 1159
1159 
Содержание
В этой статье поговорим про интеграцию информационных систем: обсудим SOA и ESB-подходы, рассмотрим стриминговую архитектуру и возможности Apache Kafka для организации быстрого и эффективного обмена данными между различными бизнес-приложениями. Также обсудим, что влияет на архитектуру интеграции корпоративных систем и распределенных Big Data приложений, что такое спагетти-структура и почему много сервисов – это та же паста, только в профиль.
Как рождаются спагетти или от чего зависит архитектура интеграции
Чтобы пояснить, насколько сложны вопросы корпоративной ИТ-архитектуры, перечислим основные факторы, от которых зависит интеграция информационных систем [1]:
- Технологии (SOAP, REST, JMS, MQTT), форматы данных (JSON, XML, Apache Avro или Protocol Buffer), фреймворки и экосистемы (Nginx, Kubernetes, Apache Hadoop), собственные интерфейсы (EDIFACT, SAP BAPI и пр.);
- языки программирования и платформы, например, Java, .NET, Go или Python;
- архитектуры приложений, такие как монолит, клиент-сервер, сервис-ориентированная архитектура (Service Oriented Architecture, SOA), микросервисы или бессерверный подход (serverless);
- режим передачи и обработки данных, например, пакеты (batch), реальное время (real time), запрос-ответ (request-response), издатель-подписчик, непрерывные запросы и пр.
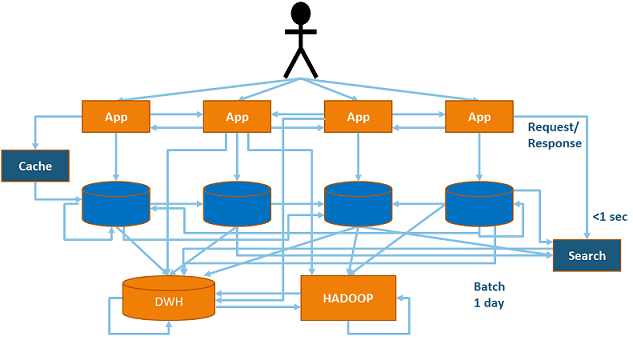
Из-за этого реальные взаимосвязи между различными компонентами корпоративной ИТ-архитектуры (DWH, Data Lake, бизнес-приложения, различные СУБД и пр.) весьма запутанны и напоминают «спагетти». По аналогии с программированием, это является синонимом плохо спроектированной системы и считается антипаттерном [2].
От спагетти к равиоли: антипаттерны корпоративной ИТ-архитектуры
Для решения проблемы спагетти-архитектуры в области Big Data можно использовать следующие средства [1]:
- ETL-инструментов для создания пакетных конвейеров, например, Apache AirFlow;
- корпоративная сервисная шина (Enterprise Service Bus, ESB) для реализации SOA;
- обмен сообщениями через промежуточного брокера, такого как Rabbit MQ или Apache Kafka;
- интеграционные платформы;
- микросервисные шлюзы;
- управление API.
Стоит пояснить, что под термином SOA скрывается целый ряд технологий [3]:
- общая архитектура брокера объектных запросов (CORBA);
- веб-сервисы;
- очередь сообщений;
- сервисная шина предприятия (ESB);
- микросервисы.
Каждой из этих технологий свойственны свои достоинства и недостатки. В частности, современная популярность Agile-принципов и DevOps-подходов привела к востребованности микросервисной архитектуры. Однако, в попытках перейти от «спагетти-архитектуры» не стоит превращать интеграцию информационных систем в «равиоли» — набор мелких микросервисов, которых слишком много и при том они не отражают доменные концепции. Эта архитектура считается антипаттерном микросервисного подхода [3].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Apache Kafka как стриминговая платформа для интеграции корпоративных систем
При том, что история SOA насчитывает уже более 30-лет, сегодня эта концепция считается устаревшей и не слишком эффективной из-за слабой взаимозависимости и высокой связности компонентов [3]. Она по-прежнему не решает проблемы спагетти-архитектуры, к тому же за последние 2 десятилетия большинство SOA-проектов провалились. Поэтому набирает популярность понятие «стриминговая платформа», которая обеспечивает потоковую (streaming) обработку событий (events) в реальном времени. В мире Big Data такой платформой является Apache Kafka. Перечислим ключевые свойства event streaming архитектуры [1]:
- потоки данных на базе событий выступают основой для обработки в реальном времени и пакетном режиме. В отличие от статических хранилищ данных, это позволяет создавать гибкие сервисы для работы с актуальными данными.
- масштабируемая центральная распределенная система для событий между любым количеством источников и приемников. При этом обеспечивается непрерывное обновление, минимальное время простоя, обработки сбоя узлов и сетей. Разные версии инфраструктуры, например, Apache Kafka и бизнес-приложений могут быть развернуты и управляемы динамически.
- интегрируемость любых приложений и систем, независимо от технологии, языков программирования, наличия API-интерфейсов и открытых стандартов, проприетарных средств и устаревших приложений.
- распределенное хранилище для развязки приложений с сохранением состояния микросервисов (stateful) без использования отдельной базы данных. Обычно это нужно для работы с бизнес-процессами, которые следует реализовать с событиями и изменениями состояния, а не с удаленными вызовами процедур и стилем запрос-ответ.
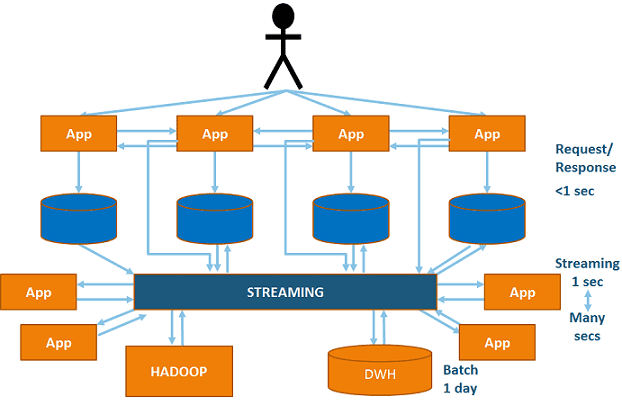
Примечательно, что Apache Kafka предоставляет не только инструментарий для интеграции данных, путем их сбора и агрегации из различных источников в режиме реального времени. Эта распределенная стриминговая Big Data платформа, которую часто используют в качестве брокера сообщений, также позволяет интегрировать приложения между собой с помощью специальных коннекторов в рамках Kafka Connect. Подробнее о других базовых компонентах Apache Kafka мы рассказывали здесь. В следующей статье мы продолжим разговор про архитектуру и интеграцию Big Data систем на примере главных достоинств потоковой обработки событий с помощью Кафка.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
А как использовать Apache Kafka в реальных проектах потоковой обработки больших данных, вы узнаете на практических курсах по Кафка в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков Big Data) в Москве:
Источники
- https://www.confluent.io/blog/apache-kafka-vs-enterprise-service-bus-esb-friends-enemies-or-frenemies/
- https://ru.wikipedia.org/wiki/Спагетти-код
- https://habr.com/ru/company/mailru/blog/342526/

