
Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим, что представляет собой облачная платформа VMware Tanzu Greenplum, где ее можно развернуть и каковы преимущества cloud-решения по сравнению с локальной версией этой MPP-СУБД. Что такое VMware Tanzu Greenplum и чем это отличается от open-source версии Напомним, в 2020 году корпорация...

Чтобы добавить в наши курсы для дата-инженеров по технологиям Apache Kafka, Spark, AirFlow, NiFi, Flink и Greenplum, еще больше практических примеров, сегодня разберем кейс ритейлера Леруа Мерлен. Читайте далее, как сотрудники российского отделения этой международной компании интегрировали в единую платформу более 350 реляционных СУБД и NoSQL-источников с помощью CDC-подхода на...

Продвигая наши курсы по Greenplum и Arenadata DB, сегодня рассмотрим пару полезных лайфхаков, как избежать избыточного потребления памяти, настроив конфигурационные параметры операционной системы хоста. Читайте далее, почему не стоит задавать слишком большой размер страниц виртуальной памяти, зачем администратору контролировать количество spill-файлов и как в этом помогает утилита gp_toolkit. Операционная система...

Хотя наши практические курсы по Greenplum и Arenadata DB больше ориентированы на аналитиков и дата-инженеров, чем на администраторов, в программы обучения также включены важные сведения по настройке этих MPP-СУБД. В этой статье мы собрали лучшие практики системного конфигурирования кластера Greenplum, которые помогут повысить эффективность аналитики больших данных в этой Big...
В рамках программы курсов по Greenplum и Arenadata DB, сегодня рассмотрим важную для разработчиков и администраторов тему об особенностях оптимизатора SQL-запросов GPORCA, который ускоряет аналитику больших данных лучше встроенного PostgreSQL-планировщика. Читайте далее, как выбирать ключ дистрибуции, почему для GPORCA важна унифицированная структура многоуровневой партиционированной таблицы и каким образом оптимизаторы обрабатывают...

Поскольку Greenplum и Arenadata DB основаны на популярной open-source СУБД PostgreSQL, сегодня разберем, чем они отличаются от этой объектно-реляционной базы данных. Далее вас ждет краткий и понятный ответ на вопрос Greenplum vs PostgreSQL: сходства и отличия этих систем с учетом аналитики больших данных и практических кейсов дата-инженерии. Что общего между...

Обучая разработчиков и администраторов Greenplum, а также в рамках продвижения курсов по Arenadata DB, сегодня рассмотрим, как SQL-оптимизатор ORCA ускоряет аналитику больших данных, позволяя реализовать многостороннее соединение таблиц через JOIN-запросы. Читайте далее, что такое GPORCA, как его использовать, насколько он эффективен по сравнению с другими планировщиками SQL-запросов в этой MPP-СУБД...

Мы уже рассказывали про коннектор Greenplum-Spark, 2-я версия которого вышла в октябре 2020 года. А сегодня рассмотрим российскую альтернативу для отечественной MPP-СУБД Arenadata DB на базе Greenplum, выпущенную компанией Аренадата в июле 2021 года. Краткий обзор ADB-Spark Connector: архитектура, принципы работы, сценарии использования, а также отличия от PXF-фреймворка и варианта...

В недавней статье про оптимизацию SQL-запросов в Greenplum мы рассказывали про планы их выполнения и операторы просмотра этих планов. Сегодня разберем подробнее, какие операции с данными могут встретиться в отчете, сгенерированном командой EXPLAIN, а также рассмотрим, чем эта информация полезна дата-инженеру и аналитику данных. 5 операций в плане выполнения SQL-запросов...
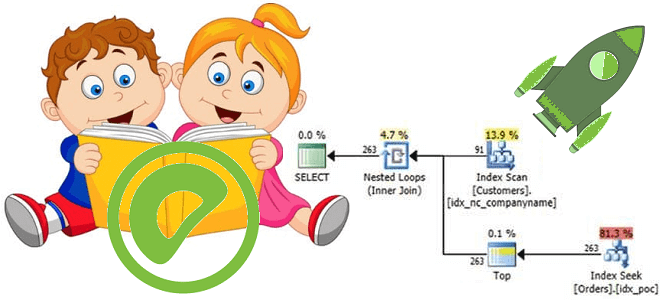
Обучая дата-аналитиков и инженеров данных тонкостям MPP-СУБД Greenplum, сегодня разберем, какой оператор помогает просмотреть план выполнения SQL-запроса, почему добавлять ANALYZE к EXPLAIN нужно с осторожностью и где найти универсальное решение анализа и визуализации PostgreSQL-совместимых продуктов. Я все объясню: команда EXPLAIN в PostgreSQL Разобравшись с оператором анализа и сбора статистики по...