 103
103 
Содержание
В этой статье в поддержку курсов по Apache NiFi заглянем под капот этой платформы маршрутизации потоковых данных и рассмотрим, как дата-инженер может создать собственный процессор. Смотрите далее, как устроены процессоры в Apache NiFi, что общего между отношениями и маршрутами движения потоковых данных, как создать FlowFile, зачем нужен метод onTrigger() и каким образом аннотировать другие Java-методы.
Процессоры в Apache NiFi: что это и как они работают
В Apache NiFi процессор можно рассматривать как функцию, которая принимает входные данные и производит на выходе результат с различными конфигурациями. NiFi включает широкий перечень типовых процессоров с большим набором коннекторов и функций. Однако, иногда дата-инженеру необходимо написать собственный процессор, который выполняет некоторую комбинацию маршрутизации данных, преобразования или взаимодействия между системами. Как сделать это, мы рассмотрим чуть позже, а пока разберем что такое процессоры и как они работают.
Процессоры имеют доступ к метаданным (атрибутам) потокового файла (FlowFile) и его содержимому, подключаясь друг к другу по принципу направленного ациклического графа (DAG) в конвейере данных. Один и тот же вывод процессора может быть отправлен на несколько разных процессоров, соединенных очередью. Подробнее о том, как манипулировать атрибутами с помощью внутреннего языка выражений NiFi, читайте в нашей новой статье.
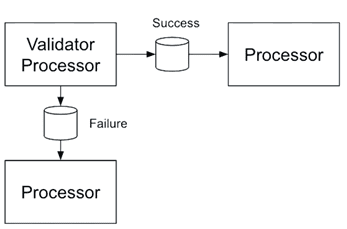
Сообщения, которыми обмениваются процессоры, называются потоковыми файлами, которые передаются от одного процессора к другому через очередь. Вход в процессор может поступать от другого вышестоящего процессора из внешней системы, например, Apache Kafka, СУБД, файловый сервер и пр. Выходные данные каждого процессора представляют собой FlowFile с содержимым и метаданными. Процессор может выводить несколько потоковых файлов за один раз, которые могут быть направлены по одному или нескольким маршрутам. Например, процессор Validator проверяет валидность сообщения по определенным критериями и отправляет валидные данные по маршруту успешной обработки (Success), а недопустимые сообщения — на отказ (Failure). Такие маршруты в NiFi называются отношениями (relationships).
К примеру, система поддерживает входные сообщения в трех видах, каждый из которых обрабатывается по-разному. Для этого пользовательский процессор Version Router может получить потоковый файл, определить его формат и отправить в одно из трех отношений (v1, v2, v3), соединенных с соответствующими процессорами (Version 1 Processor, Version 2 Processor, Version 3 Processor).
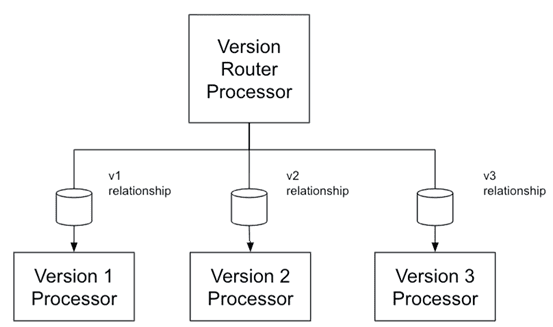
Отношения, поддерживаемые процессором, объявляются в процессоре как набор relationship-объектов. Чтобы выполнять различные функции или подключаться к внешней системе, процессор использует конфигурации. Например, для подключения к системе обмена сообщениями Azure Event Hub необходимы сведения об аутентификации и конечной точке, которые передаются как свойства процессора.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
10 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Свойство, которое требуется или поддерживается процессором, является объектом PropertyDescriptor с разными полями, включая имя, описание, обязательное и конфиденциальное. Список таких дескрипторов свойств, которые закодированы в процессоре, используется веб-приложением для отображения свойств процессора. Свойства, определенные пользователем для экземпляра процессора, могут быть дополнительно проверены путем переопределения метода customValidate() родительского класса AbstractConfigurableComponent [1].
Процессор, подключенный к другому вышестоящему процессору, может получить FlowFile с помощью различных методов. Например, метод EvaluateJsonPath() получает потоковый файл из восходящего потока и проверяет ожидаемый путь в его JSON-содержимом.
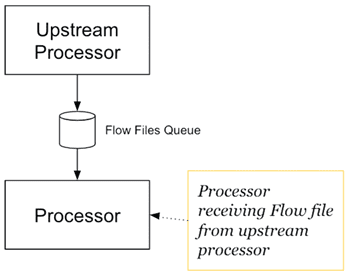
В отличие от службы контроллера, метод onTrigger() для выполнения работы реализуется в каждом процессоре. Реализация метода onTrigger (ProcessContext, ProcessSession) использует сеанс процесса ProcessSession для получения входного FlowFile. Конфигурация, которая определяет свойства в пользовательском интерфейсе, получается из контекста процесса ProcessContext, обеспечивающим мост между процессором и NiFi. Таким образом, создание одного или нескольких FlowFile из процессора сводится к следующим шагам [1]:
- создание FlowFile с использованием create;
- добавление содержимого в FlowFile с write;
- добавление атрибутов с помощью writeAttribute;
- передача потокового файла потока в отношение с transfer;
- фиксация сеанса с commit.
Унифицированное логирование во время обработки можно выполнить с помощью ComponentLog, доступного процессору из метода getLogger(). Далее рассмотрим, что будет внутри пользовательского процессора.
Как написать собственный процессор: простой пример с ликбезом по аннотациям Java
Прежде чем перейти к подробностям написания пользовательского процессора, отметим, что в Apache NiFi процессоры, как и другие компоненты, имеют свой жизненный цикл. Для поддержки жизненного цикла компонентов API NiFi использует аннотации Java из пакета org.apache.nifi.annotation.lifecycle. Напомним, в языке Java, на котором написан фреймворк, аннотация – это специальная форма синтетических метаданных, которая может быть добавлена в исходный код для его анализа, компиляции или выполнения. Аннотированы могут быть пакеты, классы, методы, переменные и параметры. Аннотация предоставляет необходимую информацию для компилятора и различных инструментов генерации другого кода, конфигураций и пр. а также может быть использована во время работы.
Аннотации представляют из себя дескрипторы в тексте программы для хранения метаданных программного кода на разных этапах ее жизненного цикла. Информация в аннотациях может использоваться соответствующими обработчиками для создания необходимых вспомогательных файлов или маркировки классов, полей и т.д. Аннотации могут быть применены к декларациям классов, полей и методов, а также самих аннотаций [2].
В Apache NiFi к методам Java в процессоре могут применяться следующие аннотации, чтобы указать платформе, когда следует их вызывать [3]:
- @OnAdded — вызывает метод сразу после создания компонента. Метод инициализации компонента будет вызываться после создания компонента, за которым следуют методы, помеченные @OnAdded. Если какой-либо метод, помеченный @OnAdded, выдает исключение, пользователю будет возвращена ошибка, и этот компонент не будет добавлен в поток. Другие методы с этой аннотацией не будут вызываться. Метод initialize() или init() для подклассов абстрактного класса AbstractProcessor вызывается только один раз за время жизни компонента и не имеет аргументов.
- @OnRemoved — вызывает метод перед удалением компонента из потока, чтобы освободить ресурсы. Методы с этой аннотацией не имеют аргументов. Если метод с этой аннотацией вызывает исключение, компонент все равно будет удален.
- @OnScheduled — указывает, что метод вызывается каждый раз при планировании запуска компонента. Если какой-либо метод с этой аннотацией вызывает исключение, другие методы с ней не будут вызваны, о чем пользователь будет уведомлен. В этом случае затем запускаются методы с аннотацией @OnUnscheduled, за которыми следуют методы с аннотацией @OnStopped. Причем если какой-либо из этих методов выдает исключение, эти исключения игнорируются. Затем компонент завершит свое выполнение в течение некоторого периода времени, называемого Administrative Yield Duration, значение которого настраивается в файле properties. Наконец, процесс будет запущен снова, пока все методы, помеченные @OnScheduled, не вернутся без выдачи исключения.
- @OnUnscheduled — методы с этой аннотацией будут вызываться каждый раз, когда выполнение процессора больше не запланировано, хотя многие потоки все еще могут быть активны в его методе onTrigger(). Если такой метод вызывает исключение, это логируется, исключение игнорируется, а другие методы с этой аннотацией по-прежнему будут вызываться.
- @OnStopped — методы с этой аннотацией будут вызываться, когда выполнение процессора больше не запланировано и все потоки вернулись из метода onTrigger(). Если такой метод вызывает исключение, это логируется, исключение игнорируется, а другие методы с этой аннотацией по-прежнему будут вызываться.
- @OnShutdown – методы с этой аннотацией будут вызываться при успешном завершении работы NiFi. Если такой метод вызывает исключение, будет сгенерировано сообщение журнала, в противном случае исключение будет проигнорировано, а другие методы с этой аннотацией по-прежнему будут вызываться. Методы с этой аннотацией не должны иметь аргументов. Интересно, NiFi не всегда может вызывать методы с этой аннотацией на всех компонентах, которые ее используют. Например, процесс может быть неожиданно остановлен без возможности вызвать указанные методы. Поэтому на методах, аннотированных @OnShutdown, не следует использовать для критической бизнес-логики.
Методы, аннотированные @OnScheduled, @OnUnScheduled и @OnStopped могут принимать единственный аргумент с типом ProcessContext для процессора или не иметь аргументов вообще.
Таким образом, типовая реализация процессора выглядит так [1]:
class SampleProcessor { Set<Relationship> getRelationships() List<PropertyDescriptor>
getSupportedPropertyDescriptors() Collection<ValidationResult> customValidate()
public void onTrigger(...) @OnScheduled
public void onScheduled() @OnStopped
void close() @OnUnscheduled
public void stopConnectionRetainer()
}
В этом материале мы рассказываем, как написать собственный код на TypeScript для процессора ExecuteScript, и чем это будет лучше JavaScript. Читайте далее, как протестировать созданные компоненты.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
10 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
О том, что такое ориентированные на запись процессоры и как они повышают пропускную способность потокового конвейера обработки данных, читайте в нашей следующей статье. Про масштабирование этой платформы маршрутизации потоков данных с помощью Docker и Kubernetes мы рассказываем здесь. А написать собственный процессор, детально освоить администрирование и использование Apache NiFi для современной дата-инженерии вам помогут специализированные курсы для разработчиков, ИТ-архитекторов, инженеров данных, администраторов, Data Scientist’ов и аналитиков Big Data в нашем лицензированном учебном центре обучения и повышения квалификации в Москве:

