Сегодня разберем, что такое глубокое обучение и почему MLOps очень важен для этих методов Machine Learning. В чем особенности обучающих данных для моделей Deep Learning и зачем дополнять типовые MLOps-инструменты собственными разработками, избегая вредных антипаттернов.
Машинное обучение vs Deep Learning: разница для MLOps
Создание ML-систем сводится не только к разработке точных алгоритмов, а также их упаковке в эффективный код. Также важны методы управления данными машинного обучения, включая внедрение новых шаблонов проектирования архитектуры и инструментальных средств их реализации, таких как хранилища фичей, фреймворки мониторинга входных и выходных данных. За это отвечает концепция MLOps, согласно которой идеи DevOps применяются для автоматизации разработки, развертывания и мониторинга конвейеров машинного обучения в производственной среде. По мере развития интереса к MLOps растет число инструментов с открытым исходным кодом, а также увеличивается количество проприетарных платформ, о чем мы писали здесь.
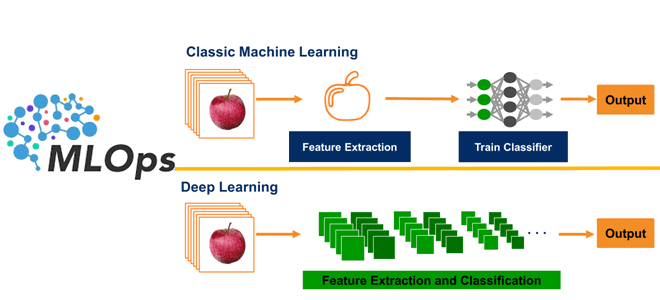
Однако, большинство этих фреймворков в области управления данными для машинного обучения сосредоточены на классических данных (на основе признаков) и не могут быть применены к неструктурированным данным, которые используются в глубоком обучении (Deep Learning, DL). Глубокое обучение – это метод машинного обучения, который предполагает самостоятельное выстраивание правил моделью в виде нейросети на основании изучения входных данных, которых очень много. Вообще огромные масштабы самой нейромодели и обучающих датасетов и являются главным отличием Deep Learning от классического ML. В глубоком обучении входные данные могут иметь различные структуры: изображения, видео, аудио или другие сигналы в виде больших двоичных объектов. В классическом ML входные данные обычно имеют табличную структуру.
Кроме того, в глубоком обучении входные данные разных форматов поступают из разных источников и с различной частотой. Иногда данные также генерируются синтетическим путем с использованием симуляций, генеративных алгоритмов, путем «упреждающих» действий, например, постановка и захват изображений с потенциально опасными ситуациями, или поиска данных с видеосъемок улиц через лидары беспилотных автомобилей. Каждый раз производственные данные используются для создания эффективного цикла улучшений модели, который может быть создан только после выпуска исходной модели. Но, прежде чем использовать эти данные, их следует преобразовать, очистить и обогатить. Этот процесс требует обработки больших двоичных объектов, что достаточно сложно на практике.
Преобразование неструктурированных данных может быть простым (масштабирование, обрезка, выборка, кодирование) или более сложным типа встраивания данных в векторное пространство с использованием предварительно обученной модели. Очистка обычно означает разметку поврежденных данных, таких как пустые файлы или необоснованные аннотации. Обогащение часто сводится к автоматизированному извлечению интересных данных из необработанных байтов, например, условия освещения для изображения. Также люди могут создавать аннотации (метки) вручную. Задачи аннотирования могут быть простыми типа ручной классификации объектов на фото или требовать строгой, регулируемой, многопрофильной экспертной разметки с принудительным протоколом для разрешения спорных случаев. Наконец, обогащение может включать в себя дополнение данных информацией из других источников.
Сложность в том, что ML-команды обычно имеют доступ к пулам данных, которые не могут быть полностью использованы при моделировании, особенно если они требуют разметки. Случайной выборки данных бывает недостаточно, поскольку нужно обеспечить широкое распределение обучающего диапазона, например, охватить все возможные условия освещения, включая изменения фона. Наборы обучающих данных для Deep Learning также включать редкие пограничные случаи, особенно для критически важных приложений.
Иногда создание обучающего набора данных представляет собой итеративный цикл, например, когда некоторые метки нужны для начального или конечного этапа обучения. Наконец, при обучении и оценке часто используется несколько наборов данных для проверки поведения модели с разных сторон.
MLOps в классическом машинном обучении предлагает инструменты мониторинга экспериментов над моделями, а также отслеживания состояния данных, на этапах тренировки, валидации и тестирования алгоритмов. Хотя в целом жизненный цикл DL-модели не слишком отличается от классического ML, есть несколько уникальных проблем управления данными. В классическом ML полезная нагрузка состоит из фичей и чаще всего представляется менее чем в 1 КБ данных для одного примера модели. Это позволяет относительно множество механизмов хранения, запросов и визуализации, созданных специально для структурированных данных. А неструктурированные данные могут не храниться в СУБД из-за большого размера и не подлежать обработке средствами SQL-запросов. Это требует разработки специализированных решений для хранения, запросов и визуализации неструктурированных данных.
Кроме того, в классическом ML можно полагаться исключительно на данные, созданные самой системой, например, пользовательские клики, покупки, транзакции и пр., и хранить их практически неограниченное время. В DL сбор и хранение производственных данных в полном объеме обходится очень дорого. Более того, через некоторое время 99,9% данных из производственной системы не имеют большого значения для улучшения модели, а оставшиеся 0,1% становятся критически важными, но труднодоступными, к примеру, редкие крайние случаи, связанные с безопасностью.
В некоторых системах глубокого обучения конвейеры сбора и обработки данных должны иметь возможность идентифицировать и фильтровать только интересные данные для долгосрочного хранения. Еще одна проблема с объемами данных заключается в том, что для обучения моделей Deep Learning нужно высококачественное и быстрое хранилище, способное работать с уникальными форматами данных, чтобы оптимизировать путь загрузки данных с диска в память графического процессора. Поскольку это довольно дорого, а объем данных большой, приходится управлять «холодными» данными в более дешевом долгосрочном хранилище, которое оптимизировано по пропускной способности, стоимости и поддерживает произвольный доступ к отдельным примерам, позволяя маркировать данные. Для данных глубокого обучения часто нужно несколько уровней хранения с разными профилями стоимости и производительности, которые должны храниться в разных форматах хранения для разных потребителей. Поэтому типовые MLOps-решения требуют дополнительных инструментов при их внедрении в системы Deep Learning. Кроме того, есть определенные антипаттерны в управлении данными глубокого обучения, что мы рассмотрим далее.
Антишаблоны в управлении данными глубокого обучения
Управление большим и постоянно растущим массивом данных для глубокого обучения может оказаться непростой задачей. При этом рекомендуется избегать следующих антишаблонов:
- Слишком тщательная подготовка данных и формирование обучающих примеров для графического процессора. Это целесообразно для классического ML, а глубокое обучение предполагает разнообразные обучающие данные, включая множество крайних случаев.
- наборы данных, прогнозы меток и метрики из цикла усовершенствований модели теряются либо сохраняются как артефакты конкретных экспериментов, что усложняет обмен данными между проектами и командами.
- несовпадение форматов — даже если данные доступны в централизованном хранилище, наборы данных хранятся в различных форматах, что затрудняет обогащение данных и их объединение из нескольких источников.
- непонимание природы данных, включая особенности доменной области. Например, собирать изображения с дневными и с ночными сценами. Но на практике узнать, какое изображение содержит дневную или ночную сцену, для нескольких терабайт изображений, довольно трудно. Можно отобрать достаточное количество примеров в произвольном порядке. Но это отнимает много времени и не работает для необычных случаев, например, ночной град. Стоимость этой ручной работы слишком высока, и поэтому наборы обучающих данных для глубокого обучения лишаются так называемых крайних случаев, которые чрезвычайно важны для Deep Learning.
Читайте в нашей новой статье, как масштабировать модели глубокого обучения для нескольких графических процессоров или распределенных вычислений с помощью платформы Horovod.
Как выбрать и внедрить современные инструменты MLOps в реальные проекты аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники