 675
675 
Содержание
Недавно мы уже упоминали о некоторых продуктах на базе Apache Spark. Продолжая обучение основам Big Data, сегодня рассмотрим, что такое SnappyData или TIBCO ComputeDB и как это связано с популярным фреймворком разработки распределенных приложений аналитики больших данных.
Кому и зачем нужны дополнительные решения поверх Apache Spark
При всей популярности Apache Spark, одного этого фреймворка недостаточно для построения комплексной Big Data инфраструктуры для мощной, но простой в эксплуатации. Поэтому многие вендоры вычислительных платформ и SaaS-решений пытаются расширить его функциональные возможности и повысить удобство пользования, предлагая собственные продукты поверх Spark. Например, Delta Lake от Databricks, о котором мы рассказывали здесь и здесь. Однако, несмотря на поддержку ACID-транзакций на уровне таблицы, данную технологию нельзя назвать конечным продуктом, не требующим дополнений и предназначенным для широкого круга пользователей. Поэтому еще в 2016 году компания GemFire разработала высокопроизводительную платформу обработки данных в оперативной памяти Unified Analytics Data Fabric (UADF), которая оптимизирует Spark для молниеносной бизнес-аналитики, обработки данных и IoT-приложений. Позже UADF получила название SnappyData и в 2019 году была приобретена корпорацией TIBCO. Сегодня SnappyData также называется TIBCO ComputeDB [1].
Основными возможностями, которые вносит SnappyData в Apache Spark считаются следующие [2]:
- изменчивость данных и согласованность транзакций;
- высокая степень параллелизма при обмене данными между пользователями и приложениями;
- поддержка быстрых запросов, таких как операция чтения/записи значения ключа и дорогостоящих по вычислительным затратам и времени операций агрегирования и заданий Machine Learning;
- доступ к аналитическим запросам во время высокоскоростных транзакций обновления данных.
Дополнительным аргументом в пользу SnappyData как полнофункционального и самодостаточного решения стал фокус на потоковой аналитики больших данных. Apache Spark – это вычислительный фреймворк, но не хранилище данных, поэтому информацию для обработки и анализа он считывает из внешних источников: реляционных и NoSQL-СУБД, а также файловых хранилищ, как Hadoop HDFS, так и облачные службы типа AWS S3. Подключение сторонних источников данных увеличивают сложность и снижают производительность всей Big Data системы, поскольку невозможно оптимизировать каждый источник данных. Кроме того, большинство этих хранилищ ориентированы на исторические данные, т.е. пакетный, а не потоковый режим обработки информации в реальном времени [2]. В этом отношении ключевым преимуществом SnappyData является то, что она не просто надстройка над Apache Spark, а целая аналитическая In-Memory СУБД [3]. О том, как это устроено, мы поговорим далее.
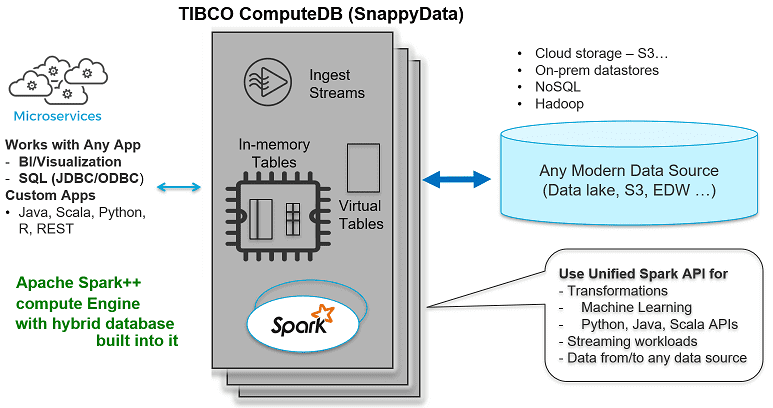
Что внутри SnappyData: как работает TIBCO ComputeDB
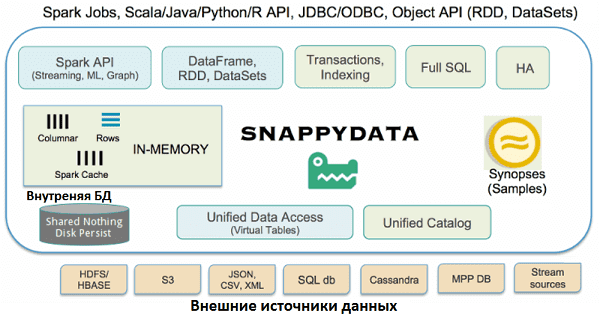
Как мы уже отметили выше, SnappyData — это распределенная аналитическая база данных, оптимизированная для работы в оперативной памяти, т.е. резидентная СУБД. Она обеспечивает высокую пропускную способность, низкую задержку и высокий уровень параллелизма для рабочих нагрузок унифицированной аналитики. Объединяя гибридную базу данных в памяти внутри Apache Spark, SnappyData предоставляет следующие функциональные возможности [3]:
- простое исследование и каталогизация больших наборов данных – можно подключаться и исследовать датасеты в реляционных базах, Apache Hadoop HDFS, NoSQL-СУБД, файловых системах или даже облачных хранилищах данных, таких как AWS S3, с помощью стандартного инструментария SQL-запросов, автоматически регистрируя схемы и сохраняя их в безопасном каталоге. По умолчанию поддерживаются самые разные форматы данных: JSON, CSV, текст, Parquet, ORC, SQL, XML и пр. Благодаря наличию коннектора Apache Spark, можно подключиться практиически к любому внешнему источнику через SQL или API RDD/Dataset. Можно даже динамически развертывать коннекторы в работающем кластере SnappyData. А благодаря JDBC, ODBC, REST и другим API-интерфейсам Apache Spark, SnappyData поддерживает современные инструменты визуализации и популярные BI-системы, такие как TIBCO Spotfire, Tableau и Qlikview.
- виртуальные (резидентные) данные в оперативной памяти – пользователь сам решает, какие датасеты выделить в распределенную память или оставить в источнике. Если данные остаются в источнике, после моделирования в виде виртуальных/внешних таблиц, аналитическая обработка запросов распараллеливается, и фрагменты запроса выполняются с высокой скоростью. А если нужно еще более ускорить вычисления, приложения могут выборочно копировать внешние данные в память с помощью одной команды SQL.
- хранение столбцов и строк в памяти. Данные в памяти могут храниться в форме столбца, сжатые для сканирования/агрегирования больших датасетов, или как строчное хранилище для очень быстрого или избирательного доступа. Столбчатое хранилище автоматически индексируется с использованием skipping-индекса, который предотвращает сканирование нерелевантных данных, используя статистику на уровне файлов, чтобы выполнить дополнительный пропуск при детализации файла. В Apache Spark это работает с разделением (партиционированием) в стиле Hive, но не зависит от него [4]. Приложения могут явно добавлять индексы для хранилища строк.
- высокая производительность – когда данные загружаются, механизм распараллеливает все обращения, тщательно учитывая доступные распределенные ресурсы: ядра ЦП, память и возможность разделения исходных данных. Поэтому, в отличие от традиционного хранилища, обращение к SnappyData для загрузки, обработки и удаления данных происходит очень быстро. При обработке запросов используются методы генерации кода и векторизации, чтобы по возможности перенести обработку на современные многоядерные процессоры и кэши L1 / L2 / L3.
- гибкое преобразование разнообразных данных с сохранением схемы источника для внешних данных. Пользователи могут очищать, смешивать, изменять форму данных с помощью функций Spark SQL, отправлять задания Apache Spark и использовать все многообразие API Apache Spark, описывая нужную бизнес-логику на SQL, Java, Scala или Python.
- Легкая подготовка данных для машинного обучения — используя возможности Apache Spark для статистики и Machine Learning (Spark MLLib), можно изучать статистические характеристики сырых и подготовленных данных, генерировать распределенные векторы функций через one-hot encoder, бинаризатор и прочие алгоритмы библиотеки MLLib. Результаты могут быть сохранены обратно в таблицы столбцов и совместно использоваться группой пользователей без сброса копий на диск, что ускоряет работу и снижает вероятность ошибок.
- Непрерывная потоковая передача – в отличие от пакетных механизмов запросов в Apache Presto, форматах HDFS, таких как Parquet и пр., в SnappyData прикладные системы могут передавать обновления данных через Kafka. Входящие данные могут быть CDC- событиями, такими как вставка, обновление или удаление измененных данных, и могут быть легко вставлены в in-memory таблицы, соблюдая согласованность и семантику строго однократной доставки (exactly once). Приложение может применять настраиваемую логику для выполнения сложных преобразований и подготовки данных для аналитики. Этот постепенный и непрерывный процесс намного эффективнее пакетного обновления.
- Приблизительная обработка запросов (Approximate Query Processing, AQP), которая позволяет сократить объем обрабатываемых данных, создав одну или несколько стратифицированных выборок вместо полного набора. Механизм запросов автоматически использует эти образцы для запросов агрегирования, возвращая клиентам приближенный к точному ответ. Это особенно полезно при визуализации тренда, построении графика или гистограммы.
В заключение сравним SnappyData со Spark, Kudu, Alluxio и Cassandra по следующим операциям: загрузка данных, выполнение аналитических запросов, выполнение поиска точек, выполнение обновлений/удалений [5]:
| Операция | Snappy Data embedded | Smart Connector SnappyData | ||||||
| Alluxio | Kudu | Cassandra | Spark | Alluxio | Kudu | Cassandra | Spark | |
|
Загрузка данных — SnappyData быстрее в Х раз |
2 | 8 | 60 | 2 | 8 | 60 | ||
| Выполнение аналитических запросов — SnappyData быстрее в Х раз | 3-6 | 6-15 | 2-3 | 3-6 | ||||
| Выполнение поиска точек — SnappyData быстрее в Х раз | 15-30 | 10-30 | 3000-9000 | 30-60 | одинаково | 2-3 | ||
|
Выполнение обновлений/удалений — SnappyData быстрее в Х раз |
6-11 | 300-400 | 6-8 | 250-300 | ||||
Таблица показывает, что «нативная» SnappyData (в режиме embedded) работает быстрее коннектора. Впрочем, оба режима показывают скорость выполнения операций с данными намного выше других популярных Big Data СУБД и вычислительных движков: Spark, Kudu, Alluxio и Cassandra [5].
Таким образом, чаще всего SnappyData (TIBCO ComputeDB) используется для быстрой аналитики больших данных с минимальной предварительной обработкой датасета или без нее, обеспечивая комплексную обработку за доли секунд благодаря грамотному управлению данными в памяти, динамической генерации кода с векторной оптимизацией и максимальному использованию потенциала современных многоядерных процессоров [4].
Чтобы на практике эффективно применять современные решения для аналитики больших данных на базе Apache Spark, узнайте о возможностях этого фреймворка на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://www.tibco.com/press-releases/2019/tibco-announces-acquisition-high-performance-memory-data-platform-snappydata
- https://towardsdatascience.com/why-you-need-a-unified-analytics-data-fabric-for-spark-c8b5d252cd0f
- https://snappydatainc.github.io/snappydata/
- https://docs.databricks.com/spark/latest/spark-sql/dataskipping-index/
- https://ru.bmstu.wiki/SnappyData

