 975
975 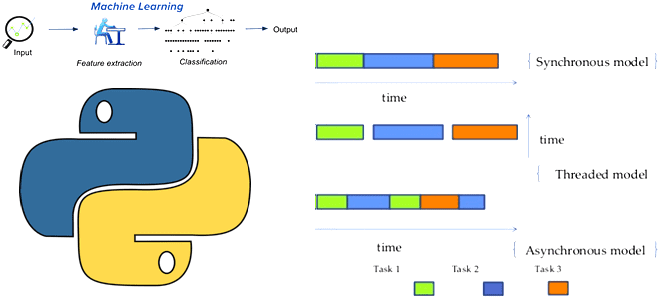
Содержание
Поскольку концепция MLOps стремится устранить разрывы между разработкой ML-модели и ее имплементацией в эффективный программный код, сегодня поговорим про важную идею программирования, связанную с синхронностью и асинхронностью вызовов. Что такое асинхронное программирования, зачем это нужно в Machine Learning и какие Python-библиотеки поддерживают это.
Проблемы синхронных вызовов в ML-системах
В реальных проектах Machine Learning специалисты по Data Science должны не только создать наиболее точную модель, но и сделать возможным ее практическое использование в различных приложениях. Чтобы поделиться своей обученной моделью, ее нужно развернуть в публичном пространстве, например, в облаке, куда разные приложения и пользователи смогут отправлять запросы и получать прогнозы. При этом важно обеспечить соблюдение функциональных и нефункциональных требований к ML-системе, часть из которых может быть реализована за счет специфических приемов разработки ПО, например, асинхронное программирование.
Традиционно в разработке ПО используется синхронное программирование, когда инструкции пользовательского кода выполняются последовательно с синхронными системными вызовами, которые полностью блокируют поток выполнения, пока не завершится системная операция, например, чтение данных с диска. В асинхронном программировании процессы выполняются в неблокирующем режиме системного вызова, что позволяет потоку программы продолжить обработку, не ожидая ранее ответа на сделанный вызов.
Рассмотрим случай, когда нужно было загрузить множество изображений, аудиофайлов и текста для обучения модели или необходимо извлекать несколько файлов из баз данных или хранилища фичей и объединять их для ML-модели. Чтобы ускорить весь цикл обучения и получения результатов, эти предварительные действия можно выполнять одновременно, т.е. параллельно. Поэтому возникает вопрос распараллеливания этих задач. Это можно реализовать следующими способами:
- последовательный ввод – это самый наивный подход, когда файлы загружаются по одному, что занимает много времени, а потому не применимо на практике;
- многопроцессорность, когда ЦП обрабатывает несколько разных процессов, которые могут выполнять вычисления отдельно и параллельно. Эти процессы имеют свою собственную выделенную оперативную память и не зависят друг от друга, а родительский процесс управляет ими для сопоставления и сбора выходных данных по мере необходимости. Этот подход намного быстрее предыдущего, однако, важно найти баланс между количеством процессов и производительностью. Много процессов не всегда означает более высокую производительность из-за накладных расходов на создание и внутреннюю организацию этих процессов. На практике многопроцессорная обработка подходит для задач, которые сильно зависят от вычислений, например, выполнение ML-модели или запуск пользовательского скрипта для разработки фичей. В рассматриваемом случае с загрузкой множества обучающих данных ЦП по сути бездействует, ожидая завершения загрузок, т.е. задач ввода-вывода данных.
- многопоточность, когда вместо процессов используются потоки. Каждый поток не обязательно имеет отдельную память, они часто делят ресурсы между собой. Это усложняет реализацию многопоточных программ на Python и может привести к запутанным результатам. Примечательно, что многопроцессорность и многопоточность, в отличие от последовательного выполнения, не обязательно гарантируют корректный порядок вывода, что может быть критично в некоторых кейсах, связанных с точной хронологией событий. Кроме того, многопоточные программы обычно более сложны и подвержены ошибкам, а также проблемам, связанным с состоянием гонки (race condition), взаимная и активная блокировки (deadlock, livelock) и исчерпание ресурсов (resource starvation).
- асинхронное программирование, что сводится к потоковой обработке кода, где приложение, а не процессор, управляет потоками и переключением контекста, переключая его только в заданных точках, а не с периодичностью, определенной ЦП. Именно этот вариант является более эффективным, а потому его и рассмотрим далее.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
30 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Плюсы и минусы асинхронного программирования на примере Python-библиотеки Asyncio
Есть несколько Python-библиотек асинхронного программирования, например, Tornado, Gevent и Asyncio. Библиотека Asyncio встроена в ядро Python 3.5 и решает проблемы многопоточного программирования, обеспечивая следующие преимущества:
- программное переключение контекста на основе цикла событий;
- отсутствие состояния гонки, поскольку Asyncio запускает только одну сопрограмму и переключается только в заранее определенных разработчиком точках;
- отсутствие блокировок, т.е. нет гонки потоков;
- достаточность ресурсов, поскольку сопрограммы запускаются в одном потоке и не требуют дополнительной памяти. Впрочем, в Asyncio есть пул исполнителей (executors), что равнозначно пулу потоков и, если запускать слишком много процессов в пуле исполнителей, можно столкнуться с нехваткой ресурсов.
Главной идей асинхронного программирования является цикл событий — планировщик, отвечающий за выполнение всех сопрограмм (асинхронных функций) в течение жизненного цикла программы. Эта модель параллелизма, по сути, представляет собой единый цикл while, который берет сопрограммы и умело их запускает. После выполнения сопрограммы ключевое слово await (yield) возвращает управление циклу событий для запуска других сопрограмм. Пока цикл событий ожидает ответа ввода-вывода, будущего завершения или просто асинхронного «засыпания», он может запускать другие сопрограммы. Цикл событий отслеживает, что должно быть возвращено каждой сопрограмме, и будет возвращать это соответствующей сопрограмме в будущих итерациях цикла. Это достоинство асинхронного программирования является и его недостатком.
При запуске задачи, связанной с ЦП, в цикле событий, она будет до своего завершения, как любой последовательный и простой цикл while. А всем остальным задачам придется ждать, пока ресурсоемкая задача не будет выполнена. Блокировка цикла событий считается плохой практикой, т.к. это фактически отменяет ценность асинхронного программирования.
Для применения асинхронного программирования в ML рекомендуются следующие советы:
- не вызывать обычные функции из сопрограммы (асинхронное определение), так как они могут заблокировать цикл обработки событий;
- использовать исполнитель ThreadPool для неасинхронного ввода-вывода (неасинхронные библиотеки баз данных) или легких вычислений с привязкой к процессору;
- использовать исполнитель ProcesPool для ресурсоемких задач с интенсивным использованием процессора, т.е. создание процессов и перемещение данных обходятся довольно дорого.
Все эти идеи реализованы в Python-библиотеке Asyncio для написания параллельного кода с использованием синтаксиса async/await. Она применяется в качестве основы для асинхронных Python-фреймворков, которые обеспечивают высокопроизводительные сетевые и веб-серверы, библиотеки подключения к базам данных, распределенные очереди задач и пр. Asyncio отлично подходит для кода, связанного с вводом-выводом, и предоставляет набор высокоуровневых API. Методы этих API позволяют запускать Python-сопрограммы одновременно и полностью контролировать их выполнение, выполнять сетевой ввод-вывод и IPC, управлять подпроцессами и распределять задачи по очередям, а также синхронизировать параллельный код.
Также в Asyncio есть низкоуровневые API для разработчиков библиотек и фреймворков, позволяющие:
- создавать и управлять циклами событий;
- реализовать эффективные протоколы с использованием транспорта;
- объединять библиотеки на основе обратных вызовов и код с синтаксисом async/await.
Однако, Asyncio не работает на платформах WebAssembly wasm32-emscripten и wasm32-wasi.
Возвращаясь к применимости асинхронного программирования в создании ML-систем, отметим, что эта Python-библиотека обеспечивает самый дешевый способ переключения задач, т.к. вызов чистой функции Python имеет больше накладных расходов, чем перезапуск генератора или ожидания. Python-функция создает стек каждый раз, когда она вызывается, тогда как асинхронная использует генераторы внизу, у которых уже есть созданный стек. Скорость работы асинхронных серверов намного быстрее многопоточных и дешевле с точки зрения ресурсов. Однако, чтобы вызвать переключение задачи, нужно явно добавить в программный код вызов методов yield() или await().
Как выбрать и внедрить современные инструменты MLOps в реальные проекты аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

