Этого недостатка лишена Apache Cassandra, организованная в виде кольца равнозначных узлов, по которым распределены данные. Побочным эффектом такой отказоустойчивости Кассандры является проблема согласованности данных, когда одна и та же информация на разных узлах может отличаться. Для борьбы с этим в Cassandra предусмотрены настраиваемые уровни согласованности (consistency levels), о которых мы подробно рассказывали здесь. В HBase целостность данных обеспечивает центральный сервер (Master Node), который, как мы уже отметили, отвечает за распределение данных по остальным узлам, и сам является потенциальной точкой глобального сбоя.
- Инфраструктура – Кассандра самодостаточна, т.е. она не нуждается в дополнительных файловых хранилищах и других внешних компонентах, обеспечивая как управление, так и хранение данных. Взаимодействие между узлами кластера происходит по одноранговому Gossip-протоколу [5]. А для работы HBase необходимы компоненты Apache Hadoop: распределенная файловая система HDFS для хранения данных и служба Zookeeper для координации работ между сервисами, управления их конфигурациями и синхронизацией.
- Средства работы с данными – HBase предоставляет разработчику Big Data более широкий набор возможностей: REST и другие API-интерфейсы Java, а также внешние SQL-решений (Apache Phoenix, Drill, Hive и Cloudera Impala), позволяющие работать с данными, хранящимися в HBase, как с реляционными таблицами. Сама СУБД поддерживает только 4 основные действия по обработки данных, которые отличаются от классических SQL-запросов (put, get, scan, delete). В свою очередь, Cassandra имеет собственный SQL-подобный язык запросов (CQL, Cassandra Query Language), позволяющий выполнять простейшие выборки (SELECT) по определённому условию. Оператор UPDATE обеспечивает добавление и обновление информации, а INSERT отсутствует. Также CQL поддерживает пространство имён и семейств столбцов. Драйверы с поддержкой CQL реализованы для языков Python, Java, Ruby, PHP, JavaScript и Perl [6].
- Поддержка индексации – Cassandra поддерживает вторичные индексы, создать которые можно с помощью CQL-выражения CREATE INDEX [6]. В HBase индексация возможна только по одному полю – первичному ключу (Row Key). Добавить вторичный индекс можно с помощью Apache Phoenix, который компилирует SQL-запросы в собственные API-интерфейсы NoSQL без использования MapReduce [7].
- ACID-транзакции – из-за ограничений, выраженных в CAP-теореме [8], принято считать, что распределенные NoSQL-СУБД, в отличие от реляционных баз данных, не могут обеспечить все ACID-требования к транзакциям (атомарность, согласованность, изолированность, долговечность) [9]. В частности, Apache HBase прямо сообщает об этом [10]. Однако, Cassandra обеспечивает ACID-транзакции на уровне одной записи, т.е. для набора столбцов с одним ключом [11]. Подробнее про ограничения CAP-теоремы, критику этой концепции и альтернативные подходы к проектированию распределенных систем мы писали здесь.
Таким образом, Apache Cassandra и HBase сложно назвать прямыми конкурентами или равнозначными альтернативами, поскольку они слишком отличаются по множеству параметров даже в общих свойствах. В следующей статье мы рассмотрим, в каких случаях следует выбирать HBase, а когда при построении Big Data системы с использованием NoSQL-СУБД стоит использовать Кассандру и почему.
Все тонкости установки, настройки, администрирования и эксплуатации нереляционных баз данных разбираются на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://www.3pillarglobal.com/insights/exploring-the-different-types-of-nosql-databases
- https://www.scnsoft.com/blog/cassandra-vs-hbase
- https://www.datastax.com/products/compare/nosql-performance-benchmarks
- https://en.wikipedia.org/wiki/Gossip_protocol
- https://ru.wikipedia.org/wiki/Apache_Cassandra
- https://ru.bmstu.wiki/Apache_Phoenix
- https://ru.wikipedia.org/wiki/Теорема_CAP
- https://habr.com/ru/post/228327/
- https://hbase.apache.org/acid-semantics/
- https://ru.bmstu.wiki/Apache_Cassandra

