
Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...

Недавно мы писали про Apache NiFi 1.23.1, выпущенный 18.08.2023. Однако, использовать его не следует, также как и предыдущий релиз этой линейки. Разбираемся, почему тем, кто перешел на NiFi 1.23, нужно срочно обновиться до версии 1.23.2 от 22 августа 2023 года. Что не так с Apache NiFi 1.23 и как это...

Может ли Apache Kafka поддерживать не только хореографический стиль взаимодействия между разными сервисами, кто и как организует оркестрацию рабочих процессов с помощью этой распределенной платформой потоковой передачи и почему она не заменит BPM-движки. Оркестрация событий с Apache Kafka При использовании Apache Kafka в архитектуре, управляемой событиями (EDA, Event Driven Architecture),...
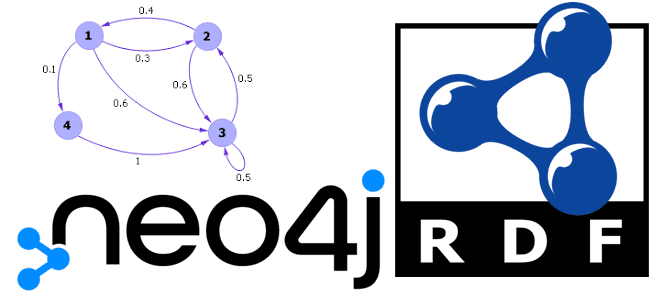
Что такое триплеты, чем они отличаются от обычных графов свойств и где используются на практике. Знакомимся с RDF и возможностями графовой СУБД Neo4j работать с этой структурой описания веб-ресурсов с помощью плагина Neosemantics. Что такое триплеты и при чем здесь RDF Триплеты (triples) — это текстовый формат, используемый для хранения...
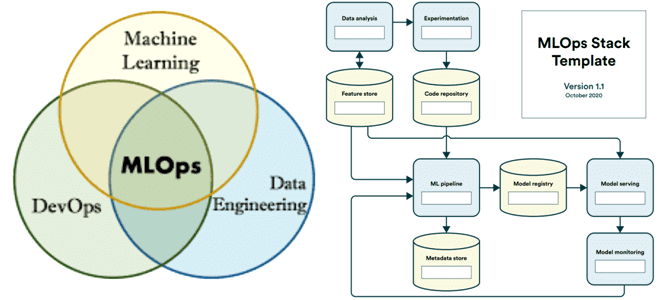
Как внедрить ключевые идеи MLOps и определиться с набором инструментов для непрерывной разработки и поставки систем машинного обучения. Лучшие практики и шаблон представления техстека. С чего начать: определение структуры проекта Напомним, концепция MLOps ориентирована на устранение организационных и технических разрывов между разнопрофильными участниками процессов создания систем машинного обучения. Когда речь...
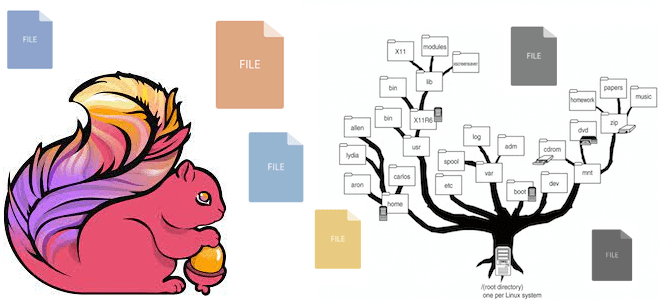
Какие файловые системы поддерживает Apache Flink: средства взаимодействия с файлами, хранящимися локально или в объектных хранилищах HDFS, S3 и GCS. Особенности работы с файловыми системами в Apache Flink Apache Flink имеет собственную абстракцию файловой системы через класс org.apache.flink.core.fs.FileSystem. Эта абстракция обеспечивает общий набор операций и минимальные гарантии для различных типов...

Что такое квоты в Apache Kafka и как этот механизм позволяет управлять ресурсами брокера, предупреждая DDOS-атаки от слишком активных потребителей и продюсеров. Разбираемся с типами клиентских квот, их конфигурациями и принципами работы. Квоты клиента и пользователя в Apache Kafka Чтобы управлять ресурсами брокера, кластер Kafka может применять квоты на запросы...

18 августа 2023 года вышел очередной релиз Apache NiFi. Смотрим, какие проблемы устранены в этом выпуске, знакомимся с обновлениями коннекторов, а также прочими изменениями в NiFi 1.23.1. Apache NiFi 1.23.1: главные новости Apache NiFi 1.23.1 не зря назван отладочным выпуском. В нем нет ни одной новой фичи, однако, исправлено 11...
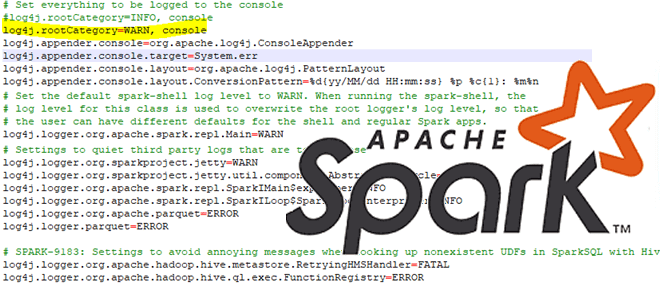
Сегодня рассмотрим особенности отладки PySpark-приложений: как Python-код исполняется в JVM, какие сложности возникают у разработчика при тестировании и исправлении ошибок в программе, написанной локально и запускаемой в кластере, а также как настроить вывод событий в лог-файл. Запуск и выполнение PySpark-кода Хотя Apache Spark и имеет Python API, позволяя писать код...

14 августа 2023 года вышел очередной релиз Apache AirFlow . Разбираем его самые главные новые возможности, улучшения и исправления ошибок: отказ от Python 3.7, задачи установки/демонтажа, встроенная поддержка спецификации OpenLineage, обновления интерфейса, упрощение управления сложными зависимостями и другие фичи Apache AirFlow 2.7. Задачи установки/демонтажа Apache AirFlow 2.7 содержит более 35...

Что такое потоковое обогащение данных, зачем это нужно и как оно реализуется в Apache Flink. Проблемы и решения предварительной загрузки справочных данных в память, синхронного и асинхронного поиска в источнике по каждой записи и организация потоковой передачи событий. 3 способа загрузить эталонные (справочные) данных в Apache Flink для обогащения потока...
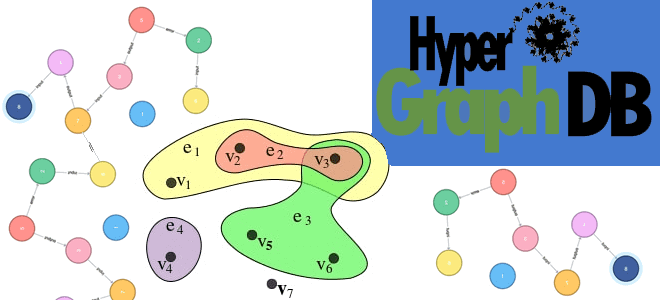
Чем гиперграфы отличаются от обычных графов знаний, где они используются на практике и как эта математическая концепция поддерживается в NoSQL-СУБД HyperGraphDB. Что такое гиперграф Гиперграф — это графовая модель данных, в которой отношения (гиперребра) могут соединять любое количество заданных узлов. Можно сказать, что это обобщение графа, в котором каждым ребром...
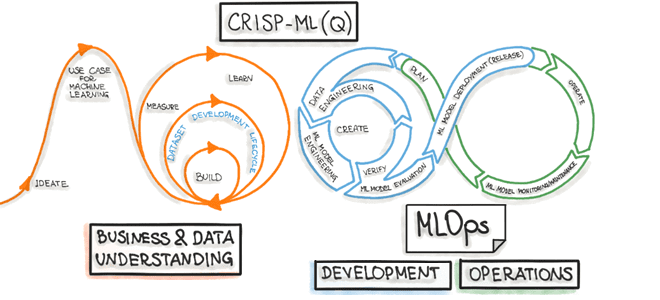
Что представляет собой межотраслевой стандартный процесс машинного обучения CRISP-ML(Q), из каких этапов и задач он состоит, а также как согласуется с концепцией MLOps. Что такое CRISP-ML(Q) и при чем здесь MLOps Стандартизация подходов и процессов позволяет унифицировать и масштабировать лучшие практики управления исследованиями и разработкой, в т.ч. распространяя их на...
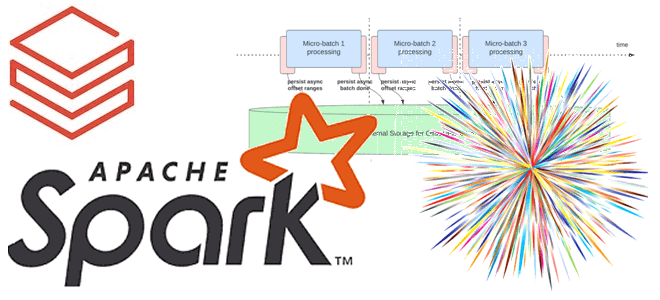
В прошлом году Databricks выпустили новый проект для ускорения потоковой передачи в Apache Spark. Сегодня рассмотрим, как именно Lightspeed сокращает задержку в операционных рабочих нагрузках Structured Streaming с помощью асинхронного управления смещением. Операционные рабочие нагрузки и что их тормозит в Apache Spark Structured Streaming Рабочие нагрузки потоковой передачи можно разделить...
Чем базы данных временных рядов отличаются от реляционных и key-value хранилищ, какова модель данных для хранения метрик, значения которых меняются во времени, какие решения этой категории NoSQL-СУБД сегодня популярны на рынке и для чего они используются. Что такое база данных временных рядов и где она используется Как и следует из...

Сегодня рассмотрим, какие системные метрики Greenplum необходимо отслеживать администратору кластера и дата-инженеру для оценки работоспособности и эффективности этой СУБД, а также с помощью каких инструментов это сделать. Мониторинг средствами Greenplum Прежде всего, стоит отметить, что контролировать Greenplum можно с помощью различных инструментов, включенных в систему или доступных в качестве надстроек....
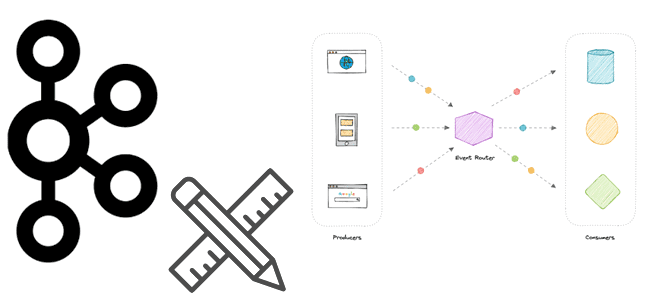
Будучи распределенной платформой передачи событий, Apache Kafka часто используется для построения архитектуры, управляемой событиями (EDA, Event Driven Architecture). Разбираемся, что такое событие и как его спроектировать, чтобы воплотить идеи EDA с Kafka. Проектирование событий для Apache Kafka В общем смысле событие – это свершившийся факт. В EDA-архитектуре события используются различными...
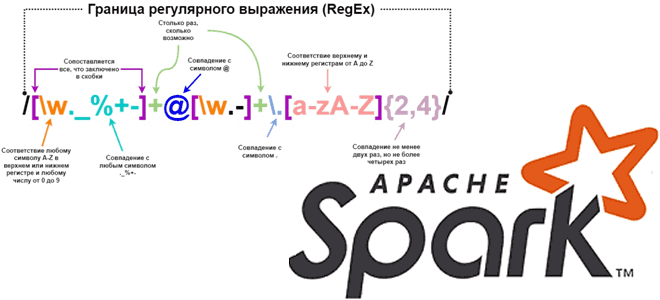
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения. Как работает функция regexp_replace() Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например,...
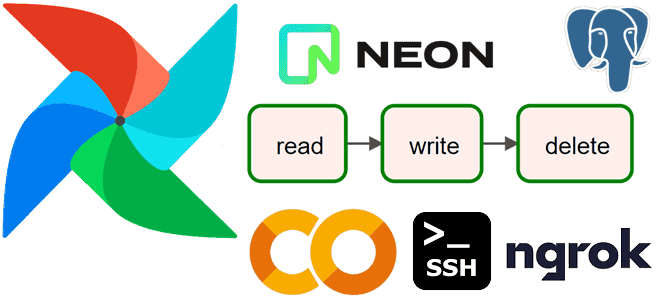
Сегодня усложним пример из прошлой статьи с простым ETL-конвейером, который добавлял в базу данных интернет-магазина новые записи о клиентах, сгенерированные с помощью библиотеки Faker. Разбираем, как удалить из PostgreSQL данные об успешно доставленных заказах за прошлый месяц, предварительно сохранив их в JSON-файл с многоуровневой структурой. Пишем и запускаем DAG Apache...
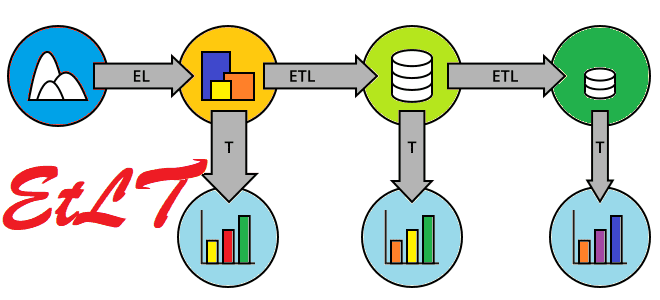
Как развивалась архитектура конвейеров обработки данных, что такое EtLT и почему этот подход почему постепенно заменяет классические ETL и ELT-инструменты. Краткая история развития современной дата-инженерии. От ETL к ELT и обратно: предыстория Архитектура конвейеров обработки данных претерпела несколько итераций от ETL, ELT, XX ETL (Reverse ETL, Zero-ETL) до EtLT. Если экосистема...