Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и...

Для практического использования Apache Airflow в production дата-инженеру необходимо не только обучение основам работы с этим фреймворком, но и знания о базовой инфраструктуре его развертывания. Поэтому сегодня поговорим о 3-х популярных средах для развертывания и сопровождения этого ETL-фреймворка: Astronomer, Google Cloud Composer и Amazon Managed Workflows, разобрав их основные возможности...
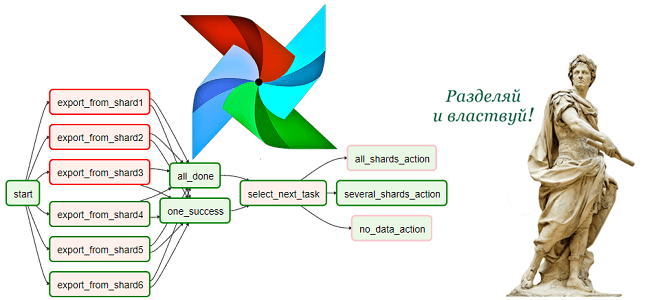
Чтобы сделать обучение дата-инженеров еще более полезным, сегодня мы рассмотрим проблему управления взаимозависимыми цепочками задач в Apache AirFlow. Читайте далее, как бразильская ИТ-компания QuintoAndar разработала промежуточный компонент Mediator на базе одноименного шаблона архитектурного проектирования ПО, чтобы облегчить взаимодействие между разными DAG’ами в конвейерах обработки больших данных. Проблема взаимозависимых DAG’ов в...

Практическое обучение дата-инженеров – это не просто курсы по основам Big Data, а полезные рекомендации с реальными примерами. Поэтому сегодня рассмотрим, как работать с DAG в Apache AirFlow еще эффективнее с помощью параметров конфигурации, плагинов, меток, шаблонов, переменных и еще 10 различных инструментов. 15 лучших практики для DAG в Apache...

Чтобы добавить в наши обновленные авторские курсы для дата-инженеров по Apache AirFlow еще больше интересного, сегодня продолжим разбирать полезные дополнения релиза 2.0 и поговорим, почему разделение фреймворка на пакеты делает его еще удобнее. Также рассмотрим практический пример создания общедоступного провайдера из локального Python-пакета с собственными операторами, хуками и прочими компонентами....
В поддержку наших полностью обновленных авторских курсов для инженеров данных по Apache AirFlow, сегодня рассмотрим новые способы определения DAG, которые были добавлены в релизе 2.0. Читайте далее, что под капотом TaskFlow API, как поместить задачи в TaskGroup, чем dag_policy отличается от task_policy и почему все это упрощает работу инженера Big...

Хорошие курсы дата-инженеров предполагают не только изучение теории и практики, но и проверку полученных знаний. Поэтому сегодня мы предлагаем вам открытый интерактивный тест по Apache AirFlow. Ответьте на 10 простых вопросов и узнайте, насколько хорошо вы знакомы с особенностями администрирования и эксплуатации этого популярного фреймворка для автоматизации batch-заданий обработки и...
Поскольку курсы инженеров Big Data предполагают практическое обучение на реальных кейсах, сегодня поговорим про тестирование конвейеров обработки и аналитики больших данных и разберем несколько прикладных примеров для компонентов экосистемы Apache Hadoop. Читайте далее про проверку работоспособности, а также поиск ошибок в Spark-заданиях и DAG-цепочках Airflow. Конвейер для конвейера: сложности тестирования...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

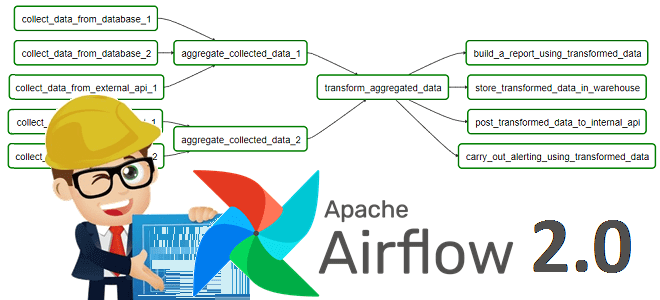
В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...