 1065
1065 
Содержание
Как организовать удобный мониторинг за приложениями Apache Spark в кластере Kubernetes с помощью Prometheus и Grafana: пошаговый guide для администраторов и дата-инженеров с примерами. Создаем свою альтернативу наглядным дэшбордам AWS EMR с Java-библиотекой Dropwizard Metrics и средством настройки оповещений Alertmanager.
Не только AWS EMR или как следить за Spark-приложениями в K8s
Экономическая эффективность и переносимость – основные причины переноса рабочих нагрузок Apache Spark из управляемых сервисов, таких как AWS EMR, Azure Databricks или HDInsight, в Kubernetes. Об одном из таких случаев мы недавно рассказывали на примере маркетплейса Joom. Однако, существуют и потенциальные ловушки при отказе от управляемых служб, например, потеря возможностей мониторинга и оповещения. В частности, AWS EMR имеет богатый встроенный набор инструментов для мониторинга в виде сервера истории CloudWatch, Ganglia, CloudTrail и YARN. При переводе Apache Spark на Kubernetes эти преимущества пропадают, хотя запуск рабочих нагрузок в больших масштабах остается сложной задачей. Например, исполнители могут потерпеть неудачу, задержка для внешних источников данных увеличивается, а производительность снижается из-за изменений кода или входных данных.
Поэтому необходимо активно отслеживать важные показатели Apache Spark в режиме реального времени:
- потребление ресурсов – количество ядер, процессорное время, используемая память, максимальный объем выделенной памяти, использование диска;
- количество активных, неудачных и завершенных заданий и задач, а также их максимальная, средняя и минимальная продолжительность;
- общее количество байт чтения и записи в случайном порядке для отслеживания shuffle-операций (перетасовки);
- для Spark Streaming важно количество получателей, запущенных, неудачных и завершенных пакетов, а также полученных и обработанных записей, среднее время обработки записи
- любые пользовательские метрики отдельных приложений и общие системные метрики.
Одним из самых популярных инструментов мониторинга, используемых в Kubernetes, является Prometheus – децентрализованная система с открытым исходным кодом, которая управляется сообществом и является членом Cloud Native Computing Foundation. Prometheus хранит все свои данные в виде временных рядов, которые можно запросить через PromQL и визуализировать в Grafana или встроенном браузере. Как это сделать, подробно рассмотрим далее.
4 шага по настройке мониторинга Apache Spark в Kubernetes
Сперва нужно подготовить приемник данных в Apache Spark. Во второй версии фреймворка для этого можно было использовать комбинацию встроенных JMX-расширений: JmxSink и JmxExporter. Начиная со Spark 3.0 вводится новый приемник — PrometheusServlet, который добавляет сервлет в существующий пользовательский интерфейс Spark для обслуживания данных метрик в формате Prometheus. По сравнению с JmxSink и JmxExporter, PrometheusServlet устраняет зависимости от внешнего JAR-файла и позволяет повторно использовать существующий порт, который уже использовался в Spark для мониторинга. Также возможно использовать Prometheus Service Discovery в Kubernetes.
Чтобы включить новый приемник, необходимо создать файл metrics.properties в проекте и добавить в него следующую конфигурацию:
# Example configuration for PrometheusServlet # Master metrics - http://localhost:8080/metrics/master/prometheus/ # Worker metrics - http://localhost:8081/metrics/prometheus/ # Driver metrics - http://localhost:4040/metrics/prometheus/ # Executors metrics - http://localhost:4040/metrics/executors/prometheus *.sink.prometheusServlet.class=org.apache.spark.metrics.sink.PrometheusServlet *.sink.prometheusServlet.path=/metrics/prometheus master.sink.prometheusServlet.path=/metrics/master/prometheus applications.sink.prometheusServlet.path=/metrics/applications/prometheus
Далее необходимо развернуть Spark-приложение на Kubernetes, упаковав его в Docker-образ. При этом сперва нужно скомпилировать и собрать Spark-приложение, например, написанное на Scala с помощью инструмента SBT. После окончательного развертывания Docker-образа следует скопировать файл metrics.properties в папку opt/spark/conf/.
Чтобы приложение могло сообщать о настраиваемых показателях, таких как задержка определенных методов, ключевая статистика о внутреннем состоянии, проверки работоспособности и пр. нужна возможность инструментировать код и предоставлять настраиваемые метрики в Prometheus. Это можно сделать с помощью Java-библиотеки Dropwizard Metrics, которая предоставляет мощный набор способов измерения поведения критически важных компонентов в производственной среде. Благодаря модулям для распространенных библиотек, таких как Jetty, Logback, Log4j, Apache HttpClient, Ehcache, JDBI, Jersey, и механизмам создания отчетов, таким как Graphite, Metrics обеспечивает полную видимость стека.
К примеру, рассмотрим следующую реализацию пользовательского класса метрик:
package org.apache.spark.metrics.source
import com.codahale.metrics._
object LegionMetrics {
val metrics = new LegionMetrics
}
class LegionMetrics extends Source {
override val sourceName: String = "LegionCommonSource"
override val metricRegistry: MetricRegistry = new MetricRegistry
val runTime: Histogram = metricRegistry.histogram(MetricRegistry.name("legionCommonRuntime"))
val totalEvents: Counter = metricRegistry.counter(MetricRegistry.name("legionCommonTotalEventsCount"))
val totalErrors: Counter = metricRegistry.counter(MetricRegistry.name("legionCommonTotalErrorsCount"))
}
Из любого места кода можно просто вызывать собственные метрики и обновлять счетчики, гистограммы, датчики или таймеры. Все пользовательские метрики будут отображаться автоматически с использованием протокола HTTP.
LegionMetrics.metrics.totalEvents.inc(batch.count()) LegionMetrics.metrics.runTime.update(System.currentTimeMillis - start)
После развертывания Spark-приложения можно с помощью curl перейти к модулю драйвера в кластере Kubernetes и убедиться, что все системные и пользовательские метрики отображаются корректно. Apache Spark Streaming требует дополнительной настройки в конфигурации spark.sql.streaming.metricsEnabled. Установив для этого параметра значение True, можно отследить дополнительные показатели, такие как задержка, скорость обработки, строки состояния, водяной знак времени события и пр.
Наконец, после развертывания Spark-приложения и настройки Prometheus можно перейти к работе с панелью инструментов Grafana, чтобы создать там наглядный дэшборд. На панели инструментов в Grafana следует выбрать источник данных Prometheus и ввести пользовательский PromQL-запрос. При поиске конкретных показателей стоит помнить, что PrometheusServlet следует соглашениям об именах Spark 2.x для согласованности, а не стандартам Prometheus. Выбрав нужные показатели, их можно поместить на панель управления Grafana.
Также можно использовать Prometheus Alertmanager для предупреждений о важных показателях. Alertmanager обрабатывает предупреждения, отправленные клиентскими приложениями, такими как сервер Prometheus, заботясь об их дедупликации, группировке и маршрутизации к получателю. Группировка объединяет оповещения аналогичного характера в одно уведомление, что особенно полезно во время крупных сбоев, когда сразу несколько систем выходят из строя и одновременно могут срабатывать от сотен до тысяч предупреждений. Группировка предупреждений, время для сгруппированных уведомлений и получатели этих уведомлений настраиваются с помощью дерева маршрутизации в файле конфигурации.
Также Alertmanager позволяет установить запрет на уведомления для определенных предупреждений, если другие уже активированы. К примеру, когда срабатывает оповещение о том, что весь кластер недоступен. Можно просто отключить оповещения на определенное время в веб-интерфейсе Alertmanager. Для обеспечения высокой доступности Alertmanager поддерживает настройку создания кластера с помощью флагов —cluster-*. Важно не балансировать трафик между Prometheus и его Alertmanager, а вместо этого указать Prometheus на список всех Alertmanagers.
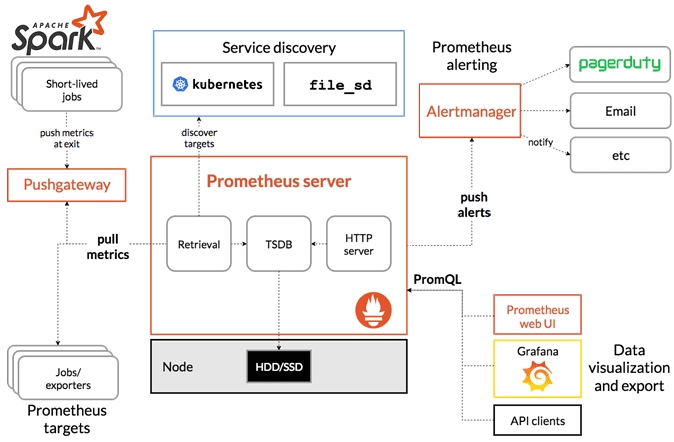
Таким образом, Alertmanager позволяет определить оповещения для таких показателей Spark, как невыполненные задания, длительные задачи, массовая перетасовка, задержка и пакетный интервал, метрики потоковой передачи и пр. Это повышает удобство экономичного и эффективного использования Apache Spark в Kubernetes. А слаженная комбинация Prometheus, Alertmanager и Grafana позволяют вывести удобство мониторинга на уровень, сравнимый с управляемыми сервисами AWS EMR.
Больше подробностей про применение Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

