 1334
1334 
Содержание
Продолжая практическое обучение Kafka, сейчас мы рассмотрим, от чего зависит производительность этой распределенной Big Data системы потоковой агрегации событий. Частично эту тему мы уже рассматривали в статье про применение Кафка в высоконагруженных проектах. Читайте в сегодняшнем материале, какие параметры влияют на скорость работы Кафка и как можно ее повысить.
Как работает Apache Kafka: потоковая агрегация сообщений в Big Data
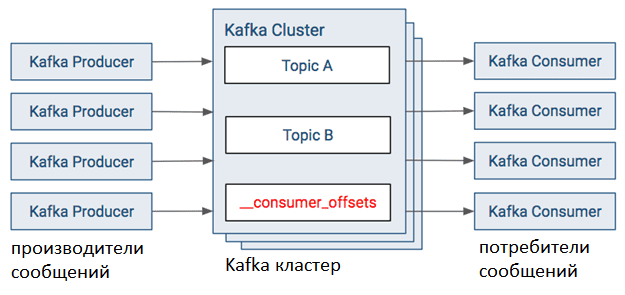
Прежде чем говорить про производительность Кафка, напомним, как работает эта Big Data система. Очень кратко работу Apache Kafka можно описать следующим образом [1]:
- приложение-издатель (производитель, producer) отправляет сообщение в топик (topic) Кафка. При этом данные могут быть сжаты с помощью кодеков, например, gzip или snappy.
- Kafka объединяет сообщения в группу (пакет) для хранения в одном разделе (partition) топика;
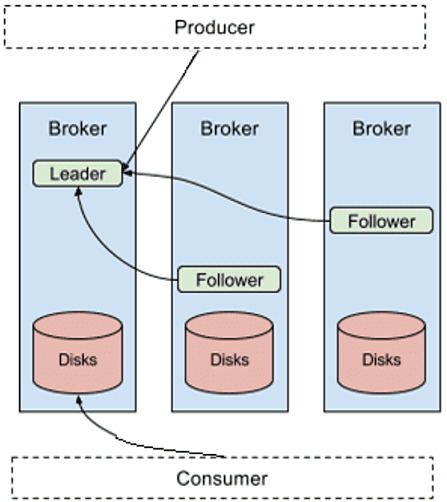
- Данные записываются на диск, каждый producer пишет в свой раздел реплицированного журнала. После первой записи (лидере, leader) данные реплицируются по всему кластеру, распространяясь по подписчикам (followers).
- В зависимости от значения параметра конфигурации acks, producer получает подтверждение об успешной записи. Например, при acks=-1 (или all), производитель ждет подтверждения о записи на диск с каждого узла. Подробнее про acknowledge мы рассказывали здесь.
- Приложения-потребители (consumers) считывают сообщения из разделов по принципу «1 потребитель на 1 раздел).
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
От чего зависит производительность Кафка: 7 ключевых факторов
Напомним, производительность системы измеряется ее пропускной способностью и временной задержкой на выполнение операций. Таким образом, производительность Apache Kafka зависит от следующих факторов:
- Размер сообщения, который можно огранить с помощью параметра message.max.bytes. По умолчанию его значение равно 1 Мбайт. При отправке сообщения большего размера, производитель получит от брокера Кафка уведомление об ошибке, а само сообщение не будет принято к записи. Поэтому большие по размеру сообщения целесообразно сжимать с помощью кодеков [2]. Cжатие увеличит количество записей, которые могут храниться на диске. Но это усилит нагрузку на ЦП при разных форматах сжатия у producer’а и брокера Кафка, т.к. данные должны быть сжаты перед отправкой, а затем распакованы перед обработкой [1]. Кроме того, увеличение параметра message.max.bytes может снизить производительность Kafka, поскольку увеличится время сетевых соединений на передачу большого сообщения и обработку запросов. Также увеличенный объем записываемых на диск данных снижает пропускную способность операций ввода/вывода [2].
- пропускная способность дисков на машинах кластера Kafka – поскольку сообщения записываются на диск, скорость выполнения операций каждого узла кластера влияет на общую производительность всей Big Data системы. У жестких дисков с раскручивающимися пластинами (HDD) высокая экономичность и емкость, но операции поиска и доступа к данным занимают больше времени, чем у твердотельных накопителей (SSD). Производительность HDD можно повысить путем увеличения их числа в брокере Кафка или с помощью нескольких каталогов данных. Пропускная способность диска также зависит от технологии его изготовления (SAS или SATA) и характеристик его контроллера [2]. Кроме того, стоит помнить, что Kafka сохраняет каждый новый раздел на диске с минимальным количеством существующих partition’ов. Это делается, чтобы сбалансировать разделы по доступным дискам. Но при обработке множества partition-реплик на каждом жестком диске, его пропускная способность снижается. Чтобы снизить влияние этого фактора, можно использовать более управляемые диски на каждый брокер Kafka. Однако, это значительно повышает общую стоимость всей Big Data системы [1].
- память, как общий объем оперативной памяти каждого узла кластера, так и размер кэша. Чтение из страничного кэша выполняется быстрее, чем с диска. Поэтому, чем больше оперативной памяти доступно для страничного кэша, тем быстрее будут работать клиенты-потребители. При том, что для самой JVM Kafka не нужен большой объем оперативной памяти. Поэтому не стоит использовать Kafka в системе, где уже работают другие важные приложения, чтобы не делить страничный кэш и не снижать производительность потребителей Кафка [2].
- пропускная способность сети определяет максимальный объем трафика, который может обработать Kafka. При этом следует учитывать дисбаланс между входящим и исходящим сетевым трафиком. В частности, producer может генерировать 1 Мбайт сообщений в секунду для одного топика, но количество потребителей может быть любым [2]. Кроме того, репликация данных по узлам кластера и параметр конфигурации каждого производителя acknowledge также влияют на сетевую нагрузку [1].
- вычислительная мощность узла имеет значение для операций сжатия и разархивирования сообщений. Например, брокер Kafka распаковывает все пакеты сообщений для проверки контрольных сумм отдельных записей и назначения смещений (offset). При сохранении данных на диск выполняется обратная операция, когда пакет сообщений сжимается. Именно таким образом чаще всего Kafka использует вычислительные мощности CPU. Впрочем, это не самый главный фактор при выборе аппаратного обеспечения кластера [2].
- плотность разделов на каждом брокере Кафка влияет на время выполнения операций с метаданными, а также на обмен данными между лидером раздела и его подписчиками. Репликация данных приводит к дополнительной обработке запросов отправки (send) и получения (receive), увеличивая нагрузку на сеть. В частности, для Apache Kafka версии 1.1 и выше рекомендуется не более 1000 разделов на брокер, включая реплики. Увеличение этой плотности снижает пропускную способность и может привести к недоступности раздела [1].
- коэффициент репликации – чем больше реплик, тем более надежно Big Data система гарантирует сохранность данных. Но это потребляет больше места на диске и увеличивает загрузку CPU для обработки дополнительных запросов, увеличивая задержку записи и уменьшая пропускную способность [1].
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
13 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Кроме того, на общую производительность Big Data системы на базе Apache Kafka влияет конфигурация производителей [3]. Об этом мы поговорим в следующей статье. Другие подробности, как ускорить работу кластера Apache Kafka и распределенных приложений потоковой обработки событий вы узнаете, пройдя обучение Кафка на специализированных практических курсах в «Школе Больших Данных» — лицензированном учебном центре для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://docs.microsoft.com/ru-ru/azure/hdinsight/kafka/apache-kafka-performance-tuning
- Книга «Apache Kafka. Потоковая обработка и анализ данных» (Kafka: The Definitive Guide). Ния Нархид, Гвен Шапира, Тодд Палино – Питер, 2019 https://pcnews.ru/top/blog/mat-header-panel/kniga_apache_kafka_potokovaa_obrabotka_i_analiz_dannyh-847758/
- https://habr.com/ru/company/tinkoff/blog/342892/

