 1299
1299 
Содержание
В недавней статье про оптимизацию SQL-запросов в Greenplum мы рассказывали про планы их выполнения и операторы просмотра этих планов. Сегодня разберем подробнее, какие операции с данными могут встретиться в отчете, сгенерированном командой EXPLAIN, а также рассмотрим, чем эта информация полезна дата-инженеру и аналитику данных.
5 операций в плане выполнения SQL-запросов в Greenplum: практический пример
Напомним, просмотреть план выполнения SQL-запроса в Greenplum можно с помощью команды EXPLAIN как в рамках самой СУБД, так и с помощью сторонних сервисов анализа и визуализации. Например, открытый сервис российской компании «Тензор» – https://explain.tensor.ru/ для PostgreSQL-совместимых баз данных, к которым относится и Greenplum [1]. В итоге получим план выполнения запроса – отчет с подробным описанием шагов, которые определил оптимизатор СУБД, в виде дерева узлов, каждый из которых передает свой результат вышестоящему. На узле происходят операции с данными: сканирование, соединение, агрегирование или сортировка, которые могут быть выполнены различными методами.
Например, для запроса
SELECT gp_segment_id, count(*) FROM contributions GROUP BY gp_segment_id;
Получим в сервисе компании «Тензор» https://explain.tensor.ru/ следующий план выполнения [2]:
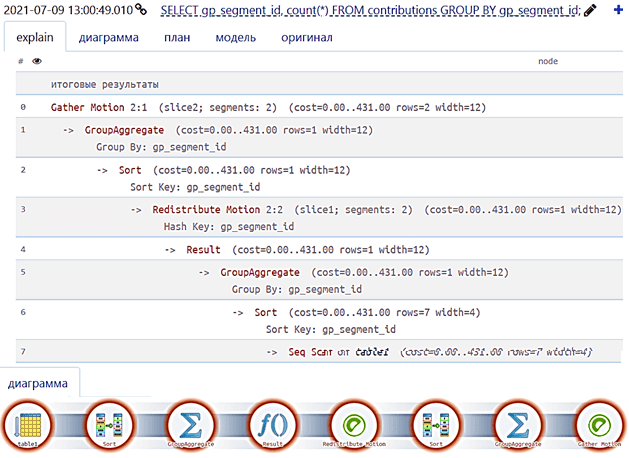
Рассмотрим подробнее, какие операторы используются на узлах полученного плана, начав с конца. Последний узел выполняет операцию сканирования оператором Seq Scan. Вообще в Greenplum используются следующие операторы сканирования [3]:
- Seq Scan – последовательное сканирование таблиц всех строк в таблице;
- Index Scan — просмотр индекса для извлечения строк из таблицы;
- Bitmap Heap Scan, который собирает указатели на строки в таблице из индекса и сортирует их по местоположению на диске;
- Dynamic Seq Scan, когда для сканирования выбираются отдельные разделы.
Результаты сканирования передаются вышестоящему узлу, где выполняется операция сортировки строк (Sort) в качестве подготовительного шага для другой операции, требующей упорядоченных данных. В частности, такой операцией и является агрегирование, которая выполняется на следующем шаге – GroupAggregate.
После этого выполняется перемещение данных (Redistribute motion), когда каждый сегмент Greenplum повторно хеширует данные и отправляет строки в разные сегменты в соответствии с хеш-ключом. Помимо Redistribute motion в Greenplum бывает еще 2 вида операций перемещения строк между сегментами [3]:
- Broadcast motion — каждый сегмент отправляет свои собственные отдельные строки всем другим сегментам, чтобы каждый экземпляр сегмента имел полную локальную копию таблицы. Этот вариант широковещательной рассылки не стол оптимален, как Redistribute motion, поэтому оптимизатор обычно выбирает Broadcast motion только для небольших таблиц. Если данные не были распределены по ключу соединения, выполняется динамическое перераспределение необходимых строк из одной из таблиц в другой сегмент.
- Gather motion — данные результатов со всех сегментов собираются в единый поток. Это последняя операция для большинства планов запросов, что мы и видим на нашем примере.
Кроме операций, которые присутствуют в нашем примере, в плане выполнения SQL-запроса Greenplum можно встретить и другие, которые мы разберем далее.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Что еще можно встретить в отчете оператора EXPLAIN
JOIN-соединение найденных строк Greenplum выполняют следующие операторы [1]:
- Hash Join – самый быстрый вариант, который строит хеш-таблицу из меньшей таблицы со столбцом соединения в качестве хеш-ключа. Далее он сканирует большую таблицу, вычисляя хэш-ключ для столбца соединения, чтобы найти строки в хэш-таблице с тем же хеш-ключом.
- Nested Loop — вложенный цикл, который итеративно выполняет операции со строками в большем наборе данных, просматривая строки в меньшей таблице на каждой итерации. Такие соединения требуют широковещательной передачи одной из таблиц, чтобы все ее строки можно было сравнить со всеми строками в другой таблице. Этот вариант хорошо работает с таблицами, небольшими по размеру или ограниченными индексом, используется для декартовых и диапазонных соединений. При работе с большими таблицами возникают проблемы с производительностью, поэтому рекомендуется установить параметр конфигурации сервера enable_nestloop в значение OFF, чтобы использовать Hash Join.
- Merge Join — сортирует оба набора данных и соединяет их вместе. Этот вариант выполняется быстро для предварительно упорядоченных данных, но редко применяется на практике. Чтобы использовать по умолчанию его вместо Hash Join, нужно задать для параметра конфигурации enable_mergejoin значение ON.
Также в планах выполнения SQL-запроса Greenplum можно встретить следующие операторы [3]:
- Materialize — планировщик материализует подвыборку один раз, чтобы не повторять это для каждой строки верхнего уровня;
- InitPlan — предварительный запрос при динамическом удалении разделов, если планировщику до времени выполнения неизвестны значения, необходимые для определения разделов сканирования;
- Group By — группирует строки по одному или нескольким столбцам;
- Group/Hash Aggregate — объединяет строки с помощью хэша;
- Append— объединяет наборы данных, например, при соединении строк, отсканированных из разделов в таблице с большим количеством разделов;
- Filter — выбирает строки по критериям условия WHERE;
- Limit— ограничивает количество возвращаемых строк.
В заключение отметим, что использовать LIMIT надо с осторожностью. Добавление этого уточнения, изменит выдачу результата. Если указывается число LIMIT, вернется не более заданного числа строк. Применяя LIMIT, важно использовать также условие ORDER BY, чтобы строки результата выдавались в определённом порядке. Иначе будут возвращаться непредсказуемые подмножества строк. Оптимизатор запроса учитывает ограничение LIMIT, строя планы выполнения запросов. Различные значения LIMIT, выбирающие разные подмножества результатов запроса, приведут к несогласованности результатов, если не установить предсказуемую сортировку с помощью ORDER BY. Это неизбежное следствие того, что SQL не гарантирует вывод результатов запроса в некотором порядке, если порядок не определён явно условием ORDER BY [4]. Почему включение оператора сортировки ORDER BY в запросы может стать причиной генерации чрезмерного количества spill-файлов, мы рассказываем здесь. А больше подробностей про SQL-оптимизатор GPORCA в Greenplum читайте в нашей новой статье.
Узнайте больше про администрирование и эксплуатацию Greenplum и Arenadata DB для эффективного хранения и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

