 348
348 
Содержание
Продолжая разбирать доклад Александра Миронова из Booking.com, который был представлен 23 января 2020 года на зимнем Kafka-митапе Avito.Tech, сегодня мы рассмотрим, с какими проблемами столкнулись администраторы Big Data при обеспечении информационной безопасности своих Кафка-кластеров. Читайте в нашей статье про возможные методы аутентификации в Apache Kafka и их практическое использование в самообслуживаемой ИТ-инфраструктуре одной из крупнейших travel-компаний.
SASL или mTLS: какой метод аутентификации выбрать для Kafka-кластера
Напомним, Apache Kafka поддерживает целый ряд методов аутентификации [1]:
- SASL (Simple Authentication and Security Layer — простой уровень аутентификации и безопасности), включая следующие вариации:
- PLAIN (простой механизм передачи паролей открытым тектом),
- SCRAM (Salted Challenge Response Authentication Mechanism – механизм хранения данных и протокол аутентификации через хэши паролей, которые хранятся в Apache Zookeeper),
- GSSAPI (Generic Security Services API, общий программный интерфейс сервисов безопасности),
- OAUTHBEARER (на базе фреймворка OAuth 2.0, который позволяет стороннему приложению получать ограниченный доступ к службе HTTP от имени владельца ресурса через согласование взаимодействия между ними или разрешая стороннему приложению получать доступ от своего имени [2].
- mTLS (mutual TLS) – криптографический протокол взаимной (двусторонней) аутентификацией клиента и брокера, который является преемником SSL (Secure Sockets Layer — слой защищённых сокетов) и обеспечивает безопасность транспортного уровня (Transport Layer Security). В Kafka-сообществе, в основном, употребляется термин «SSL-сертификат», когда речь идет об аутентификации по методу TLS с помощью доверенных (зашифрованных) сертификатов [3].
Проанализировав все вышеописанные методы аутентификации в Kafka, команда администраторов Big Data инфраструктуры компании Booking.com выбрала именно mTLS по следующим соображениям [4]:
- SASL/PLAIN не подошел из-за представления паролей в виде текстовых файлов, которые необходимо поддерживать вручную;
- SASL/SCRAM предполагает хранение хэшей паролей в Apache Zookeeper, что проблематично при наличии множества этих распределенных сервисов, не синхронизованных между собой;
- SASL/GSSAPI в связке с защищенным сетевым протоколом Kerberos слишком сложен для настройки и конфигурирования;
- SASL/OAUTHBEARER требует стороннего сервиса для хранения REQUEST-токенов;
- mTLS позволяет относительно просто обеспечить двустороннюю аутентификацию брокера и клиента с помощью SSL-сертификатов.
Однако, при практической реализации mTLS перед администраторами Kafka-кластеров в Booking.com возник вопрос «Как обеспечить обновление и распределение по клиентам SSL-сертификатов в условиях самообслуживаемой Big Data инфраструктуры (self-service)?». Далее мы рассмотрим, как именно была решена эта задача.
Автоматическое управление SSL-сертификатами для mTLS-аутентификации
В компании уже имеется сервис, который выписывает SSL-сертификаты через вызовы по API (Certificate API). К нему обращается кластер Kafka по защищенному mTLS-соединению, чтобы проверить SSL-сертификат брокера и по необходимости получить новый с поддержкой динамического обновления конфигурации. Это делается с помощью Puppet-модуля, который раз в полчаса обращается к Certificate API и проверяет наличие действующих сертификатов на узле кластера и срок их действия. При необходимости обновить SSL-сертификат брокера этот Puppet-модуль автоматически получает его от Certificate API и отправляет на нужный узел, перезагружая SSL-контекст в самом брокере.
Аутентификация на стороне клиентского приложения обеспечивается с помощью внутреннего сервиса c метаданными (Service Directory) и хранилища сертификатов (Vault), взаимодействие между которыми организовано через собственный сервис Authr.
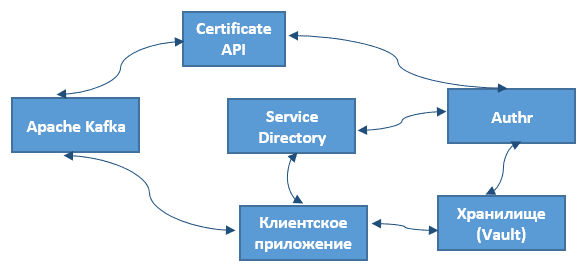
Примечательно, что весь этот процесс взаимной аутентификации полностью автоматизирован и особенности его реализации скрыты от пользователя. Это повышает уровень абстракции всей Big Data системы и улучшает пользовательский опыт, обеспечивая бесперебойную работу в режиме самообслуживания (self-service). Подробности решения изложены в видеодокладе Александра Миронова, представленном 23 января 2020 года на зимнем Kafka-митапе Avito.Tech [4]. По аналогичному принципу администраторы кластеров Kafka в Booking.com организовали авторизацию, о чем мы поговорим в следующей статье.
А как на практике обеспечить информационную безопасность кластера Apache Kafka для потоковой обработки больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

