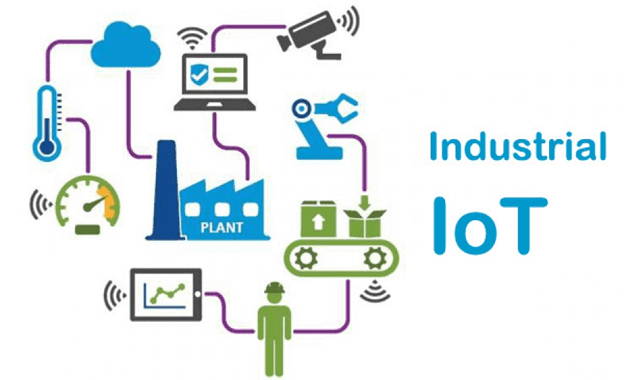
Мы уже рассказывали, как интернет вещей (Internet of Things, IoT) вместе с технологиями Big Data и машинного обучения (Machine Learning) используются в нефтегазовой, транспортной, сельскохозяйственной и машиностроительных отраслях. Сегодня поговорим подробнее про промышленный IoT (Industrial Internet of Things, IIoT) на примерах его применения в тяжелом машиностроении и рассмотрим, почему индустриальный...

Продолжая тему «умного» города (data-driven city), сегодня мы собрали для вас 5 практических примеров, как в крупнейших мегаполисах по всему миру интернет вещей и большие данные с датчиков, проездных билетов и дорожных камер помогают бороться с пробками и улучшать состояние дорог, повышая уровень их безопасности и удобства использования. Internet of...
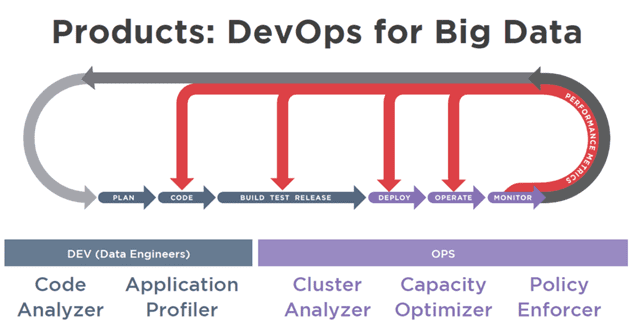
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного...

Цифровизация различных прикладных отраслей продолжается - сегодня мы нашли для вас интересные кейсы, как большие данные, машинное обучение и интернет вещей используется в жилой и коммерческой недвижимости. Чем Big Data, Machine Learning и Internet Of Things (IoT) полезны строителям и риелторам, и каким образом внедрение этих технологий поможет потребителям. Big...

Цифровизация возможна не только на предприятиях. Цифровая трансформация настигает даже города, чтобы сделать их более удобными для жителей и менее вредными для планеты. Сегодня мы подготовили для вас 8 интересных примеров по 4 разным направлениям об использовании больших данных (Big Data), машинного обучения (Machine Learning) и интернета вещей (Internet of...

Даже после очистки и нормализации данных, выборка еще не совсем готова к моделированию. Для машинного обучения (Machine Learning) нужны только те переменные, которые на самом деле влияют на итоговый результат. В этой статье мы расскажем, что такое отбор или выделение признаков (Feature Selection) и почему этот этап подготовки данных (Data...

Мы уже рассказали, что такое нормализация данных и зачем она нужна при подготовке выборки (Data Preparation) к машинному обучению (Machine Learning) и интеллектуальному анализу данных (Data Mining). Сегодня поговорим о том, как выполняется нормализация данных: читайте в нашем материале о методах и средствах преобразования признаков (Feature Transmormation) на этапе их...

Нормализация данных – это одна из операций преобразования признаков (Feature Transformation), которая выполняется при их генерации (Feature Engineering) на этапе подготовки данных (Data Preparation). В этой статье мы расскажем, почему необходимо нормализовать значения переменных перед тем, как запустить моделирование для интеллектуального анализа данных (Data Mining). Что такое нормализация данных и чем она...

Извлечение признаков (Feature Extraction) из текста – часто встречающаяся задача Data Mining, а именно этапа генерации признаков. Интеллектуальный анализ текста получил название Text Mining. В этом случае Feature Extraction относится к сфере NLP, Natural Language Processing – обработка естественного языка. Это отдельное направление искусственного интеллекта и математической лингвистики [1]. Здесь...

Генерация признаков – пожалуй, самый творческий этап подготовки данных (Data Preparation) для машинного обучения (Machine Learning). Этот этап еще называют Feature Engineering. Он наступает после того, как выборка сформирована и очистка данных завершена. В этой статье мы поговорим о том, что такое признаки, какими они бывают и как Data Scientist...

Выборка, полученная в результате первого этапа подготовки данных (Data Preparation), еще пока не пригодна для обработки алгоритмами машинного обучения, поскольку информацию необходимо очистить. Сегодня мы расскажем, что такое очистка данных (Data Cleaning) для Data Mining, зачем она нужна и как выполнять этот этап Data Preparation. Что такое очистка данных для...
Мы уже рассказывали о важности этапа подготовки данных (Data Preparation), результатом которого является обработанный набор очищенных данных, пригодных для обработки алгоритмами машинного обучения (Machine Learning). Такая выборка, называемая датасет (dataset), нужна для тренировки модели Machine Learning, чтобы обучить систему и затем использовать ее для решения реальных задач. Однако, поскольку в...

CRISP-DM, SEMMA и другие стандарты Data Mining не случайно выделяют подготовку данных в отдельную фазу. Data Preparation - весьма трудоемкий итеративный процесс, который занимает до 80% всех затрат ресурсов и времени в жизненном цикле Data Mining и включает следующие задачи обработки исходных («сырых») данных [1]: Выборка данных – отбор признаков...

Интернет вещей (Internet Of Things) считает покупателей торговых центров, а средства больших данных (Big Data) и машинного обучения (Machine Learning) превращают эти цифры в реальную выгоду для бизнеса. Мы нашли еще 5 примеров успешного использования этих технологий в ритейле и делимся с вами опытом отечественных и зарубежных компаний. Интернет вещей...

Мы уже описывали, как американская торговая сеть Macy’s успешно использует интернет вещей (Internet Of Things) для персонализированного маркетинга. Bluetooth-маячок определяет местоположение посетителя в магазине с точностью до нескольких сантиметров и подает сигнал в корпоративную CRM-систему. CRM отправляет клиенту на смартфон предложение со скидкой на товар, ближайший к потребителю в данный момент [1]. Сегодня мы...

Мы уже рассказывали, зачем HR-специалисту большие данные, как Big Data и Machine Learning помогают PR-менеджеру в управлении корпоративной репутацией, а маркетологу в формировании персональных рекламных предложений. Сегодня поговорим об одном из средств реализации этих и других бизнес-задач – языке программирования R и рассмотрим 7 причин, почему вам необходимо освоить этот...

Недавно мы рассказывали, зачем HR-специалисту большие данные, как быстро и эффективно внедрить Big Data в управление персоналом, а также описывали случаи интеллектуального рекрутинга с помощью машинного обучения. В продолжение этой темы сегодня мы приготовили для вас 5 интересных кейсов от отечественных и зарубежных компаний по 3 HR-направлениям: управление талантами, повышение...

Мы уже описывали, зачем HR-специалисту большие данные, а также как быстро и эффективно внедрить Big Data в управление персоналом на практике. Сегодня расскажем о конкретных случаях применения этих технологий в HR: успешные кейсы отечественных и зарубежных компаний. Роботы-рекрутеры Сервис автоматизированного рекрутинга, разработанный российской компанией Stafory, позволяет в 10 раз сократить...

Иван Гуз, директор по аналитике и клиентскому сервису Avito, 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе компании [1] рассказал о самых главных проблемах, которые подстерегают исследователя данных на практических проектах и от чего не убережет даже подробно проработанный стандарт CRISP-DM. Из его...

Посмотрев выступление Станислава Гафарова [1], руководителя направления по развитию ИТ-систем АО «СберТех», от 24.04.2018 на митапе AI Community и AI Today для специалистов по Data Science в офисе Авито [2], мы составили ТОП-7 ошибок при работе с данными по методологии CRISP-DM. На основании жизненного цикла работы с информацией по стандарту...