 1272
1272 
Содержание
Совмещение Airflow с Kubernetes уже становится стандартом де-факто для дата-инженеров. Недавно мы рассказывали про 3 популярные среды развертывания и сопровождения этого ETL-фреймворка в Kubernetes. Продолжая эту тему, сегодня рассмотрим, какие операторы использовать для контейнерного запуска batch-задач, а также поговорим о том, как Docker-образы помогут решить проблему изменения версий Python и автоматизировать управление масштабными Big Data конвейерами.
Еще раз о пользе контейнерного развертывания Airflow
Сегодня Apache Airflow – пожалуй, самый популярный в мире Big Data инструмент для планирования конвейеров обработки данных. В частности, с ним очень удобно запускать задания Spark в кластере по расписанию с помощью оператора SparkSubmitOperator или применять BashOperator для пакетов и программ на локальной машине. Также AirFlow подходит для многих Data Science сценариев, позволяя запускать Python-код в рамках оператора PythonOperator. Однако, для этого пользовательский код должен быть совместим с Python-версией Airflow, а используемые библиотеки должны быть установлены в системе. На практике обеспечить это становится труднее по мере усложнения data pipeline’ов и роста команды. К примеру, кому-то потребовалась новая версия Python или библиотека, а в production уже работает много задач, выполняемых со старой и несовместимой версией библиотеки. В такой ситуации есть два решения:
- обновить библиотеку и все проблемные задачи, что долго и трудоемко при их большом количестве;
- продолжить работу с устаревшей версией, что в итоге все равно потребует обновления, занимая все больше времени и усилий.
Оба этих варианта являются неидеальными и приводят к лишним затратам, не приносящим фактической ценности конечному продукту. Избежать этого можно с помощью контейнеризации, упаковав в Docker-контейнеры нужные библиотеки, задачи и прочие компоненты. В частности, можно создать цепочку задач (DAG, Directed Acyclic Graph), где каждая задача выполняется в отдельном контейнере, что обеспечит нужный уровень безопасности за счет изоляции, позволяя установить любую версию библиотеки или языка. Также это позволит автономно создавать задачи с использованием новых технологий, не трогая уже запущенные DAG’и [1]. Реализовать контейнерное управление конвейерами данных в AirFlow можно в рамках решений, о которых мы поговорим далее.
3 варианта запуска DAG’ов в Docker-контейнерах
В зависимости от среды запуска Apache AirFlow в Docker-контейнерах на Kubernetes, можно использовать следующие операторы [1]:
- непосредственный запуск Docker-контейнеров в подах Kubernetes, которые уничтожаются после того, как задача выполнится. Этот вариант недолговечен и не использует возможности системы полностью. Каждая задача является контейнером Docker, который запускается в Kubernetes как под. Airflow переносит логи из Kubernetes в пользовательский интерфейс задачи, обеспечивая прозрачность выполнения с помощью KubernetesPodOperator. KubernetesPodOperator использует Kubernetes API для запуска модуля в кластере Kubernetes. Предоставляя URL-адрес Docker-образа и команду с необязательными аргументами, оператор использует клиент Kube Python для создания запроса API Kubernetes, который динамически запускает отдельные поды.
- планирование запуска заданий в Google Kubernetes Engine (GKE) в рамках Google Cloud с помощью оператора GKEStartPodOperator. Можно использовать также и KubernetesPodOperator, но это потребует дополнительной настройки [2].
- планирование заданий в Elastic Container Service (ECS) в рамках Amazon Web Services (AWS) с помощью KubernetesPodOperator или собственного оператора запуска контейнерных задач ECSOperator в сервисе оркестровки контейнеров. В ECS нет подов, но концепция похожа на обычный запуск AirFlow-задач в классическом Kubernetes: как только задача AirFlow завершена, она не потребляет ресурсы [3].
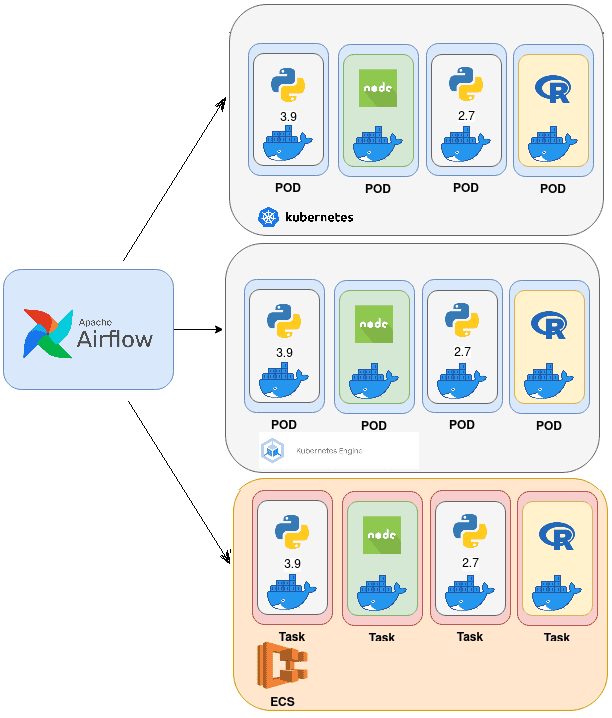
Независимо от выбранного варианта запуска AirFlow-задач, кластер должен иметь есть все необходимые разрешения и учетные данные для доступа к планированию и исполнению DAG’ов. Подчеркнем, что KubernetesPodOperator нужен для запуска задач в Kubernetes, а Kubernetes Executor – для запуска самого Airflow на Kubernetes. Подробнее об этом мы рассказывали здесь и здесь. Кроме того, совсем не обязательно запускать сам фреймворк на Kubernetes или ECS, можно планировать задачи во внешних кластерах. Таким образом, контейнеры обеспечивают лучшую изоляцию и другие DevOps-преимущества конвейера CI/CD, но требуют дополнительных компетенций дата-инженера.
Получить эти знания и другие практические навыки применения Apache AirFlow для разработки сложных конвейеров аналитики больших данных с Hadoop и Spark вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://towardsdatascience.com/apache-airflow-for-containerized-data-pipelines-4d7a3c385bd
- https://airflow.apache.org/docs/apache-airflow-providers-google/stable/operators/cloud/kubernetes_engine/#run-a-pod-on-a-gke-cluster
- https://airflow.apache.org/docs/apache-airflow-providers-amazon/stable/operators/ecs/

