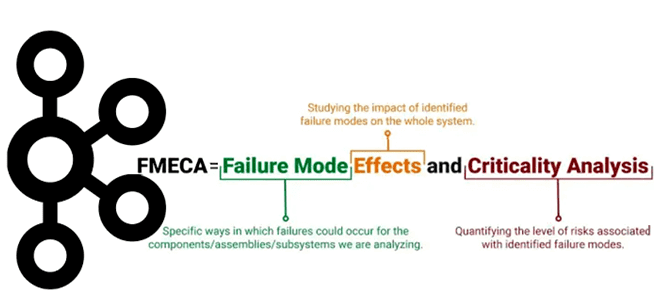
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...

Почему следует избегать PythonOperator в конвейере обработки пакетных данных на Apache Airflow и что использовать вместо этого оператора для описания задач DAG. Когда лаконичный CLI лучше наглядного GUI, где и как применять библиотеку Python Fire для оркестрации, а также планирования запуска batch-заданий. Зачем нам CLI или что не так с PythonOperator...

Запуск Apache Airflow с Kubernetes сегодня стал стандартом де-факто. Однако, при практическом развертывании Airflow с помощью исполнителя Kubernetes и оператора пода в кластере этой платформы оркестрации контейнерных приложений возникает множество препятствий и трудностей. Сегодня рассмотрим, как обойти их с помощью service-mesh проекта с открытым исходным кодом Istio, какие проблемы могут при...

Сообщество разработчиков Apache NiFi регулярно радует новыми выпусками. Не успели мы полностью освоить январский релиз 2022, в начале марта появилась еще более свежая версия этого потокового маршрутизатора. Самое главное в Apache NiFi 1.16.0 для дата-инженера и администратора кластера. Главные новинки Apache NiFi 1.16.0 Apache NiFi 1.16.0 включает несколько десятков улучшений,...

Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager. Не только AWS EMR или как следить за Spark-приложениями в...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...

Недавно мы писали про декабрьский релиз Apache NiFi. Спустя месяц, 18 января 2022 года сообщество выпустило новую версию фреймворка – 1.15.3 с аутентифицированным доступом к SFTP-серверам через прокси-серверы SOCKS и улучшенным потреблением памяти. Разбираем 9 исправленных багов и 2 улучшения, а также особенности миграции на свежий выпуск. Снова про библиотеки...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...