
Обучая разработчиков и администраторов Greenplum, а также в рамках продвижения курсов по Arenadata DB, сегодня рассмотрим, как SQL-оптимизатор ORCA ускоряет аналитику больших данных, позволяя реализовать многостороннее соединение таблиц через JOIN-запросы. Читайте далее, что такое GPORCA, как его использовать, насколько он эффективен по сравнению с другими планировщиками SQL-запросов в этой MPP-СУБД и причем здесь дискретная математика.
Что такое GPORCA и зачем это Greenplum
Соединение таблиц оператором JOIN считается одной из самых сложных операций в SQL-запросах. Особенно это утверждение характерно для распределенных систем, где соединяемые наборы данных могут находиться на разных узлах кластера. Чтобы сократить время выполнение JOIN-запроса оптимизатор СУБД применяет различные алгоритмы. Например, в Greenplum это может быть Hash или Merge JOIN, а также вложенный цикл (Nested Loop), о чем мы подробно рассказывали здесь. Однако, независимо от выбранного JOIN-алгоритма, время выполнения такого SQL-запроса растет с увеличением количества соединенных таблиц, что можно посмотреть в плане выполнения, который создает оптимизатор.
В Greenplum есть два оптимизатора: встроенный и сторонний ORCA-вариант, который называется GPORCA. Он работает намного быстрее, поэтому используется по умолчанию. Начиная с версии 6.13, GPORCA применяет методы динамического программирования для многосторонних соединений таблиц, а также использует «жадный» метод оптимизации, чтобы ускорить выполнение запроса. В Greenplum 6.14 оптимизатор GPORCA включает обновления, который еще более сокращают время оптимизации и улучшают планы выполнения SQL-запросов для больших соединений [1].
Вообще GPORCA расширяет возможности планирования и оптимизации планировщика PostgreSQL в средах с многоядерной архитектурой. В Greenplum оптимизатор GPORCA улучшает настройку производительности SQL-запросов к секционированным таблицам, а также CTE-запросы с общими табличными выражениями (Common Table Expression) и с подзапросами [2]. Чем еще Greenplum отличается от PostgreSQL, мы рассказываем здесь.
Greenplum для инженеров данных и аналитиков данных
Код курса
GPDE
Ближайшая дата курса
7 июля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
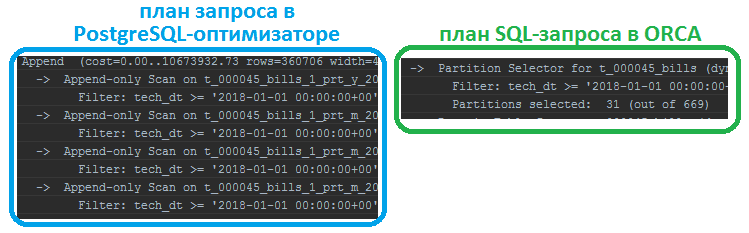
В отличие от традиционных SQL-оптимизаторов, ORCA поддерживает нисходящее управление, особенно эффективное для GROUP BY и оконных функций. Однако только для задачи перечисления соединений (enumerating joins) по-прежнему используется восходящий метод, т.к. для этого случая он работает лучше. По сравнению с PostgreSQL-оптимизатором, ORCA видоизменяет план запроса, в частности, по-другому отображает сканируемые партиции [3].
Оптимизатор может быть задан для всей СУБД, отдельной базы данных, сеанса или SQL-запроса через свойство optimizer, установленное в значение on: set optimizer = on.
Оптимизация JOIN-запросов: 3 главных фичи и дискретной немного математики
Наиболее значимыми GPORCA-новинками Greenplum 6.14 в оптимизации SQL-запросов с оператором JOIN, являются следующие:
- включение внешних соединений (OUTER JOIN), которые требуют больше вычислительных ресурсов, чем внутренние (INNER JOIN). Теперь все варианты JOIN-запросов (и внешние, и внутренние) поддерживает до 10 соединений таблиц, что актуально для OLAP-сценариев аналитики больших данных, для которых и предназначена Greenplum.
- исключение динамических разделов (DPE, Dynamic Ppartition Elimination), когда соединение с другой таблицей используется для удаления ненужных разделов. В этом случае в плане выполнения SQL-запроса особое внимание уделяется созданию порядка соединения, подходящего для DPE.
- возможность влияния на перечисление соединений (Join Enumeration) с помощью параметров конфигурации, которые мы подробнее рассмотрим далее.
На практике бывают ситуации, когда необходим регулируемый компромисс между оптимизацией SQL-запроса и временем его выполнения. В Greenplum для этого есть следующие параметры конфигурации [4]:
- optimizer_join_order – устанавливает уровень оптимизации запроса для упорядочивания соединений, типы альтернативных вариантов для оценки;
- optimizer_join_order_threshold – указывает максимальное количество дочерних элементов соединения, для которых GPORCA использует алгоритм упорядочивания соединений на основе динамического программирования. По умолчанию равно 10.
Параметр optimizer_join_order позволяет указать алгоритм перечисления соединений и может принимать следующие значения [1, 5]:
- query – использует порядок соединения, указанный в запросе;
- greedy – оценивает порядок соединения, указанный в запросе, и альтернативы на основе минимальной мощности отношений в соединениях, используя алгоритм жадного поиска, который выполняется быстро, но может привести к неоптимальным планам. Напомним, суть жадных алгоритмов сводится к принятию локально оптимальных решений на каждом этапе, что подходит для глобальной оптимизации задач, где результат складывается из отдельных независящих друг от друга шагов.
- exhaustive1 – применяет правила преобразования для поиска и оценки до настраиваемого порогового числа (optimizer_join_order_threshold) n-сторонних внутренних соединений, а затем изменяет и использует жадный метод поверх этого. В этот момент время планирования значительно сокращается, но качество плана и время выполнения могут ухудшиться. Этот метод используется по умолчанию в Greenplum 13 и ранее.
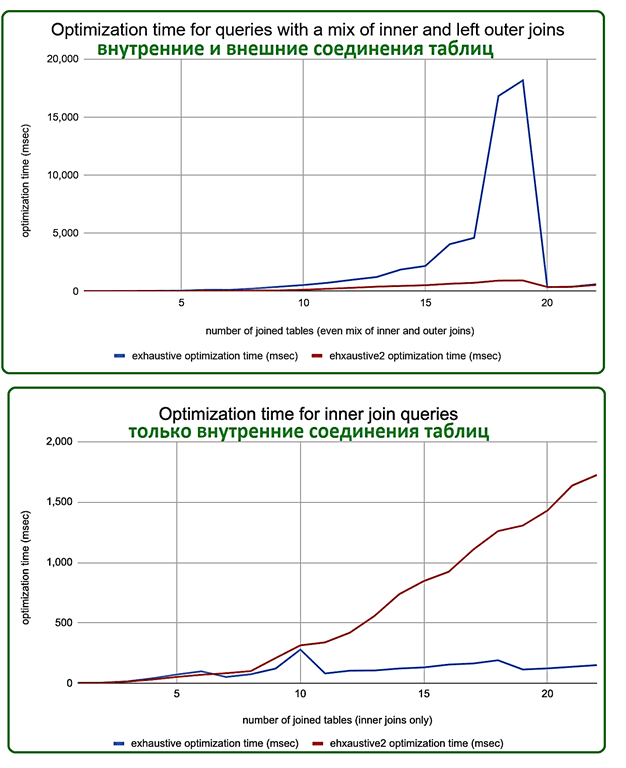
- exhaustive2 – улучшенная версия exhaustive1, с упором на создание порядков соединения, наиболее подходящих для динамического исключения разделов. Этот алгоритм применяет правила преобразования для поиска и оценки n-сторонних внутренних и внешних соединений. При оценке очень больших соединений с большим количеством таблицам, чем задано в optimizer_join_order_threshold, этот алгоритм также постепенно перейдет к жадному методу.
Установка параметра optimizer_join_order в значения query или greedy может привести к созданию неоптимального плана запроса. Однако, если администратор Greenplum уверен, что таким образом можно получить удовлетворительный план выполнения запроса, время его оптимизации можно сократить. При этом GPORCA будет игнорировать параметр optimizer_join_order_threshold [5].
Exhaustive-алгоритмы сочетают методы динамического программирования с жадным поиском. Напомним, главное отличие динамического программирования от жадных алгоритмов – это ориентация на глобальную оптимизацию, т.е. по всей задаче, а не в рамках отдельно взятого этапа. И, хотя динамическое программирование тоже предполагает разбиение исходной задачи на менее сложные подзадачи, в отличие от жадных алгоритмов, здесь используется рекурсия, когда рассматриваемый объект является частью целого. Такое усложнение снижает скорость вычислений по сравнению с жадными алгоритмами, но позволяет решать задачу оптимизации глобально, а не локально.
Применив эти математические основы к оптимизации SQL-запросов в Greenplum, отметим, что время планирования в алгоритме exhaustive2 плавно увеличивается по мере их усложнения, а качество планирования и время выполнения постепенно ухудшаются. Однако, данный метод, сочетающий достоинства жадных алгоритмов с динамическим программированием, отлично подходит для многих запросов. Поэтому именно он используется в Greenplum по умолчанию начиная c версии 6.14, хотя его в экспериментальном режиме можно попробовать и в более ранних релизах – с 6.11.1 в линейке 6.x и с 5.28.2 в линейке 5.х.
В качестве иллюстративного примера рассмотрим SQL-запрос с 7 операторами внутреннего соединения и 7 операторами внешнего соединения, всего 15 таблиц. В GPDB 6.13 8-стороннее внутреннее соединение находится ниже порога в 10 таблиц, поэтому выполняется исчерпывающее перечисление (exhaustive enumeration), а дополнительные 7 таблиц с внешними соединениями потребуют значительного дополнительного времени. Такой запрос будет относительно медленным для оптимизации. В GPDB 6.14 выполняется комбинированные внутренние и внешние соединения (15-сторонний JOIN), без полного перечисления соединяемых таблиц. Здесь оптимизация запроса займет меньше времени, но его качество плана может немного ухудшиться. Однако, в большинстве случаев полученное время планирования даст больший выигрыш по сравнению с увеличением времени выполнения и менее оптимальным планом.
Администрирование Greenplum / Arenadata DB
Код курса
GRAD
Ближайшая дата курса
27 мая, 2025
Продолжительность
32 ак.часов
Стоимость обучения
96 000
В качестве бенчмаркингового сравнения exhaustive-алгоритмов разработчики GPORCA провели серию тестов с примерно одинаковым количеством внутренних и внешних соединений. Предыдущая версия exhaustive1 дает экспоненциальный рост времени оптимизации до 10 внутренних соединений, за которым следует спад при переключении на жадный алгоритм. Обновление exhaustive2 сначала тоже растет экспоненциально, но исследует большее пространство поиска для более крупных соединений. Это увеличивает время оптимизации, но ускоряет само выполнение запроса.
В следующей статье мы подробнее рассмотрим достоинства, недостатки и ограничения SQL-оптимизатора GPORCA в Greenplum. А практически освоить тонкости администрирования и эксплуатации Greenplum с Arenadata DB для эффективного хранения и аналитики больших данных вы сможете на авторских курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве.
Источники
- https://greenplum.org/faster-optimization-of-join-queries-in-orca/
- https://gpdb.docs.pivotal.io/6-17/admin_guide/query/topics/query-piv-opt-overview.html
- https://habr.com/ru/company/rostelecom/blog/442758/
- https://gpdb.docs.pivotal.io/6-17/admin_guide/query/topics/query-piv-opt-notes.html
- https://gpdb.docs.pivotal.io/6-17/ref_guide/config_params/guc-list.html

