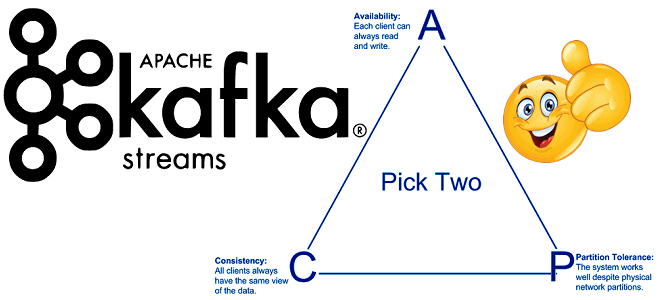
Продолжая включать интересные практические примеры в наши курсы Apache Kafka для разработчиков, сегодня поговорим о согласованности в распределенных системах с высокой доступностью. Читайте далее, что такое eventual consistency, почему это важно для микросервисной архитектуры, при чем здесь ограничения CAP-теоремы и как решить проблемы обеспечения конечной согласованности с Kafka Streams. ...

В феврале 2021 года разработчики корпоративной версии Apache Kafka с коммерческой поддержкой, компания Confluent, выпустили премиум-коннектор к Oracle – одной из главных реляционных баз данных мира enterprise. Разбираемся, кому и зачем это нужно, а также как устроена такая интеграция SQL-СУБД и потоковой аналитики Big Data с применением CDC-подхода. Реляционный монолит...

В продолжение вчерашней статьи о победителях российского ИТ-конкурса «Проект Года» от профессионального сообщества GlobalCIO в номинации «Аналитика и Big Data», сегодня мы рассмотрим корпоративную платформу управления данными ПАО «Газпром нефть», реализованную на базе продуктов отечественного разработчика Big Data решений: Arenadata Hadoop и MPP-СУБД Arenadata DB (Greenplum). Зачем ПАО «Газпром нефть»...

Мы уже рассказывали о проектах-победителях российского ИТ-конкурса «Проект Года» профессионального сообщества GlobalCIO, представивших корпоративные решения на базе продуктов Arenadata. В 2020 году клиенты Arenadata также вошли в тройку лидеров. Читайте далее, как «Газпром нефть» и ВТБ улучшили свои процессы управления данными с помощью отечественных технологий хранения и аналитики Big Data....

В этой статье по обучению дата-инженеров и разработчиков Big Data рассмотрим, как эффективно записать большие данные в СУБД PostgreSQL с применением Apache Spark. Читайте далее, чем отличается foreach() от foreachBatch(), как это связано с количеством подключений к БД, асимметрией разделов и семантикой доставки сообщений. Как Spark-приложение записывает данные в PostgreSQL...

Продолжая вчерашний разговор про Delta Lake на базе Apache Spark от Databricks, сегодня мы расскажем одну из последних новостей о запуске этого решения на Google Cloud с середины февраля 2021 года. Читайте далее, чем хороша эта проприетарная Big Data платформа для аналитики больших данных на Spark, инструментах визуализации и MLOps,...

Сегодня рассмотрим пример построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data. Читайте далее о преимуществах облачного Delta Lake от Databricks над традиционным Data Lake. Постановка задачи: финансовая...

Недавно мы уже упоминали о некоторых продуктах на базе Apache Spark. Продолжая обучение основам Big Data, сегодня рассмотрим, что такое SnappyData или TIBCO ComputeDB и как это связано с популярным фреймворком разработки распределенных приложений аналитики больших данных. Кому и зачем нужны дополнительные решения поверх Apache Spark При всей популярности Apache Spark,...

Чтобы дополнить наши курсы по Spark для разработчиков распределенных приложений и инженеров данных практическими примерами, сегодня рассмотрим кейс американской ИТ-компании ThousandEyes, которая разрабатывает программное обеспечение для анализа производительности локальных и глобальных сетей. Читайте далее, как создать надежный конвейер и устойчивое озеро данных (Data Lake) для быстрой аналитики Big Data в...

Продолжая вчерашний разговор про оптимизацию Spark-приложений в облачном кластере Amazon Web Services, сегодня рассмотрим типовую последовательность действий по конфигурированию заданий и настройке узлов для снижения затрат на аналитику больших данных. А также разберем, какие проблемы с памятью исполнителей могут при этом возникнуть, и как инженеру Big Data их решить. Еще...