
Apache Kafka – не единственный программный брокер сообщений и система управления очередями, используемая в высоконагруженных Big Data проектах. Кафка часто сравнивают с другим популярным продуктом аналогичного назначения – RabbitMQ. В сегодняшней статье мы рассмотрим, чем похожи и чем отличаются Apache Kafka и RabbitMQ, а также поговорим о том, что следует...

Мы уже рассказывали о сериализации, схемах данных и их важности в Big Data на примере Schema Registry для Apache Kafka. В продолжение ряда статей про основы Кафка для начинающих, сегодня мы поговорим про Apache Avro – наиболее популярную схему и систему сериализации данных: ее особенностях и применении в технологиях Big...
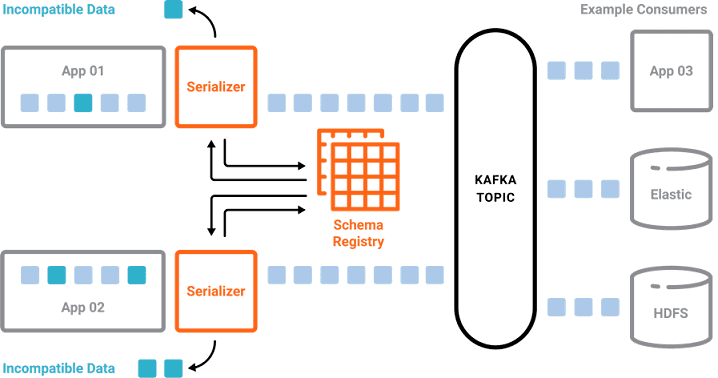
Продолжая серию публикаций про основы Apache Kafka для начинающих, в этой статье мы рассмотрим, зачем этой распределенной системе управления сообщениями нужен реестр схем данных (Schema Registry) и что такое сериализация файлов Big Data. Что такое схемы данных в Big Data и как они используются Понятие схемы неразрывно связано с форматом...

В рамках серии публикаций про основы Apache Kafka для начинающих, сегодня мы поговорим про информационную безопасность этой популярной в сфере Big Data распределенной системы управления сообщениями: шифрование, защищенные протоколы, аутентификация, авторизация и другие средства cybersecurity. Что обеспечивает безопасность Apache Kafka в кластере Big Data Информационная безопасность Apache Kafka основана на...
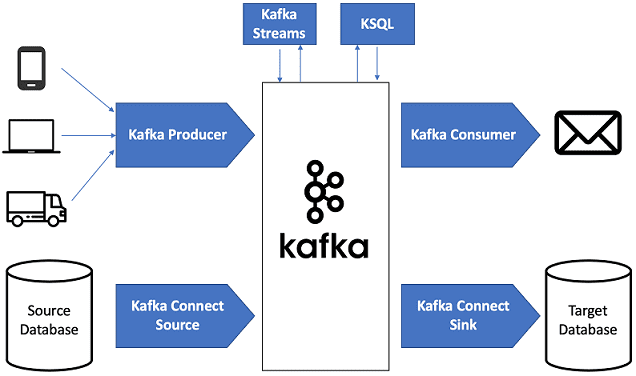
Продолжая разговор про основы Apache Kafka, сегодня мы рассмотрим, почему этот распределённый брокер сообщений стал таким популярным в архитектуре систем Big Data. Читайте в нашей статье, как Кафка обеспечивает высокую производительность процессов сбора и агрегации информационных потоков от множества источников, надежно гарантируя долговечную сохранность сообщений, и эффективно интегрируется с другими...
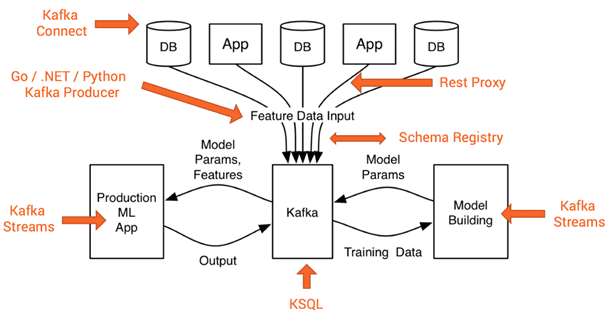
Рассмотрев основы Apache Kafka, сегодня мы расскажем о месте этого распределённого брокера сообщений в архитектуре Big Data систем. Читайте в нашей статье, какие компоненты Кафка обеспечивают ее использование в программных продуктах машинного обучения (Machine Learning, ML), интернете вещей (Internet Of Things, IoT), системах бизнес-аналитики (Business Intelligence, BI), а также других...

Мы уже упоминали Apache Kafka в статье про промышленный интернет вещей (Industrial Internet Of Things, IIoT). Сегодня поговорим о том, где и для чего еще в Big Data проектах используется эта распределённая, горизонтально масштабируемая система обработки сообщений. Как работает Apache Kafka Apache Kafka позволяет в режиме онлайн обеспечить сбор и...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...

Нормализация данных – это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining). Что такое нормализация данных и чем она...