 1001
1001 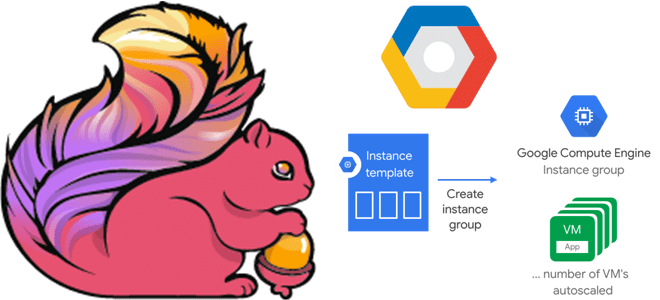
Содержание
В этой статье для дата-инженеров и разработчиков Flink-приложений рассмотрим, как связаны диспетчеры задач и заданий, зачем настраивать автоматическое масштабирование кластера и как это сделать с помощью Google Auto Scaler в облачной инфраструктуре этого провайдера.
Роль диспетчера заданий в Apache Flink и механизмы отказоустойчивости
Apache Flink — отличный фреймворк создания приложений потоковой обработки больших данных. Он предоставляет широкий спектр вариантов использования, имеет множество полезных библиотек и активное сообщество, которое развивает его.
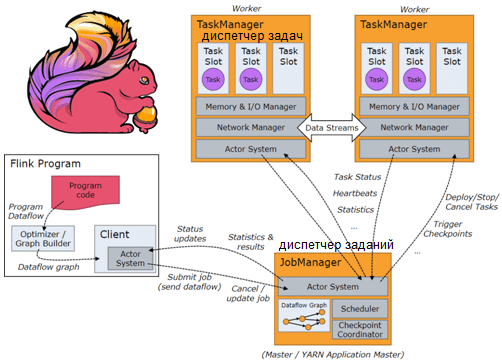
Потоковые Flink-приложения ежедневно могут обрабатывать миллионы сообщений в реальном времени, будучи развернуты в кластере, где работают один или несколько диспетчеров заданий и задач. Диспетчеры заданий получают запросы на отправку приложений для запуска в кластере и планируют их выполнение в диспетчерах задач – worker’ах, которые фактически запускают приложения.
Потенциально можно запустить сколько угодно Flink-приложений в одном кластере, если в нем достаточно диспетчеров задач. Но на практике лучше иметь столько кластеров Flink, сколько запущенных приложений. Это позволяет адаптировать ресурсы в каждом кластере к потребностям приложения, работающего на нем, а также изолировать приложения друг от друга, чтобы избежать ошибок в одном задании, влияющих на другие приложения. Это может случиться, когда отправка нового приложения диспетчеру заданий приводит к неожиданному сбою процесса диспетчера заданий. Если все Flink-приложения работают в одном кластере, они полагаются на один и тот же диспетчер заданий, поэтому могут неожиданно остановиться. Предупредить это может настройка высокой доступности с Zookeeper для диспетчеров заданий, но это не всегда возможно.
Поэтому рекомендуется регулярно создавать точки сохранения Flink-приложений, используя механизм контрольных точек (checkpoint). Контрольные точки — это резервные копии состояния приложения в определенный момент времени. Это обязательно для stateful-приложений, а также рекомендуется для приложений с состояниями, которые нельзя потерять в случае сбоя или другой остановке. Следующий пример кода показывает создание контрольных точек в коде Flink-приложения:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Enables checkpoints env.enableCheckpointing(conf.getCheckpointsFreqMs()); env.getCheckpointConfig().setCheckpointTimeout(conf.getCheckpointsTimeoutMs()); env.getCheckpointConfig().setMaxConcurrentCheckpoints(conf.getMaxConcurrentCheckpoints()); env.getCheckpointConfig().setTolerableCheckpointFailureNumber(conf.getTolerableCheckpointFailures()); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(conf.getCheckpointsMinPauseTimeMs());
Контрольные точки хороши тем, что с них можно перезапустить приложение в случае неожиданного сбоя. Но у этого механизма есть некоторые ограничения, которые могут не позволить перезапустить приложение с нужного момента. Поэтому Apache Flink предоставляет еще один тип контрольных точек, называемых точками сохранения, которые должны запускаться извне, т.е. за рамками кода приложения. Этот механизм работает почти всегда, поэтому рекомендуется для приложений с высокими требованиями к доступности. Также savepoint полезен для перезапуска задания, требующего внесения изменений в код приложения. Если схема приложения изменилась, точка сохранения будет единственным способом гарантировать возможность перезапуска задания без потери состояния приложения.
Например, следующий код показывает, как настроить простое cron-задание, запускаемое каждые 15 минут в каждом из диспетчеров заданий, чтобы регулярно создавать точки сохранения Flink-приложений:
# Finds the id of the application
JOB_ID=$(/bin/flink list | grep $JOB_NAME | awk -F' ' '{print $4}')
if [ -z "${JOB_ID}" ]; then
echo "Error : empty job_id"
exit 1
fi
# Takes a savepoint of the job, and include the date in the path
/bin/flink savepoint $JOB_ID $SAVEPOINT_FOLDER/$(date '+%Y-%m-%d-%H-%M')
Это позволит избежать необходимости перезапускать stateful-приложения с состоянием старше 15 минут до потенциального сбоя. Подробнее про контрольные точки и точки сохранения в Apache Flink мы писали здесь.
Автоматизация процессов развертывания и эксплуатации
API диспетчеров заданий Flink позволяет управлять кластером, предоставляя методы, которые дают возможность получить список запущенных заданий, проверить, какие последние контрольные точки взяты отдельным заданием, взять точку сохранения выполняющегося задания, остановить работающее приложение, отправить новое приложение для запуска в кластере и другие полезные для дата-инженера функции. Все эти шаги нужны, чтобы обновить или повторно развернуть приложение Flink. Например, можно объединить эти вызовы API в простые Python-скрипты и использовать их для настройки непрерывного развертывания Flink-приложений.
Предположим, скрипт deploy_or_update_job.py переходит в диспетчер задач, останавливает запущенное приложение и берет точку сохранения (/jobs/{job_id}/stop), а также загружает заданный JAR в диспетчер заданий (/jars/upload) и запускает JAR с указанными параметрами командной строки, используя последнюю точку сохранения, взятую для этого задания (/jar/{jar_id}/run).
Можно создать Docker-образы, которые позволяют использовать эти скрипты вместе с соответствующими файлами JAR, содержащими задания Flink для запуска. Пример такого процесса непрерывного развертывания с использованием Google Cloud Build выглядит следующим образом:
# Clone the data-flink-scripts repository containing our Python scripts for Flink API
- name: 'gcr.io/cloud-builders/git'
entrypoint: 'bash'
args:
- -c
- |
eval "$(ssh-agent -s)"
ssh-add /root/.ssh/id_rsa_data_flink_scripts
git submodule update --init -- data-flink-scripts
volumes:
- name: 'ssh'
path: /root/.ssh
# Builds the Docker image packaging the job JAR file + our Python scripts
- id: 'build image'
name: 'gcr.io/cloud-builders/docker'
args: [ 'build', '-t', 'my-flink-job', '.' ]
# Uses the deploy_or_update_job.py script to actually deploy the JAR on a Flink cluster
- id: deploy
name: 'gcr.io/cloud-builders/docker'
entrypoint: 'bash'
args:
- -c
- |
docker run -e FLINK_JOBMANAGER_URL=http://10.x.x.x:8081 my-flink-job data-flink-scripts/deploy_or_update_job.py --job_name my-flink-job --parallelism 72 --config_file my-conf-file.yaml
В Apache Flink 1.13 появилась возможность автоматического масштабирования задания Flink с помощью адаптивного планировщика для увеличения или уменьшения масштаба приложения, когда объем обрабатываемых данных меняется. Flink позволяет выбирать между несколькими типами стратегий планировщика, чтобы решить, как использовать слоты, доступные в кластере. Этот адаптивный планировщик использует для автоматического масштабирования все слоты, доступные в кластере, пока не достигнут параллелизм, необходимый при запуске приложения. Он автоматически перезапустит приложение, если диспетчеры задач добавлены в кластер, чтобы использовать новые слоты, добавленные новыми worker’ами, и плавно обработает потерю диспетчера задач, просто перезапустив приложение с меньшим параллелизмом. Это достигается последовательностью действий из 4-х шагов:
- создание шаблона экземпляра для диспетчеров задач. Группа управляемых экземпляров Google – это набор идентичных компьютеров, выполняющих определенную задачу. Когда автоматическое масштабирование включено, Google может автоматически добавлять новые экземпляры в группу на основе шаблона экземпляра. В случае Flink-кластера можно основывать шаблоны экземпляров на ОС Google Container-Optimized, которые оптимизированы для запуска контейнеров Docker. Достаточно указать собственный Docker-образ Flink Task Manager (на основе официального образа Flink Docker) в качестве контейнера для запуска при создании нового экземпляра.
- далее следует создать группу экземпляров и настроить автомасштабирование, включив для нее Google Auto Scaler. При этом надо указать 4 основных параметра для тонкой настройки: минимальное и максимальное количество узлов, пороговое значение использования ЦП (среднее по всем экземплярам), которое Auto Scaler будет поддерживать, например, 70%. Также требуется задать время, необходимое для полной работы одного нового экземпляра. Этот период предотвращает слишком раннее принятие решений по автомасштабированию после добавления нового экземпляра.
- затем следует правильно настроить среду Flink, установив для планировщика заданий значение «адаптивный», и задать конфигурацию resource-wait-timeout – максимальное время, в течение которого диспетчер заданий будет ждать, пока хотя бы один worker станет доступен для планирования приложения. Это полезно на случай, если по какой-то причине группа управляемых экземпляров обнаружит, что у нее нет worker’ов. Необходимо отрегулировать продолжительность тайм-аута heartbeat-сигнала: если нужно, чтобы задание как можно быстрее реагировало на удаление диспетчера задач, когда кластер уменьшается, нужно изменить значение heartbeat.timeout в конфигурационном файле flink-conf.yaml для диспетчера заданий и диспетчеров задач). Например, значение 15 секунд достаточно велико, чтобы избежать ложных срабатываний и при этом обеспечить быстрое масштабирование приложения.
Здесь следует установить стратегию перезапуска во Flink-приложении, которая не устанавливает ограничения на максимальное количество перезапусков, Например, каждый раз, когда происходит событие масштабирования, оно считается перезапуском. Поэтому ограничений на количество перезапусков, которые диспетчер заданий может инициировать перед завершением, не должно быть. Можно использовать экспоненциальную стратегию перезапуска с задержкой или придерживаться стандартной стратегии перезапуска с фиксированной задержкой с попытками перезапуска Integer.MAX_VALUE.
jobmanager.scheduler: adaptive jobmanager.adaptive-scheduler.resource-wait-timeout: 3600 s hearbeat.timeout: 15000 restart-strategy.type: exponential-delay restart-strategy.exponential-delay.initial-backoff: 10 s restart-strategy.exponential-delay.max-backoff: 2 min restart-strategy.exponential-delay.backoff-multiplier: 2.0 restart-strategy.exponential-delay.reset-backoff-threshold: 10 min restart-strategy.exponential-delay.jitter-factor: 0.1
В среде диспетчера задач Flink необходимо установить тайм-аут heartbeat-сигнала и количество слотов для задач. Рекомендуется установить один слот для задач на каждый ЦП, доступный на компьютере. Также следует задать адрес диспетчера заданий, к которому будут обраться все диспетчеры задач в группе экземпляров приложения:
jobmanager.rpc.address: x.x.x.x hearbeat.timeout: 15000 taskmanager.numberOfTaskSlots: 2
После этого можно развернуть Flink-приложения с поддержкой автоматического масштабирования. При этом развертывании, следует установить параллелизм задания на значение выше, чем общее количество слотов, которые есть в кластере. Это позволит диспетчеру заданий запускать приложение, используя все доступные слоты. При росте нагрузки средство автоматического масштабирования Google Cloud добавляет новые диспетчеры задач в группу управляемых экземпляров, когда загрузка ЦП диспетчеров задач достигает настроенного порога. Диспетчер заданий обнаруживает, что доступны новые слоты, и может их использовать благодаря заданному высокому значению параллелизма, масштабируя задание.
При снижении нагрузки, когда загрузка ЦП слишком низкая по сравнению с настроенным порогом, этот инструмент автоматического масштабирования удаляет диспетчеры задач. Диспетчер заданий обнаруживает потерю диспетчера задач и просто перезапускает задание с меньшим параллелизмом. Таким образом, автоматическое масштабирование позволяет снизить стоимость эксплуатации без ущерба для качества, согласованности и доступности данных.
Освойте тонкости использования Apache Flink и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://medium.com/lumen-engineering-blog/our-journey-with-apache-flink-part-1-operation-and-deployment-tips-5c23e1b96bf7
- https://nightlies.apache.org/flink/flink-docs-master/docs/ops/state/checkpoints_vs_savepoints/
- https://nightlies.apache.org/flink/flink-docs-master/docs/concepts/flink-architecture/

