
Чтобы сделать наши курсы по Greenplum и аналитике больших данных еще более полезными, сегодня рассмотрим особенности выполнения SQL-запросов в этой MPP-СУБД. Читайте далее, зачем и когда запускать оператор анализа табличной статистики ANALYZE, как он связан с планом выполнения SQL-запроса и какие инструменты помогут дата-инженеру, аналитику или разработчику повысить их производительность....
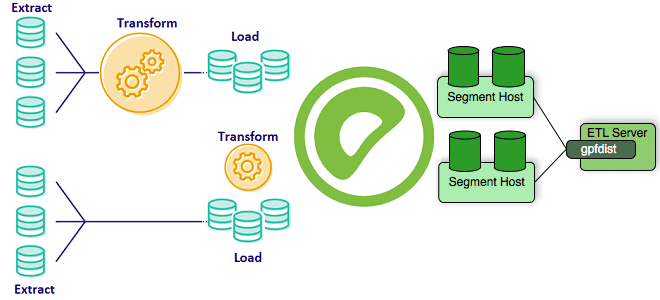
Greenplum часто используется в качестве корпоративного хранилища или аналитического озера данных (Data Lake). Поэтому важно знать особенности реализации ETL-процессов при работе с этой MPP-СУБД, что входит в наш новый курс «Greenplum для инженеров данных». Сегодня рассмотрим способы загрузить большие данные в Greenplum, разберем отличия внешних таблиц от внутренних и отметим,...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...
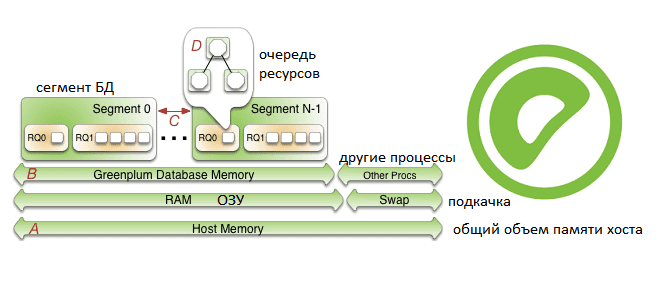
Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня поговорим про особенности конфигурирования памяти в этой MPP-СУБД: разберем, как память хоста распределяется между сегментами и рассмотрим, как администратор кластера может ускорить работу этой базы данных. Также читайте далее о связи RAM с настройками ядра операционной системы и схемами...

Cегодня рассмотрим некоторые инструменты защиты данных в Greenplum. Читайте далее про особенности шифрования в этой MPP-СУБД и лучшие практики обеспечения информационной безопасности и защиты в этой системе хранения и аналитики больших данных. Администраторы и суперпользователи Greenplum Для надежной защиты данных, хранящихся в MPP-СУБД Greenplum, и обеспечения информационной безопасности кластера рекомендуется...

Развивая наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим, почему в этой MPP-СУБД возникают проблемы нехватки памяти, каковы типовые способы их решения и чем очереди ресурсов отличаются от ресурсных групп. Читайте далее про схемы управления ресурсами в Greenplum и особенности параметра конфигурации statement_mem. Очереди vs Группы: 2 схемы управления...

Продолжая рассказывать про наш новый курс «Greenplum для инженеров данных», сегодня рассмотрим некоторые особенности хранения данных в этой MPP-СУБД, а также разберем связанные с ними лучшие практики ее администрирования. Читайте далее про важность RAID-массивов, механизмы дублирования кластеров, утилиты резервного копирования и восстановления данных в Greenplum. RAID-массивы и зеркалирование жестких дисков...

Сегодня разберем еще одну интересную тему из нашего нового курса «Greenplum для инженеров данных» по построению конвейеров приема данных для этой MPP-СУБД в рамках веб-интерфейса платформы автоматизированного управления потоками работ Apache NiFi. Читайте далее, как устроен коннектор VMware Tanzu Greenplum для Apache NiFi и какие возможности он предоставляет дата-инженеру. Что...

Партиционирование таблиц – надежный способ повышения производительности Greenplum, который тесно связан с особенностями распределения данных по сегментам кластера. Читайте далее, чем опасно неравномерное распределение данных и вычислений по узлам, а также как найти дата-инженеру и устранить эти перекосы в MPP-СУБД, чтобы повысить скорость выполнения SQL-запросов и решить проблемы с нехваткой...
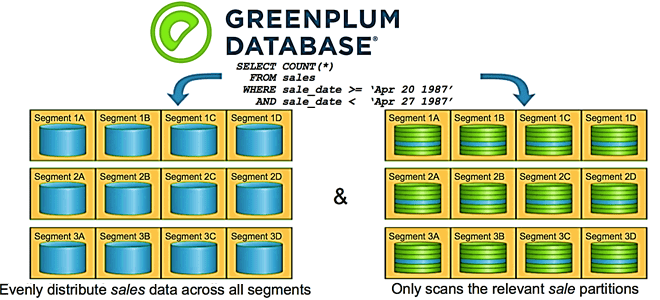
Мы уже рассказывали про основы хранения и аналитики больших данных в Greenplum, а также рассматривали особенности индексации и сжатия данных в этой MPP-СУБД. Продолжая разговор о нашем новом курсе «Greenplum для инженеров данных», сегодня разберем лучшие практики разбиения данных на разделы и пример их распределения по сегментам кластера. Кратко о...