1268
1268 
Содержание
Рассматривая облачные сервисы для Big Data проектов, мы уже говорили про SLA (Service Level Agreement, соглашение об уровне предоставления услуг) и упоминали показатели измерения эксплуатационной надежности в материале про эволюцию Agile-подходов. Читайте в нашей сегодняшней статье, как эти SRE-метрики помогают DevOps-инженерам и администраторам обосновать экономическую необходимость затрат на средства дополнительной защиты Big Data систем от сбоев и когда такие инвестиции выгодны бизнесу.
Зачем SLA мерит доступность Big Data системы и как это связано с SRE, DevOps и клиентами
Как правило, для Big Data характерна высокая или постоянная доступность, а также непрерывный режим работы – это значит, что система защищена, а также легко, быстро с использованием автоматизированных средств восстанавливается от небольших простоев [1]. Именно доступность считается главным показателем качества. Поэтому большинство облачных провайдеров для Big Data систем стремятся гарантировать значение этой метрики на уровне более 99% за счет защищенных протоколов, резервирования каналов передачи информации, шифрования SSH, изоляции данных, аутентификации и гибких настроек политики безопасности на основе ролей [2].
Вычисление и поддержание необходимого уровня доступности является одной из задач SRE (Site/System Reliability Engineering) – инженерной Agile-дисциплины обеспечения эксплуатационной надежности, которая возникла как продолжение DevOps. В частности, SRE уточняет, какие именно показатели эксплуатационной надежности приложений должны непрерывно измеряться и оцениваться. Обычно эти параметры и диапазоны их значений указаны в SLA – договоре между поставщиком и получателем услуги. Этот документ, возникший из практической методологии эффективной организации работ ИТ-подразделений ITIL, необходим провайдеру и клиенту сервиса по следующим причинам [3]:
- он содержит подробное описание предоставляемого сервиса и детали взаимодействия сторон (сроки действия соглашения, процедуры оплаты, разрешения конфликтов и т.д.);
- он включает полный перечень параметров качества услуги и их допустимых значений.
Сама библиотека ITIL в разделе описания процесса управления доступностью приводит следующие метрики оценки качества ИТ-сервиса [4]:
- доступность (availability);
- производительность (performance);
- надежность (reliability);
- сопровождаемость (maintainability);
- обслуживаемость (serviceability);
- безопасность (security).
Однако, SLA регламентирует отношения с внешним потребителем, а SRE-подход нужен, прежде всего, для внутреннего пользования, чтобы создать общую ответственность всех участников процессов разработки и эксплуатации за доступность сервиса. Поэтому требования к качеству сервиса, предписанные внутренним SRE-стандартом, обычно выше тех, что указаны в SLA [5].
SRE измеряет доступность по следующим показателям и целям уровня обслуживания, которые индивидуальны для каждого приложения и класса данных [5]:
- SLI (Service Level Indicator) — метрики времени (задержка запроса, пропускная способность, число запросов в секунду или число сбоев на запрос). Они, как правило, агрегируются во времени, а затем преобразуются в среднее или процент по отношению к пороговому значению;
- SLO (Service Level Objective) — целевые показатели совокупного успеха SLI в течение определенного периода времени (месяц, квартал и т.д.), согласованные заинтересованными сторонами.
Как оценить доступность сервиса во времени и деньгах
Фактическая доступность сервиса (A) за конкретный период зависит от планового значения этого показателя (B) и суммарного времени простоев (C) [1]:
A = (B — C) / B × 100 %
Например, если Big Data система не отвечала в январе в течение 45 минут, то ее уровень доступности составляет 99,9 % [1].
Однако, простой Big Data системы для бизнеса означает потерю денег. Поэтому очень важно определить максимально возможное время простоя и его цену, прежде всего в потерянных данных. Для этого используются следующие показатели [6]:
- RPO (Recovery Point Objective, целевая точка восстановления) – максимальный период времени, за который могут быть потеряны данные в результате инцидента. Например, если для системы определен RPO в 15 минут, это значит, что, в случае аварии систему удастся восстановить, но в ней будут потеряны данные не более, чем за последнюю четверть часа. В идеале этот показатель должен стремиться к нулю, однако на практике это почти нереализуемо. Для Big Data систем на Apache Hadoop автоматическое реплицирование данных в файловой системе HDFS помогает снизить RPO. Однако этого недостаточно для обеспечения высокой доступности всего сервиса. Вычисление RPO и поддержание ее на должном уровне относятся к задачам DevOps- и SRE-инженеров.
- RTO (Recovery Time Objective, целевое время восстановления) – промежуток времени, в течение которого система может оставаться недоступной в случае аварии, т.е. время, необходимое для восстановления полного функционирования сервиса после наступления аварийного события. Например, RTO равен 2 часа, если в датацентре произошла авария (пожар, наводнение и пр.), и сервис должен быть снова доступен через 120 минут или раньше. SRE-инженеры организуют систему так, чтобы за это время восстановить работоспособность системы на резервном оборудовании или площадке с помощью различных технологий отказоустойчивости или восстановления из резервных копий на другой сервер. RTO, как и RPO, должен быть как можно меньше.
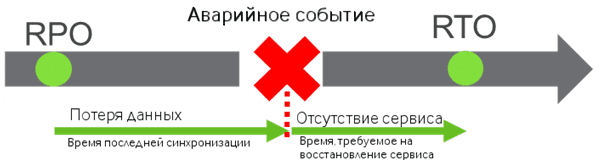
Построив график зависимости финансовых потерь от простоев системы, можно определить экономически выгодное для бизнеса значение метрик RPO и RTO [7]:
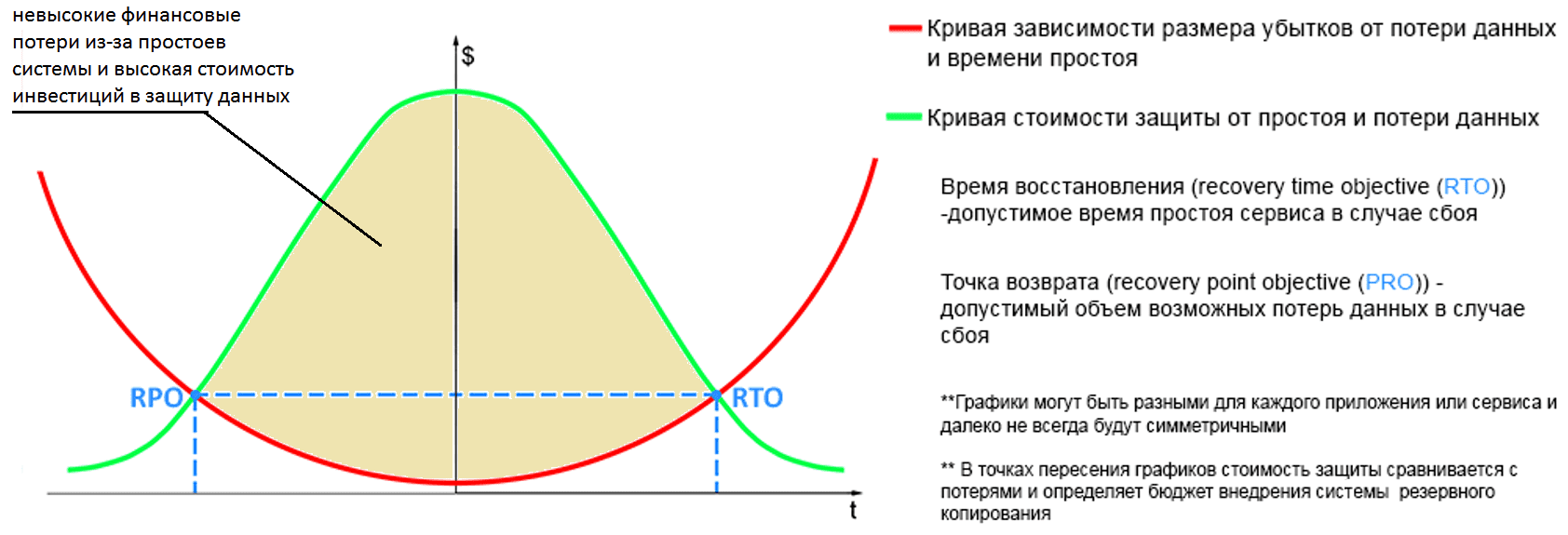
Чем меньше значение RPO и RTO, тем дороже будет стоить система восстановления. Снижение времени восстановления на 10—20% в разы увеличивает стоимость системы резервного копирования [7]. Однако, для крупных data driven компаний убытки от сбоев Big Data систем критичны не только в финансовом выражении: страдает репутация предприятия и парализуются операционные бизнес-процессы. Поэтому SRE оценивает риски через бюджеты ошибок, которые определяют баланс между доступностью и особенностями разработки и эксплуатации. Разработчики, желающие предоставить много новых функций, должны выбрать менее строгие SLO, чтобы продолжать поставку в случае ошибки. Владельцы сервисов, ориентированные на надежность, выбирают более высокий SLO, но его нарушение задержит новые выпуски. Согласно SRE-подходу, когда бюджеты ошибок исчерпаны, фокус смещается с разработки функций на повышение надежности [5].
Важно отметить, что решение о допустимых значениях RPO и RTO принимают не только DevOps— и SRE-инженеры. Поскольку эти SLO-метрики непосредственно влияют на финансовые показатели, определять их должен бизнес: руководители подразделений, ИТ-директор и аналитики. Сбалансированные SLO и SLA возможно разработать только при участии всех заинтересованных сторон.
Еще больше пользы от SRE-, DevOps и других Agile-приемов в нашем курсе обучения «Аналитика больших данных для менеджеров» в учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве.
Источники
- https://bigdataschool.ru/blog/hadoop-облачные-кластеры-сравнение/
- https://ru.wikipedia.org/wiki/Соглашение_об_уровне_услуг
- https://www.osp.ru/itsm/2012/09/13017362/
- https://realitsm.ru/2018/05/sre-vs-devops-konkuriruyushhie-standarty-ili-blizkie-druzya/
- https://olontsev.ru/2016/04/rpo-and-rto/
- https://softline.ru/about/blog/utrata-informatsii-vedet-k-potere-biznesa