
Как устроен планировщик заданий Apache AirFlow, от чего зависит его производительность и какие конфигурации помогут ее улучшить: настройки, приемы, рекомендуемые значения и лучшие практики. Как работает планировщик Apache AirFlow Apache AirFlow как фреймворк оркестрации пакетных процессов включает несколько компонентов. Одним из них является планировщик (scheduler), который отслеживает все задачи и...
Аналитика данных из топиков Kafka с помощью SQL-запросов: обращение к ksqlDB в Docker через CLI-интерфейс и REST API в Postman с SSH-тунелированием сервера потоковой базы данных. Практическое руководство с примерами и иллюстрациями. CLI-интерфейс ksqldb Docker-образ Confluent Kafka включает дополнительные компоненты этой платформы: ksqlDB, Kafka Connect, REST Proxy, Schema Registry). Сегодня...
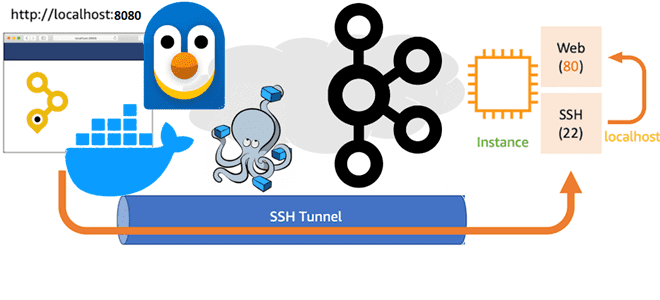
Как туннелировать порты Docker-контейнеров для доступа к Kafka на WSL в Windows с внешнего клиента: переадресация HTTP- и TCP-соединений с помощью SSH-сервера serveo. Поиск средства тунелирования и настройка портов Собственное развертывание платформы Kafka от Confluent в виде набора связанных Docker-контейнеров в WSL на Windows с GUI-интерфейсом AKHQ, о чем я...
Как настроить YAML-файл Docker Compose для доступа к Kafka на WSL в Windows: открытие портов в конфигурации развертывания с примерами (продолжение). Настройка конфигурационного YAML-файла для запуска Docker-контейнеров с компонентами Kafka на Windows в WSL Как я рассказывала вчера, для работы с компонентами платформы Kafka от Confluent, развернутой как набор связанных...

WSL и Docker для локального развертывания Apache Kafka с GUI и всеми компонентами в контейнере: моя реальная история поиска веб-интерфейса и настройки портов (начало). Развертывание Kafka на Windows с Docker в WSL В конце августа 2024 года команда serverless-платформы Upstash, на которой у меня есть рабочий инстанс Apache Kafka, разослала...
Зачем нужна автоматическая очистка таблиц системного каталога Greenplum, почему команда AUTOVACUUM выполняется локально на каждом сегменте и как ее настроить для максимальной эффективности старых кортежей в распределенной базе данных с массовой-параллельной обработкой. Параметры автоматической очистки в Greenplum О том, зачем нужна команда автоочистки в Greenplum и как она работает, мы...
Чем планирование запуска DAG в Apache AirFlow с объектом timedelta отличается от использования cron-выражений, в чем разница CronTriggerTimetable и CronDataIntervalTimetable, а также как создать собственный класс расписания. Объект timedelta vs cron-выражение: задание расписания запуска DAG в Apache AirFlow Apache AirFlow идеально подходит для классических пакетных ETL-сценариев, например, когда надо извлечь...
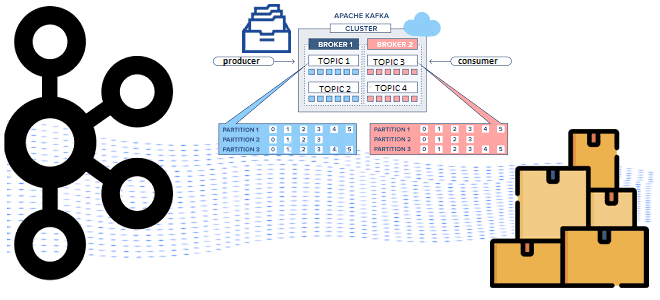
Какие конфигурации настроить на продюсере для эффективной публикации сообщений в Apache Kafka: упаковка записей в пакеты, взаимодействие с брокерами и метрики мониторинга этих процессов. Пакетирование сообщений при их публикации в Kafka и мониторинг этого процесса Хотя Apache Kafka поддерживает потоковую парадигму обработки информации, она активно использует пакетные технологии. В частности,...
Как сделать крупное обновление, вставку или удаление данных в Neo4j без OOM-ошибки и APOC-процедур при выполнении транзакции с параллельным выполнением подзапросов: функция CICT, ее возможности, ограничения и отличия от конструкции CALL IN TRANSACTIONS. Подзапросы в транзакциях Neo4j: CIT-запросы Cypher vs процедуры APOC Параллельная обработка данных быстрее последовательной. Поэтому многие фреймворки...

Как решать задачи машинного обучения в Greenplum с агентом gpMLBot и расширением PostgresML: возможности, ограничения и примеры. Что такое gpMLBot: Greenplum Automated Machine Learning Agent Чтобы использовать Greenplum как хранилище данных в задачах машинного обучения, в этой БД поддерживаются соответствующие механизмы. Одним из них является библиотека Apache MADlib, о которой...