
Сегодня рассмотрим, что такое Beekeeper и как этот сервис помогает администраторам Hadoop и пользователям Apache Hive очищать метаданные этого NoSQL-хранилища. Читайте далее, зачем удалять устаревшие пути из Metastore и как настроить конфигурацию Hive-таблиц для автоматического прослушивания событий их изменения. Для чего очищать потерянные метаданные в Apache Hive Напомним, Apache Hive...

В этой статье в поддержку курсов по Apache NiFi заглянем под капот этой платформы маршрутизации потоковых данных и рассмотрим, как дата-инженер может создать собственный процессор. Смотрите далее, как устроены процессоры в Apache NiFi, что общего между отношениями и маршрутами движения потоковых данных, как создать FlowFile, зачем нужен метод onTrigger() и...

Специально для разработчиков распределенных приложений, Data Scientist’ов и аналитиков больших данных, работающих с Apache Spark, в этой статье мы собрали несколько полезных советов по ежедневным операциям в этом фреймворке. Читайте далее, как добавить библиотеку TypeSafe в файл sbt-конфигурации Spark-приложения, получить датафреймы из JSON-массивов и структур, а также обработать CSV-формат с...
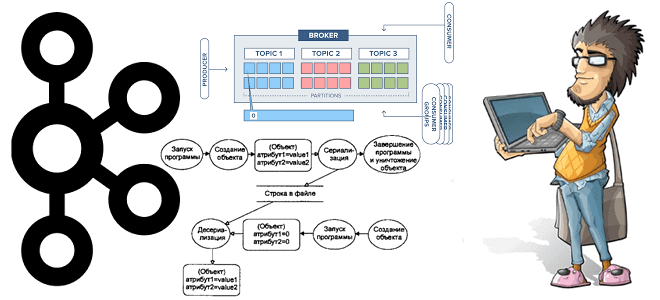
В рамках курсов по Apache Kafka для разработчиков и администраторов кластера, сегодня заглянем под капот AdminClient и на практических примерах разберем, как динамически создавать новый топик и описывать его программным способом через API. Еще рассмотрим, почему метод deleteTopics() нужно применять очень осторожно, а также вспомним основы ООП, говоря про классы...

Чтобы дополнить наши курсы по Kafka и Spark интересными примерами, сегодня рассмотрим практический кейс разработки микросервисного конвейера машинного обучения на этих фреймворках. Читайте далее, зачем выносить ML-компонент в отдельное Python-приложение от остальной части Big Data pipeline’а, и как Docker поддерживает эту концепцию микросервисного подхода. Постановка задачи и компоненты микросервисного ML-конвейера...

В июле 2021 года «Аренадата Софтвер», российская ИТ-компания разработчик отечественных решений для хранения и аналитики больших данных, представила минорный релиз корпоративного дистрибутива на базе Apache Hadoop — Arenadata Hadoop 2.1.4. Главными фишками этого выпуска стало наличие 3-й версии Apache Spark и External PostgreSQL для Hive MetaStore. Сегодня рассмотрим, что именно...

Сегодня в рамках обучения разработчиков Apache Spark и дата-аналитиков, поговорим про детерминированность UDF-функций и особенности их обработки оптимизатором SQL-запросов Catalyst. На практических примерах рассмотрим, как оптимизатор Spark SQL обрабатывает недетерминированные выражения и зачем кэшировать промежуточные результаты, чтобы гарантированно получить корректный выход. Еще раз про детерминированность функций и планы выполнения...
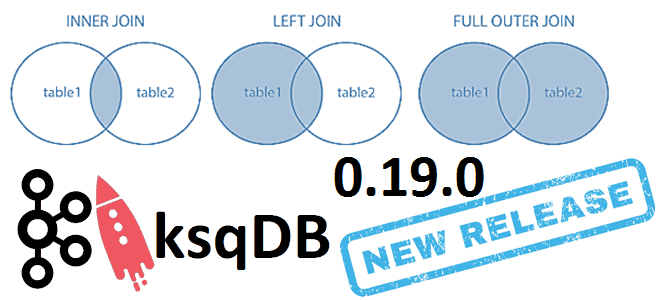
6 июня 2021 года компания Confluent, которая продвигает коммерческую версию платформы Apache Kafka, выпустила новый релиз ksqlDB. Сегодня рассмотрим самые важные исправления ошибок и новые функции ksqlDB 0.19.0, уделив особое внимание SQL-запросам соединения таблиц через JOIN по внешнему ключу. ТОП-10 исправленных ошибок в новом релизе ksqlDB Напомним, ksqlDB – это...

14 июля 2021 года вышел минорный релиз Apache NiFi – версия 1.14.0. Сегодня рассмотрим его главные фичи, исправленные ошибки и улучшения, уделив особое внимание новым функциям обеспечения информационной безопасности в этой популярной платформе управления потоками Big Data. ТОП-5 новинок Apache NiFi 1.14.0 В новом выпуске Apache NiFi 1.14.0 исправлено 139...

Продолжая разбирать тонкости сериализации данных в Apache Kafka на практических примерах, сегодня рассмотрим кейс индийской ИТ-компании Naukri Engineering о повторной обработке сообщений и особенностях форматов. Читайте далее, чем хороши заголовки Kafka и почему их не так просто использовать, а также зачем писать свой сериализатор с десериализатором для достижения 100%-ного SLA....