
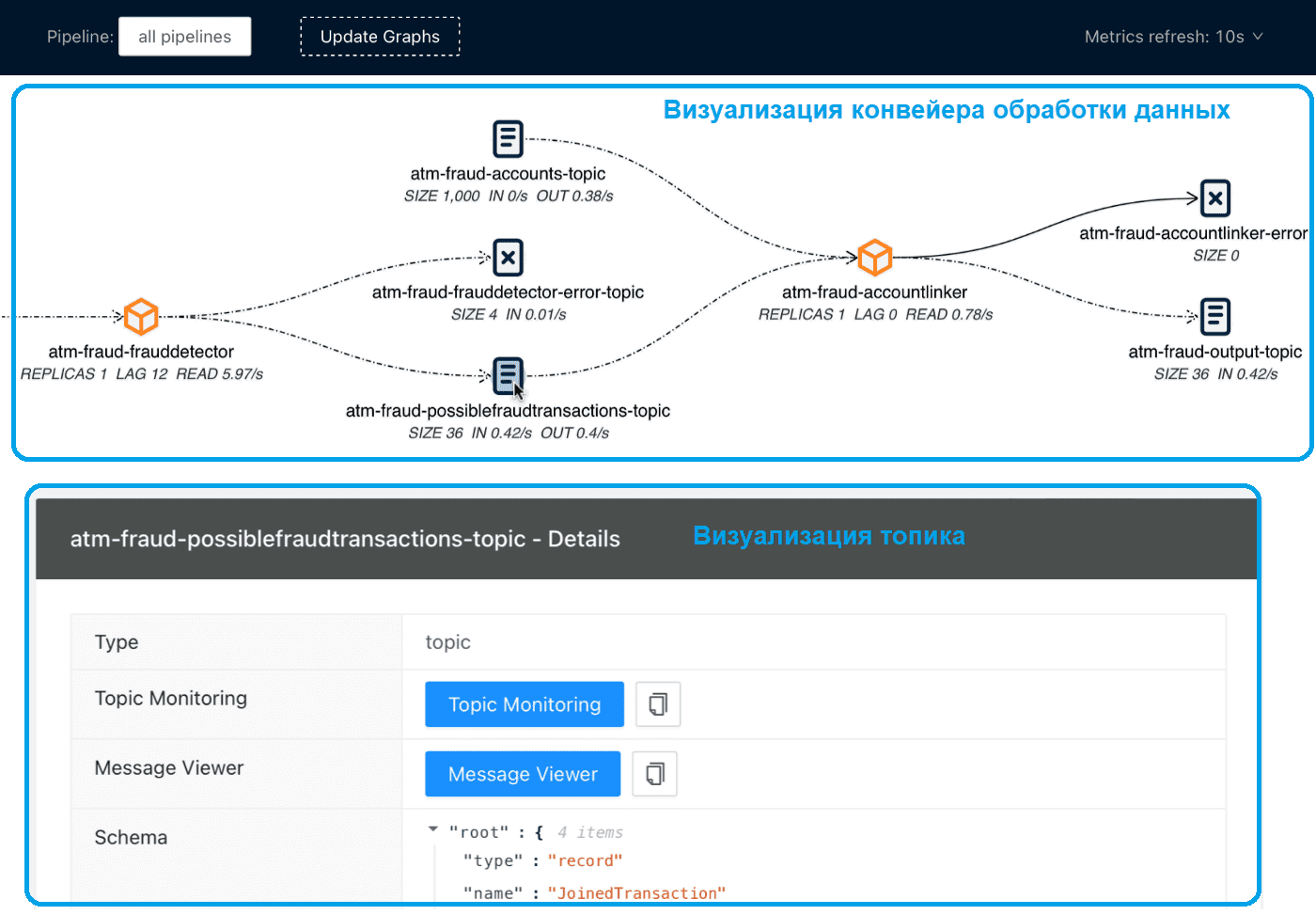
Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера.
Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams
При работе с крупномасштабными потоковыми данными крайне важно отслеживать конвейеры их обработки как целиком, так и в разрезе отдельных компонентов. В частности, дата-инженеру и администратору кластера Apache Kafka важно следить за состоянием брокеров, приложений-продюсеров и потребителей, чтобы обеспечить бесперебойную обработку данных. Для этого есть множество инструментов мониторинга системных метрик, например, Confluent Control Centre, Lenses, Datadog Kafka Dashboard, Cloudera Manager, CMAK, KafDrop, LinkedIn Burrow и Kafka Tool а также платформа Iris. О том, как они работают, мы писали здесь и здесь.
Несмотря на довольно обширный перечень указанных инструментов и их аналогов, спрос на подобные средства рождает предложения и на рынке появляются новые. К примеру, Streams Explorer от Bakdata позволяет исследовать конвейеры данных Apache Kafka в кластере Kubernetes, включая проверку схем и мониторинг метрик. Это проект с открытым исходным кодом, который отлично подходит для приложений, которые разворачиваются с использованием streams-bootstrap или faust-bootstrap.
Streams-bootstrap тоже является открытым проектом компании Bakdata и предоставляет базовые классы и служебные функции для приложений Kafka Streams. Он обеспечивает общий способ настройки приложений Kafka Streams, включая развертывание потоковых приложений в Kubernetes с помощью диаграмм Helm и средства повторной обработки данных. Проект faust-bootstrap также разработан компанией Bakdata и представлен на Github как реализация оболочки библиотеки Faust. Он использует тот же интерфейс, что и проект common-kafka-streams, и может быть развернут с использованием той же диаграммы Helm и параметров конфигурации. Таким образом, используя наработки Bakdata, можно разрабатывать свои приложения Kafka на Java или Python, не прибегая к различным конфигурациям развертывания.
Streams Explorer автоматизирует визуализацию и мониторинг потоковых приложений и топиков без ручного поиска в Kubernetes, предоставляя следующие функциональные возможности:
- визуализация потоковых приложений, топиков и коннекторов;
- мониторинг всех или некоторых конвейеров из нескольких пространств имен;
- проверка схемы AVRO из реестра схем;
- интеграция со streams-bootstrap и faust-bootstrap или анализ конфигурации пользовательского приложения потоковой передачи из развертываний Kubernetes с использованием плагинов;
- метрики в реальном времени от Prometheus (задержка потребителя и скорость чтения, реплики, размер топика, входящие и исходящие сообщения в секунду, задачи коннектора);
- интеграция с внешними сервисами для регистрации и анализа, такими как Kibana, Grafana, Loki, AKHQ, Redpanda Console и Elasticsearch.
По умолчанию Streams Explorer показывает все конвейеры данных, состоящие из Java-приложений streams-bootstrap или Python-приложений faust-bootstrap, развернутых в одном или нескольких пространствах имен Kubernetes. Рекомендуется именовать отдельные конвейеры с помощью метки конвейера в развертываниях Kubernetes, что особенно важно для больших систем. Без явного именования конвейер данных по умолчанию именуется в соответствии с одним потоковым приложением в конвейере. Узлы потоковых приложений показывают текущую задержку потребителя и количество реплик для развертывания. Поскольку нельзя напрямую сказать, какая группа потребителей принадлежит определенному приложению, нужно установить аннотацию ConsumerGroup для развертывания приложения.
Настройка Streams Explorer достаточно проста: можно развернуть его в кластере Kubernetes, используя диаграмму Helm:
helm repo add streams-explorer https://raw.githubusercontent.com/bakdata/streams-explorer/v1.0.3/helm-chart/ helm install --values helm-chart/values.yaml streams-explorer
При развертывании Streams Explorer в кластере по умолчанию создается учетная запись службы для доступа к Kubernetes API. Инструмент настраивается с помощью плагинов Python, где можно создать свой собственный анализатор конфигурации, компоновщик, поставщик метрик и экстракторы, реализуя классы K8sConfigParser, LinkingService, MetricProvider или Extractor.
Если развертывание потокового приложения настроено с помощью переменных среды, следуя схеме streams-bootstrap или faust-bootstrap, Streams Explorer работает по умолчанию с парсером развертывания по умолчанию. Для развертываний с потоковой загрузкой, настроенных с помощью аргументов CLI, можно загрузить отдельный парсер, создав файл Python, например, config_parser.py, в папке плагинов со следующим оператором импорта: из streams_explorer.core.k8s_config_parser импортировать StreamsBootstrapArgsParser.
Для других настроек можно создать собственный плагин для парсинга конфигурации, наследуя от класса K8sConfigParser и реализуя метод синтаксического анализа. Конфигурации потокового приложения можно извлекать из внешнего REST API, используя входные и выходные топики Kafka для идентификации развертывания как потокового приложения. В заключение отметим, что Streams Explorer визуализирует потоковые конвейеры и топики Apache Kafka в наглядном веб-интерфейсе.
Больше подробностей про администрирование и эксплуатацию Apache Kafka в системах аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

