
Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...
Вчера мы упоминали, как долгожданный KIP-500, реализованный в марте 2021 года, позволяет не только отказаться от Zookeeper в кластере Apache Kafka, но и снимает ограничение числа разделов, чтобы масштабировать брокеры практически до бесконечности. Однако, не все так просто: читайте далее, какие важные функции еще не поддерживаются в этом экспериментальном режиме...
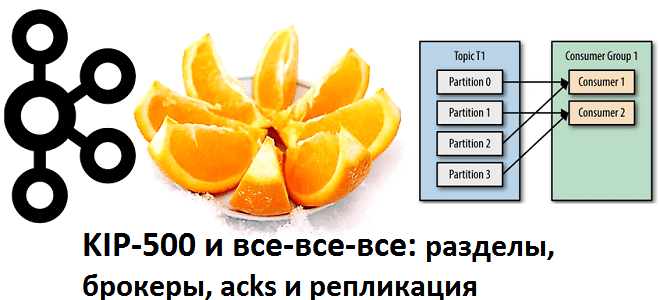
Сегодня рассмотрим важную практическую задачу из курсов Kafka для разработчиков и администраторов кластера – разделение топиков по брокерам. Читайте далее, как пропускная способность всей Big Data системы зависит от числа разделов, коэффициента репликации и ответного ack-параметра, а также при чем здесь KIP-500, позволяющий отказаться от Zookeeper. Что такое партиционирование в...
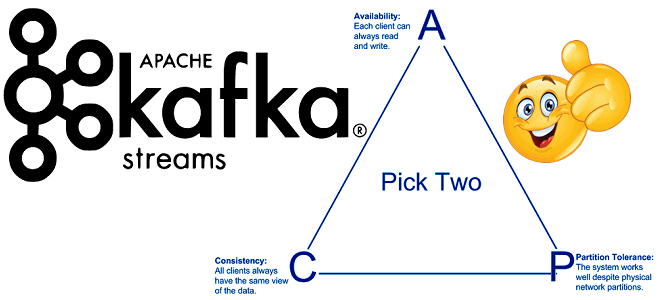
Продолжая включать интересные практические примеры в наши курсы Apache Kafka для разработчиков, сегодня поговорим о согласованности в распределенных системах с высокой доступностью. Читайте далее, что такое eventual consistency, почему это важно для микросервисной архитектуры, при чем здесь ограничения CAP-теоремы и как решить проблемы обеспечения конечной согласованности с Kafka Streams. ...
Чтобы сделать наши курсы по Apache Kafka еще более полезными, сегодня мы поговорим про базовые и расширенные возможности обеспечения информационной безопасности этой Big Data платформы. А в качестве практического примера разберем кейс международной финтех-компании BlackRock, которая разработала собственное security-решение для Kafka на базе протокола OAuth и серверов единого доступа KeyCloak....

В феврале 2021 года разработчики корпоративной версии Apache Kafka с коммерческой поддержкой, компания Confluent, выпустили премиум-коннектор к Oracle – одной из главных реляционных баз данных мира enterprise. Разбираемся, кому и зачем это нужно, а также как устроена такая интеграция SQL-СУБД и потоковой аналитики Big Data с применением CDC-подхода. Реляционный монолит...

Постоянно добавляя в наши курсы Apache Kafka для разработчиков интересные и практические примеры, сегодня мы разберем кейс тревел-площадки Trainline, которая агрегирует данные от 270 железнодорожных и автобусных компаний в 45 странах, предлагая выгодные билеты на европейские поезда и автобусы. Читайте далее, почему пакетный режим работы озера данных перестал отвечать требованиям...

Сегодня рассмотрим пример построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data. Читайте далее о преимуществах облачного Delta Lake от Databricks над традиционным Data Lake. Постановка задачи: финансовая...

Спустя пару месяцев с выпуска Apache Kafka 2.7.0, Confluent анонсировал новый релиз этой платформы потоковой передачи событий, в котором, наконец, случится долгожданный отказ от Zookeeper. Читайте далее, как это облегчит жизнь администратору Kafka-кластера и разработчику распределенных приложений потоковой аналитики больших данных, а также как подготовить свою Big Data инфраструктуру к...

В конце декабря 2020 года вышел новый релиз Apache Kafka – главной Big Data технологии для потоковой передачи событий, интеграции распределенных систем и аналитики больших данных. Читайте далее о новых функциональных возможностях и исправленных ошибках в свежей версии 2.7.0: еще один шаг к отказу от Zookeeper, генерация уведомительных исключений и улучшения...
Продолжая разговор про обучение разработчиков Apache Kafka, сегодня рассмотрим, чем ksqlDB отличается от Kafka Streams. Также читайте далее про основные достоинства и недостатки перезапуска KSQL в виде отдельной базы данных потоковой передачи событий с API-интерфейсом на основе SQL для запроса и обработки информации из топиков Kafka. ksqlDB vs Kafka Streams:...
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL. Apache Kafka...

Хорошие курсы инженеров данных – это не просто обучение отдельной Big Data технологии, такой как Apache Hadoop, Spark или Kafka, а жизненные примеры их практического использования в реальном бизнесе. Поэтому сегодня мы приготовили для вас кейс оптимизации стоимости и скорости OLAP-аналитики больших данных в облачном Delta Lake на Amazon Web...

Продвигая наши курсы для разработчиков Spark с примерами реальных систем аналитики больших данных, сегодня рассмотрим библиотеку для чтения файлов формата DICOM от индийской компании Abzooba. Читайте далее, как автоматизировать поиск по миллиардам медицинских изображений с помощью машинного обучения и технологий Big Data: Apache Spark, Hadoop, Kafka, Elasticsearch и Kibana. Что...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...
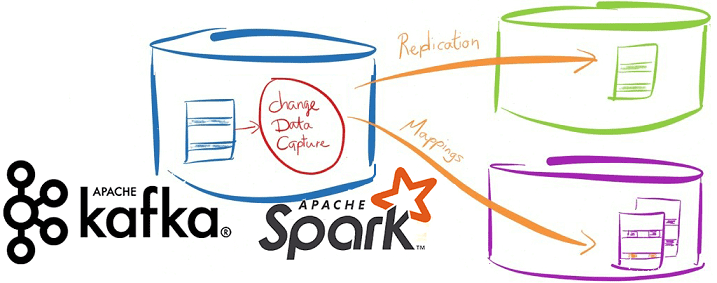
Вчера мы упоминали про CDC-подход в проектировании транзакционных систем аналитики больших данных на базе Apache Kafka и Spark Streaming. Сегодня рассмотрим подробнее примеры такого применения технологий Big Data и лучшие практики Change Data Capture в потоковой обработке финансовых и других транзакций. Зачем нужны потоковые конвейеры транзакционной обработки Big Data на...

В этой статье рассмотрим особенности совместного использования Apache Kafka и Spark Streaming для обработки финансовых транзакций в режиме онлайн. Читайте далее про типовые кейсы практического применения конвейера аналитики больших данных на базе Kafka и Spark, а также проблемы или технологические особенности такой Big Data системы и пути обхода этих ограничений....

В заключение цикла статей о сравнении Apache Kafka с Pulsar, сегодня мы перечислим, когда следует предпочесть второй вариант для построения распределенных масштабируемых систем потоковой аналитики больших данных. Также читайте далее, с какими ограничениями придется мириться в случае выбора этого Big Data фреймворка. 5 случаев, когда Apache Pulsar лучше Kafka При...

Вчера мы опровергали мифы о превосходстве молодого Apache Pulsar над зрелой Kafka, наглядно показав, что именно второй Big Data фреймворк больше подходит для построения по-настоящему масштабных и высоконадежных распределенных масштабируемых систем потоковой аналитики больших данных. Тем не менее, благодаря своим архитектурным особенностям Pulsar постепенно завоевывает собственную нишу и становится все...