638
638 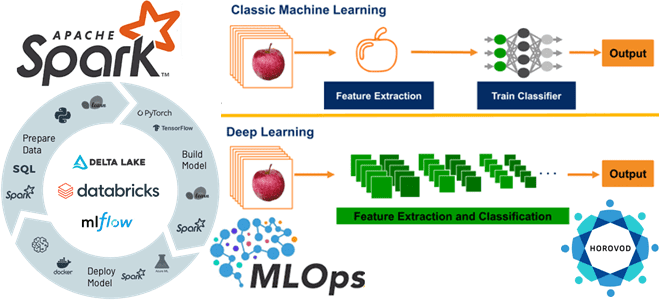
Из чего состоит инфраструктура глубокого обучения Databricks и как масштабировать Deep Learning для нескольких графических процессоров или распределенных вычислений. Знакомимся с очередным MLOps-инструментом под названием Horovod.
Что Horovod и как его использовать в Databricks
Мы уже писали, почему глубокому обучению не обойтись без MLOps-инструментов, реализующих идеи DevOps для автоматизации разработки, развертывания и мониторинга конвейеров машинного обучения в производственной среде. Поэтому популярная облачная платформа Databricks Machine Learning предоставляет предварительно созданную инфраструктуру глубокого обучения со средой исполнения, которая включает популярные библиотеки Deep Learning, такие как TensorFlow, PyTorch и Keras. Также эта платформа имеет встроенную предварительно настроенную поддержку графического процессора, включая драйверы и вспомогательные библиотеки. Кроме того, Databricks Runtime ML включает все возможности рабочей области Databricks, такие как создание кластера и управление им, управление библиотеками, средой и кодом с помощью репозиториев. Еще платформа поддерживает автоматизацию процессов создания и развертывания моделей машинного обучения согласно концепции MLOps, в т.ч. задания и API-интерфейсы Databricks, интегрированный MLflow для отслеживания разработки моделей, их интеграции и обслуживания моделей.
Поскольку глубокое обучение потребляет много вычислительных ресурсов, оно обычно реализуется не на одном узле, а в кластере. Хотя по возможности Databricks рекомендует обучать нейросети на одном компьютере, т.к. распределенный код для обучения и логического вывода сложнее и медленнее локального из-за накладных расходов на связь, когда ML-модель или данные становятся слишком велики, чтобы поместиться в памяти на одном компьютере, следует задуматься о распределенном обучении. Для перехода от одноузлового к распределенному обучению Databricks Runtime ML включает HorovodRunner, spark-tensorflow-distributorTorchDistributor и Hyperopt.
Horovod — это проект с открытым исходным кодом, который масштабирует модели глубокого обучения для нескольких графических процессоров или распределенных вычислений. Это распределенная обучающая среда глубокого обучения для TensorFlow, Keras, PyTorch и Apache MXNet, цель которой сделать распределенное глубокое обучение быстрым и простым в использовании. Одной из уникальных особенностей Horovod является его способность чередовать обмен данными и вычисления вместе с возможностью пакетного выполнения небольших операций allreduce , что приводит к повышению производительности. Также платформа позволяет одновременно запускать отдельные коллективные операции в разных группах процессов, участвующих в одном распределенном обучении. При использовании кластера с GPU-ускорением, следует установить библиотеки разработки CUDA, необходимые для компиляции Horovod.
HorovodRunner — это общий API для запуска распределенных рабочих нагрузок глубокого обучения на Databricks с использованием платформы Horovod . HorovodRunner представляет собой оболочку Horovod, обеспечивающую совместимость с Apache Spark. API позволяет масштабировать одноузловой код с минимальными изменениями. HorovodRunner работает с TensorFlow, Keras и PyTorch. Интегрируя Horovod с барьерным режимом Spark, Databricks может обеспечить более высокую стабильность для длительных заданий обучения глубокому обучению в Spark. Подробнее о том, какие внутренние механизмы Spark при этом используются, читайте в нашей новой статье.
Барьерный режим Apache Spark означает такую модель планирования, которая позволяет пользователям правильно встраивать распределенное глубокое обучение в качестве этапа Spark, чтобы упростить рабочий процесс. Ранее Horovod использовал MPI для реализации all-reduce для ускорения распределенного обучения TensorFlow, и модель вычислений значительно отличалась отличается от MapReduce, используемой Spark. В Spark задача на этапе не зависит ни от каких других задач на том же этапе, поэтому ее можно планировать независимо. В MPI все рабочие процессы запускаются одновременно и передают сообщения. Поэтому начиная с Apache Spark 2.4 была внедрена барьерная модель планирования, которая запускает задачи одновременно и предоставляет пользователям достаточно информации и инструментов для внедрения распределенного глубокого обучения.
HorovodRunner использует метод Python, который содержит обучающий код для глубокого обучения с асинхронными перехватчиками (хуками) Horovod. HorovodRunner выбирает метод для драйвера и распространяет его среди воркеров Spark. Задание Horovod MPI внедряется как задание Spark с использованием барьерного режима выполнения. Первый исполнитель собирает IP-адреса всех исполнителей задач с помощью BarrierTaskContextи запускает задание Horovod с помощью mpirun. Каждый процесс Python MPI загружает подготовленную пользовательскую программу, десериализует ее и запускает.
В общем случае подход к разработке распределенной программы глубокого обучения с помощью HorovodRunner выглядит так:
- Необходимо создать экземпляр HorovodRunner, инициализированный количеством узлов;
- Далее следует определить метод обучения Horovod, добавив в него любые операторы импорта;
- Наконец, можно передать метод обучения экземпляру HorovodRunner.
Пример Python-кода, реализующего эту последовательность действий, выглядит так:
hr = HorovodRunner(np=2) def train(): import tensorflow as tf hvd.init() hr.run(train)
Поскольку MLOps распространяется на полный жизненный цикл ML-модели, включая управление экспериментами, как настоящий MLOps-инструмент Horovod позволяет записывать хронологию обучения с помощью временной линейки Horovod Timeline . Однако, Horovod Timeline сильно влияет на производительность платформы, снижая ее пропускную способность. Поэтому, чтобы ускорить задания HorovodRunner, рекомендуется отключить временную линейку Horovod и не просматривать ее во время обучения. Если же необходимо записать временную линейку Horovod, надо задать для переменной среды HOROVOD_TIMELINE место, куда будет сохраняться файл. Databricks рекомендует хранить этот файл в общем хранилище, чтобы быстро получить доступ к нему.
В заключение отметим, что при изменении версии TensorFlow, Keras или PyTorch необходимо переустановить Horovod, чтобы он был скомпилирован для вновь установленной библиотеки. Например, для обновления TensorFlow рекомендуется использовать сценарий инициализации из инструкций по установке TensorFlow и добавить в конец следующий код установки Horovod для TensorFlow:
add-apt-repository -y ppa:ubuntu-toolchain-r/test apt update # Using the same compiler that TensorFlow was built to compile Horovod apt install g++-7 -y update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7 HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Узнайте больше про использование MLOps-инструментов в системах аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники