
Сегодня мы разберем доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [1]. Читайте в нашей статье, как одна из ведущих travel-компаний использует Apache Kafka, с какими проблемами столкнулись администраторы ее Big Data инфраструктуры и DevOps-инженеры, а также почему были выбраны именно такие варианты решения.
Как все начиналось и к чему пришли: предыстория Kafka-challenge’а и постановка задач
Если сгруппировать все виды применения Apache Kafka в цифровых решениях Booking.com по локальным бизнес-направлениям, получатся следующие категории [2]:
- персонализация маркетинговых предложений;
- уведомления о пользовательских и системных событиях;
- отслеживание экспериментов;
- проведение оплаты;
- логгирование;
- обеспечение информационной безопасности.
Таким образом, Apache Kafka задействована как в критичных бизнес-задачах, так и в поддерживающих процессах бэк-офиса. Сегодня вокруг Kafka выстроена целая Big Data экосистема из Apache Hadoop, Hive, Elasticsearch, MySQL и множества других технологий для обработки данных и обмена ими в режиме реального времени. На январь 2020 года в Booking.com эта стриминговая платформа сбора и агрегации потоковых данных развернута на более чем 45 кластерах, чтобы обеспечивать следующие показатели:
- более 450 брокеров;
- свыше 3000 топиков с 60 тысячами разделов (партиций);
- от 4 миллионов сообщений в секунду;
- входной поток данных более 20 ГБ/сек;
- выходной поток данных более 40 ГБ/сек;
- хранение 400 ТБ данных.
Такие крупные числа были достигнуты не сразу – история развития Apache Kafka в Booking.com началась примерно с 2015 года, когда в компании существовал лишь 1 Кафка-кластер, развернутый для нужд администраторов баз данных. С декабря 2017 года количество вариантов использования Kafka стало стремительно расти, что обусловлено, в т.ч. популяризацией стримингового подхода к обработке Big Data и микросервисной архитектуры. Уже через год, в декабре 2018, количество корпоративных клиентов (пользователи и приложения) Kafka выросло почти в 2 раза, а в декабре 2019 года – в 4 относительно начального уровня.
Такой тотальный переход на стриминговую концепцию обработки больших данных поставил перед администраторами Big Data и DevOps-инженерами компании следующие вызовы:
- огромное количество запросов на предоставление и конфигурирование топиков (более 20 задач в неделю);
- отсутствие четких механизмов контроля за клиентами из-за недостатка централизованного управления и настроенных security-механизмов;
- высокий порог входа в технологию и недостаток документации.
Для решения этих проблем в соответствии с DevOps-подходом были поставлены следующие задачи:
- улучшение пользовательского опыта – предоставление разработчикам (Developers) инструментария с нужным уровнем абстракции и возможностями самообслуживания (self-service), включая создание, настройку и конфигурирование требуемых Kafka-топиков;
- оптимизация администрирования за счет гибких опций аутентификации и авторизации, единой панели управления и механизма квот.
Далее мы рассмотрим, как это было реализовано на практике.
Чем полезно пространство имен или немного о Кафка namespace
Чтобы решить проблему с использованием Kafka-топиков, включая идентификацию их принадлежности отдельным клиентам, применялся механизм пространства имен (namespace). Напомним, namespace позволяет группировать топики по определенному бизнес-кейсу, чтобы предоставлять пользователям возможность их самостоятельного создания, имезнения и конфигурирования [3]. Так Booking.com пришел к следующему виду задания Kafka-namespace’ов:
federation/project/service/topic, где
- federation – логическая группа кластеров для определенного департамента или бизнес-направления, выделенная из всего набора Кафка-кластеров. Все кластеры в рамках одной федерации имеют одинаковый набор топиков, списки управления доступом (ACL, Access Control List), квоты и прочие конфигурационные настройки.
- project – конкретный бизнес-проект в федерации, например, платформа для оплаты и пр.;
- service – сервис в бизнес-проекте, например, API или приложение, созданное пользователем (разработчиком);
- topic – конечный Kafka-топик, куда записываются и откуда считываются сообщения.
Пример пространства имен по данному шаблону будет выглядеть так: payments/billing/api/notification. Примечательно, что такой шаблон задания namespace’ов отражает интеграцию разработчиков и администраторов согласно DevOps-подходу: federation относится к области ответственности администраторов Big Data, тогда как остальные компоненты пространства имен контролируются пользователями-разработчиками. Клиенты маршрутизируются к нужной федерации автоматически. Таким образом, producer’ы и consumer’ы Kafka взаимодействуют с абстракциями уровня project и service. Это позволяет разработчику Big Data решений фокусироваться на собственном продукте, не вдаваясь в привязку к конкретным кластерам, адресам брокеров и прочим особенностям конфигурирования. Например, следующая пара строк на Java показывает, как объявить в коде использование нужной федерации:
var props = new Properties();
props.put(BookingProducerConfig.FEDERATION_CONFIG, “payments”);
var producer = new BookingProducer<String, String>(props);
Зоопарк Big Data или что внутри федерации
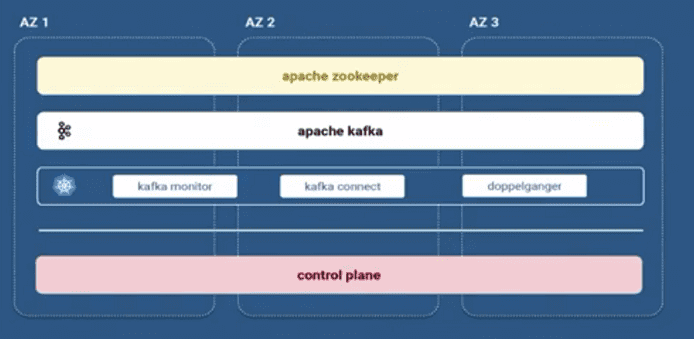
Каждая федерация Kafka-кластеров в Booking.com включает целый набор компонентов, помимо самой стриминговой платформы:
- Apache Zookeeper, который необходим Kafka для хранения метаданных о разделах (partitions) топиков и выборе брокера в качестве контроллера, о чем мы рассказывали здесь;
- Kafka Monitor для отслеживания SLO и других метрик SRE- и DevOps-инженеров;
- Kafka Connect с набором коннекторов для обмена данными с другими Big Data системами;
- Doppelganger – внутренний репликатор Kafka-Kafka, разработанный Booking.com для собственных нужд.
Apache Kafka и Zookeeper развернуты непосредственно на физических серверах нескольких датацентров (bare metal), а прочие компоненты запущены в Kubernetes. Все кластера внутри федерации защищены и управляются через единую контрольную панель (Control Plane). Об обеспечении информационной безопасности Kafka-экосистемы в Booking.com мы поговорим завтра и рассмотрим особенности аутентификации, а также разберемся с SSL-шифрованием, сертификатами безопасности и самообслуживанием всех этих security-опций.
Как обеспечить эффективное использование и гибкое администрирование Apache Kafka для потоковой обработки больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

