
Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions. Apache Flink Stateful Functions Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для...

Опубликованная впервые в 2016 году 1-ая версия Apache NiFi дополняется новыми минорными релизами, последним из которых стал 1.23.2, исправляющий ошибки предыдущих выпусков. Однако, в обозримом будущем ожидается мажорный релиз 2.0 со множеством новых возможностей. Разбираемся с его наиболее перспективными предложениями. ТОП-10 целей Apache NiFi 2.0 Чтобы повысить безопасность, снизить сложность...
Какие ошибки и угрозы нарушения безопасности были обнаружены в Apache AirFlow в 2023 году: обзор уязвимостей и способы их устранения. 9 уязвимостей среднего уровня серьезности В текущем году в Apache AirFlow было обнаружено 15 уязвимостей разной степени критичности. К наименее серьезным с маркировкой Medium и оценкой от 4 до 6.9...
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования. Сжатие сообщений в Kafka: причины использования и принципы работы Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...

Как разница между Scala и Java отражается на работе Spark-приложения, почему код на Scala работает быстрее и когда выбирать этот язык программирования для разработки приложений аналитики больших данных. Scala vs Java: ключевые отличия Хотя Apache Spark позволяет разработчику писать код на нескольких языках программирования (Scala, Java, R, Python), сам фреймворк...
Как включить сжатие данных в Greenplum, какие алгоритмы сжатия поддерживает эта MPP-СУБД и можно ли установить разные параметры сжатия для отдельных столбцов и разделов больших таблиц. Примеры SQL-запросов и рекомендацию по настройке. Как Greenplum сжимает данные: примеры настроек и SQL-запросов Эффективное сжатие данных позволяет Greenplum снижать потребление памяти и повышать...
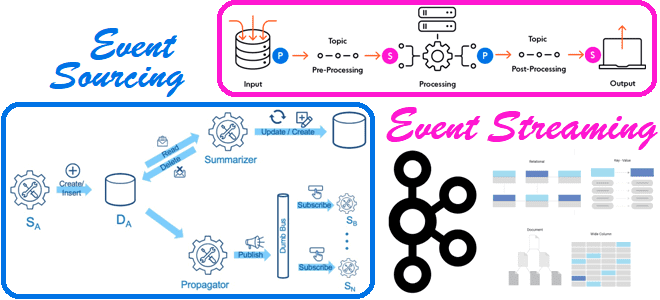
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...
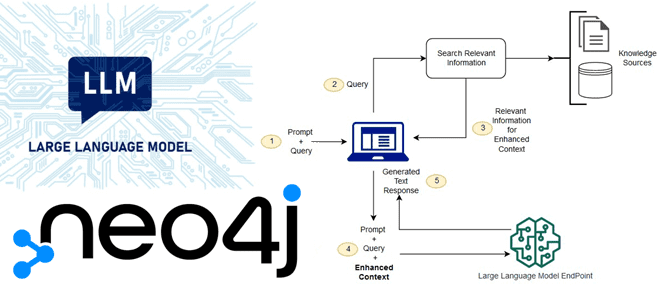
Что не так с большими языковыми моделями, как RAG-приложения расширяют возможности LLM и зачем в графовой СУБД Neo4j добавлена поддержка векторного индекса. Зачем нужны RAG-приложения: ограничения базовых LLM-сетей С появлением ChatGPT и других генеративных нейросетей, большие языковые модели (LLM, Large Language Models) стали активно применяться для решения множества бизнес-задач, связанных...
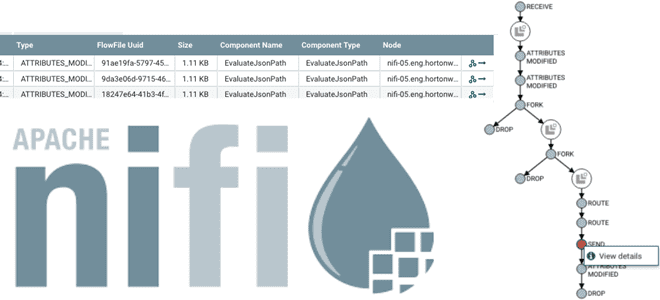
Недавно мы писали про спецификацию OpenLineage, которая позволяет обеспечить мониторинг происхождения данных в Apache AirFlow. Сегодня рассмотрим, в чем разница Data Lineage и Data Provenance, а также, как потоковый маршрутизатор Apache NiFi организует отслеживание событий генерации и изменения данных. Data Lineage vs Data Provenance Сначала рассмотрим, чем отличается Data Provenance...

13 сентября 2023 года вышел Apache Spark 3.5. Знакомимся с самыми важными новинками свежего релиза: расширения Spark Connect и SQL, поддержка DeepSpeed, улучшения потоковой передачи и свежие UDF-функции Python. ТОП-5 новинок Apache Spark 3.5.0 В Apache Spark 3.5. добавлено много исправлений и улучшений, а также реализованы новые функции. Наиболее интересными...
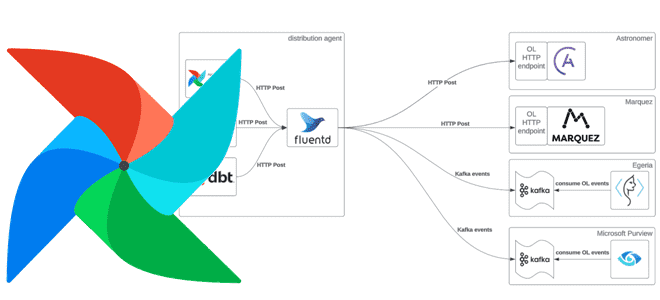
Как Apache AirFlow отслеживает происхождение данных, какова структура спецификации OpenLineage, чем она схожа с OpenAPI, какие инструменты позволяют сформировать эту документацию и чем она полезна. Что такое OpenLineage В области инженерии данных и управления конвейерами их обработки очень важно понятие происхождения данных (Data Lineage). Это концепция отслеживания и визуализации данных...
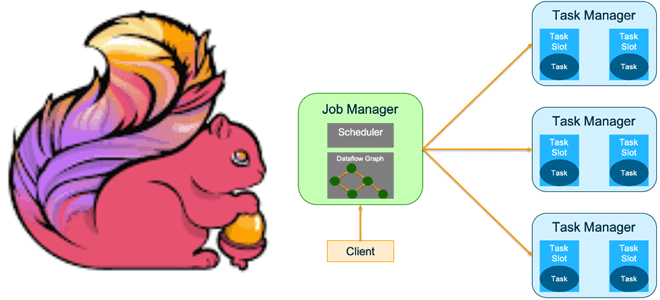
Какие режимы развертывания заданий поддерживает Apache Flink и чем они отличаются. Достоинства и недостатки режима сеанса и режима приложения, а также варианты использования. Особенности развертывания приложения Apache Flink Режим развертывания определяет, с каким уровнем изоляции ресурсов задание Flink будет выполняться в кластере. Напомним, выполнение задания Apache Flink включает 3 объекта:...

Как тестировать пользовательские процессоры и службы контроллера Apache NiFi: знакомимся с методами интерфейса TestRunner в модуле nifi-mock. Как создать тестовый объект, настроить его и проверить валидность работы собственного компонента Apache NiFi. Тестирование компонентов Apache NiFi: создание тестовых объектов и их настройка Будучи разработанным на Java, Apache NiFi позволяет использовать возможности...
Что такое AsyncAPI, зачем документировать спецификацию для EDA-архитектур и как это сделать. Создаем свою спецификацию для Apache Kafka с помощью веб-инструмента AsynсAPI Studio. Что такое AsyncAPI Подобно тому, как Swagger (OpenAPI ) стал стандартом де-факто для описания синхронного REST API, включая HTTP-методы запросов и ответы приложения на них со структурами...

Сегодня рассмотрим, какие улучшения Apache Spark опубликованы в 2023 году и как подать свое предложение по улучшению самого популярного вычислительного движка в стеке Big Data. Что такое SPIP и как подать свое предложение по улучшению фреймворка В любом продукте помимо ошибок есть также предложения по улучшению. В Apache Spark они...

Как организовать миграцию схемы Neo4j и импортировать в графовую базу данные из реляционных систем. Знакомимся с инструментами проекта Neo4j Labs: Neo4j-ETL и Neo4j-Migrations. Как работает Neo4j-ETL В рамках развития своих продуктов, таких как графовая СУБД Neo4j и экосистема элементов вокруг нее (Graph Data Science, Neo4j Bloom, Neo4j Browser и пр.),...

Чем отличается оркестрация ETL-процессов в Databricks и Apache AirFlow: принципы работы, достоинства и недостатки, а также что выбирать дата-инженеру для решения практических задач. Apache AirFlow vs Spark в Databricks: сходства и отличия Облачная платформа Databricks, основанная на Apache Spark, предлагает пользователям единую среду для создания, запуска и управления различными рабочими...

Почему в Greenplum 7 восстановление данных из резервной копии базы стало медленнее и как разработчики это исправили: причины замедления и способы их устранения. SQL-синтаксис и восстановление из бэкапа Напомним, 7-ой релиз Greenplum имеет много интересных и полезных функций, включая возможность определять партиционированную таблицу без определения дочерних разделов и изменять таблицы...

Зачем разработчики MLflow внедрили в этот MLOps-фреймворк инструмент оптимизации использования и управления различными провайдерами больших языковых моделей, чем он полезен и как использовать AI Gateway от Databricks. Что такое MLflow AI Gateway и зачем это нужно Напомним, MLflow от Databricks представляет собой платформу с открытым исходным кодом, которая помогает управлять...