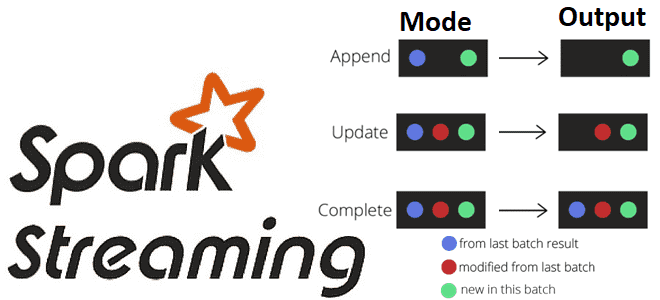
Какие бывают режимы вывода в структурированной потоковой передаче Spark, чем они отличаются и как их использовать на практике: разбираемся на практическом примере. Краткий ликбез по output modes в Apache Spark Structured Streaming для обучения дата-инженеров и разработчиков распределенных приложений. Что такое режимы вывода в Apache Spark Structured Streaming Apache Spark...
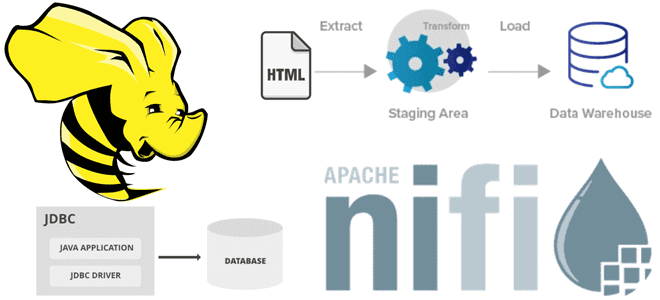
В этой статье для дата-инженеров рассмотрим пример интеграции Apache NiFi c Hive в рамках ETL-конвейера потокового веб-скрейпинга, который будет получать данные с веб-страницы практически без кода, обрабатывать их и загружать в таблицу NoSQL-СУБД в реальном времени. Постановка задачи: ETL-процесс веб-скрейпинга В реальной жизни задача считать данные с веб-сайта для последующей...
Сегодня рассмотрим, что такое процессор ExecuteScript в Apache NiFi, как с его помощью реализовать собственную бизнес-логику обработки потоков данных на мульти-парадигмальном языке программирования TypeScript и чем это будет лучше кода на JavaScript. Краткий ликбез для дата-инженеров. Процессор ExecuteScript в Apache NiFi Напомним, за обработку потоков данных в Apache NiFi отвечают...
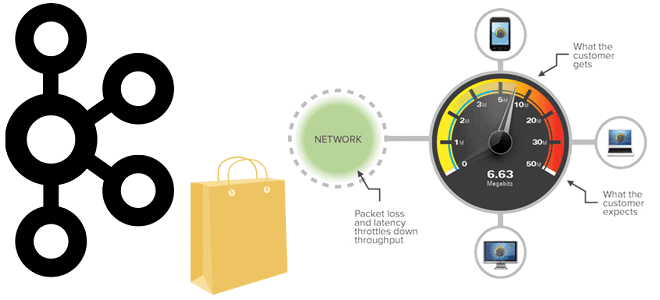
Пропускная способность информационной системы на базе Apache Kafka говорит о том, сколько данных могут быть обработаны за определенный период времени. Несмотря на потоковую передачу событий, здесь работает классический закон обратной зависимости скорости обработки данных от их объема. Разбираемся, как найти баланс между производительностью и задержкой. Еще раз о пропускной способности...

В продолжение недавней статьи для дата-инженеров по эффективной работе с Apache AirFlow, сегодня разберем еще несколько рекомендаций от компании Astronomer, которая продвигает и коммерциализирует этот ETL-оркестратор. Чем полезна микрооркестрация с несколькими средами AirFlow, как обеспечить повторное использование и воспроизводимость, зачем нужна интеграция с инструментами и процессами CI/CD. Микрооркестрация с множеством...
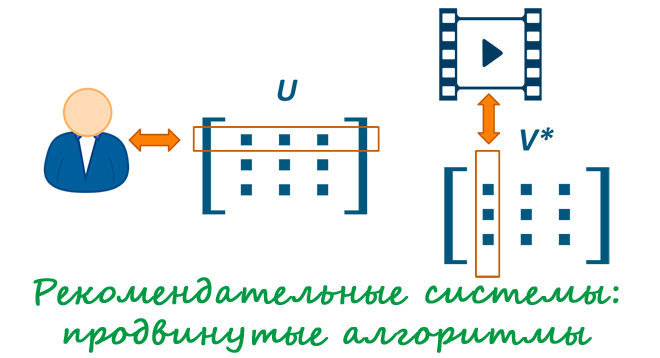
В прошлой статье мы разобрали методы построения рекомендательных систем: коллаборативная фильтрация; фильтрация на контенте; фильтрация на знаниях; гибридный подход. Мы намеренно не упомянули об одном важном подходе построения рекомендаций: об использовании матричных разложений. Описание данного метода заслуживает отдельной статьи! Будем эксплуатировать традиционный для рекомендательных систем кейс рекомендации фильмов пользователям. Напомним,...
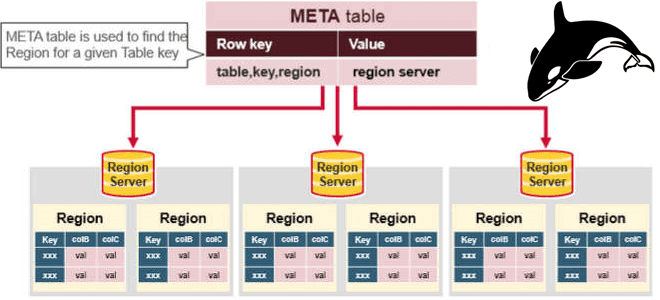
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...
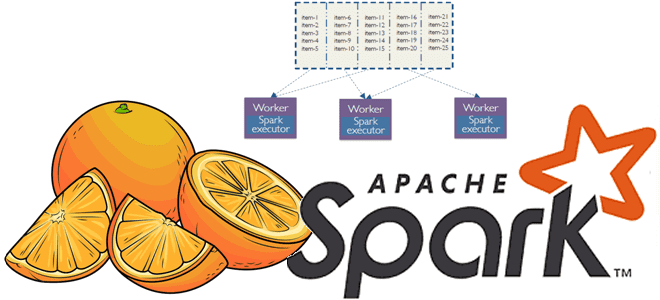
Мы уже рассказывали про функции перераспределения данных по разделам coalesce() и repartition(). Сегодня сравним их работу с еще одним методом управления разделами в Apache Spark и разберем, как все они могут помочь дата-инженеру и разработчику распределенных приложений повысить эффективность этого популярного фреймворка аналитики больших данных. Отобрать и поделить: лучшие практики партиционирования данных...
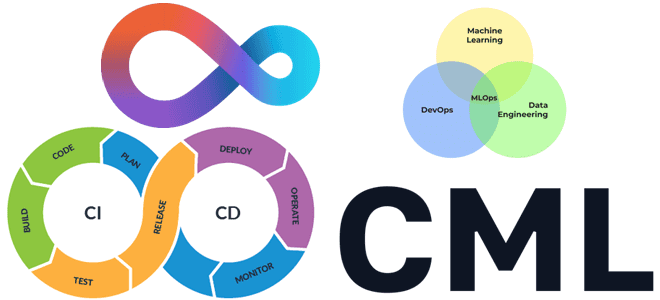
Что такое непрерывное машинное обучение, как оно работает и при чем здесь MLOps. Почему сложно вести разработку ML-моделей в стиле CI/CD и как CML помогает обойти эти ограничения. Автоматизация процессов непрерывной интеграции и доставки с помощью open-source CLI-инструмента от Iterative.ai. Трудности CI/CD в Machine Learning и MLOps Поддерживаемые DevOps-концепцией идеи...

Как быстро и эффективно с помощью Neo4j выявить преступников, незаконно ввозящих в страну контрафактные товары. Почему графовая СУБД Neo4j обошла документо-ориентированную MongoDB, из чего состоит алгоритм поиска рецидивистов средствами технологий аналитики больших данных и как это может пригодиться в других бизнес-приложениях. Постановка задачи: сложности отслеживания контрафакта Каждый день практически в...
Недавно мы рассказывали про тонкости хранения потоковых файлов в Apache NiFi. Продолжая эту важную для обучения дата-инженеров тему, сегодня разберем еще несколько причин повышенного потребления ресурсов при работе с этим фреймворком и способы обхода этих ограничений. Характер потоков и размер репозитория Apache NiFi не позволяет управлять ресурсами в разрезе потоков...

Пример выявления финансового мошенничества при скимминге банковских карт в банкоматах с помощью технологий Big Data. Как Apache Kafka, Flink и HBase помогут обнаружить злоумышленников в режиме реального времени. Что такое скимминг, как это работает и чем опасно Скимминг является одним из частых видов мошенничества с банковскими картами, представляющий собой считывание...
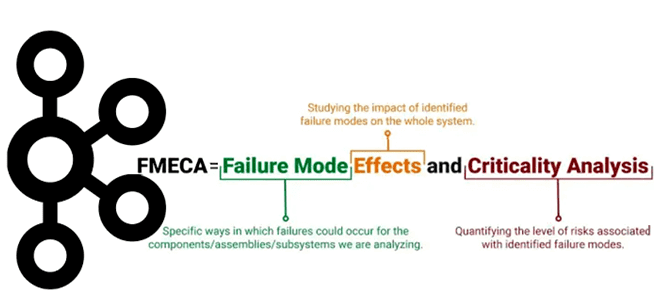
Хотя Apache Kafka является надежной платформой потоковой обработки событий, что особенно важно для распределенных приложений, отказы случаются и в ней. Сегодня разберем важную для обучения разработчиков и дата-инженеров тему про идентификацию и обработку отказов в Kafka-приложениях с помощью простого, но эффективного метода теории надежности. Что такое FMECA-анализ, как его проводить...

Как настроить Apache Spark 3.0.1 и Hive 3.1.2 на Hadoop 3.3.0: тонкости установки и конфигурирования для обучения администраторов кластера и инженеров с примерами команд и кода распределенных приложений. Запуск Spark-приложения на Hadoop-кластере Прежде всего, для настройки кластера Apache Spark нужен работающий кластер Hadoop. Сама установка и настройка выполняется в 2...

Сегодня рассмотрим несколько рекомендаций по построению масштабной и устойчивой экосистемы интеграции корпоративных данных на базе Apache AirFlow от компании Astronomer, которая активно способствует продвижению и коммерциализации этого популярного инструмента дата-инженерии. Как организовать эффективную маршрутизацию рабочих процессов с пакетным ETL-оркестратором: 3 лучших практики. Стандартизация сред разработки и промышленной эксплуатации с Kubernetes...
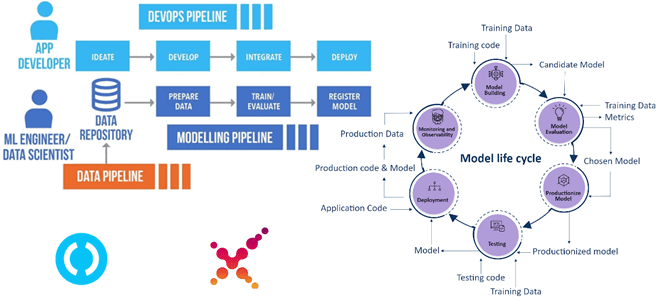
Чтобы сделать наши курсы для специалистов в области Data Science и ML-инженеров еще более полезными, сегодня рассмотрим, как организовать сквозной CI/CD-конвейер разработки и развертывания системы машинного обучения в соответствии с MLOps-концепцией на 4-х популярных Python-инструментах: MLflow, DVC, Airflow, ClearML. А в качестве примера практической реализации этой идеи разберем кейс банка...

В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим проблемы неконстистентности чтения из графовой СУБД Neo4j и способы их решения. Что такое bookmarks-механизм, как работает объект сеанса в Neo4j в кластерном режиме и при чем здесь драйверы. Зачем нужны закладки в Neo4j Драйверы графовой...
Мы уже писали про главные недостатки Apache NiFi как инструмента потоковой маршрутизации данных и организации ETL-процессов. Одним из них считается высокое потребление дискового пространства. Почему это случается и как с этим бороться: тонкости работы с потоковыми файлами на уровне жесткого диска - процессоры, очереди, сохранение и изменения FlowFile в Apache...
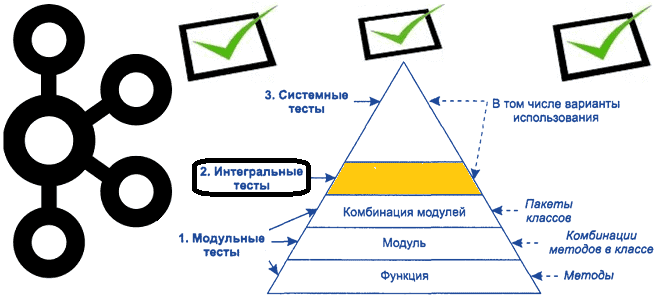
Продолжая важную для обучения разработчиков распределенных приложений и дата-инженеров тему про тестирование Big Data систем на базе Apache Kafka, сегодня рассмотрим некоторые средства для создания интеграционных тестов. Краткий ликбез по интеграционному тестированию приложений Apache Kafka В отличие от модульного тестирования, которое мы разбирали ранее, интеграционное тестирование сосредоточено на интерфейсах и потоке...
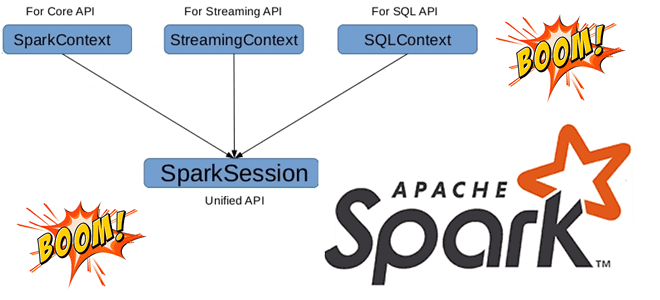
Может ли быть несколько сеансов в одном Spark-приложении с разной конфигурацией, зачем нужен метод foreachBatch() в структурированной потоковой передаче и чем он отличается от foreach(), почему возникает ошибка Table or view not found: microBatch и как ее обойти. В рамках обучения разработчиков Apache Spark и дата-инженеров заглядываем под капот этого...