Продолжая рассматривать примеры для обучения дата-инженеров по построению ETL-конвейеров, сегодня разберем, как перенести данные из облачного объектного хранилища AWS S3 в озеро данных на Hadoop HDFS с помощью готовых процессоров Apache NiFi. Такой кейс актуален для многих предприятий, которым необходимо мигрировать с сервисов Amazon в другие хранилища больших данных.
Перенос данных из AWS S3 в Hadoop HDFS с Apache NiFi
Напомним, HDFS как распределенная файловая система Apache Hadoop является основным хранилищем данных, которые используют приложения этой экосистемы. Чтобы перенести данные из корзин облачного объектного хранилища Amazon, сперва следует создать пользователя IAM (Identity and Access Management) – службы, которая обеспечивает точный контроль доступа во всех сервисах AWS. На этом же этапе необходимо установить разрешения для пользователя и получить идентификатор доступа и секретный ключ, а также настроить права доступа к данным.
Далее следует запустить системные службы Hadoop: NameNode, DataNode, менеджер ресурсов YARN и Data manager. Все они отвечают за распределенную параллельную обработку данных. В Apache NiFi все операции с данными выполняются с помощью процессоров. Процессоры используются для прослушивания входящих данных, извлечения из внешних источников и их публикации, преобразования и пр. Например, процессор GetFile получает файлы из локальной файловой системы и что-то с ними делает. Фактически, он создает FlowFiles из файлов в каталоге. При этом NiFi будет игнорировать файлы, для которых отсутствуют права хотя бы на чтение. Если готовых процессоров не достаточно для решения задач инженерии данных, разработчик Data Flow может самостоятельно создать собственный, о чем мы подробно писали здесь.
Для рассматриваемой задачи переноса данных из облачного объектного хранилища AWS S3 в Data Lake на Hadoop HDFS можно использовать два готовых процессора Apache NiFi:
- ListS3 — извлекает список объектов в корзине AWS Этот процессор для каждого объекта в списке создает потоковый файл (FlowFile), представляющий объект, чтобы его можно было получить вместе с FetchS3Object. Процессор FetchS3Object извлекает содержимое объекта S3 и записывает его в содержимое FlowFile. Процессор ListS3 предназначен для работы на основном узле только в кластере. Если первичный узел изменится, новый первичный узел продолжит работу с того места, где остановился предыдущий узел, без дублирования всех данных.
- PutHDFS – записывает данные потокового файла в распределенную файловую систему Hadoop (HDFS).
Напомним, Apache Hadoop позволяет настраивать свойства хранилища ключей и/или хранилища доверенных сертификатов. Если требуется применить защищенную SSL файловую систему, такую как swebhdfs, можно использовать конфигурации Hadoop вместо контекстной службы SSL.
Одним из главных достоинств Apache NIFI является веб-GUI, который сводит построение ETL-конвейеров к графическому моделированию. Это снижает порог входа в технологию и позволяет решать задачи дата-инженерии даже начинающим специалистам. После переноса готовых процессоров на холст в рабочей области фреймворка, следует настроить конфигурационные параметры каждого обработчика. В частности, для процессора ListS3, который считывает список файлов из корзины S3, следует установить идентификатор ключа доступа и секретный ключ доступа, полученные при создании пользователя IAM.
Для процессора PutHDFS, который записывает данные потокового файла в HDFS, наиболее важными параметрами являются ресурсы и каталог конфигурации Hadoop. Для ресурсов конфигурации Hadoop следует указать пути к файлам core-site.xml, yarn-site.xml, mapred-site.xml и hdfs-site.xml. Также следует указать директорию, в которую будут помещаться файлы из S3.
После задания всех конфигурационных параметров каждого процессора, их необходимо соединить на холсте Apache NiFi, а потом запустить.
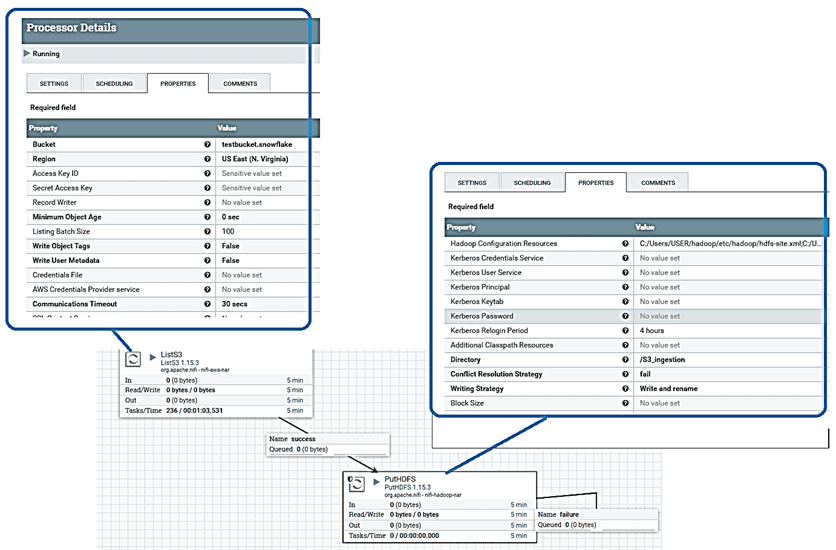
После этого файлы будут перемещаться из корзины Amazon S3 в указанный каталог Hadoop HDFS. Другой пример построения аналитического конвейера в Apache NiFi смотрите в нашей новой статье.
Освойте все тонкости администрирования и эксплуатации Apache NiFi для эффективной аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://medium.com/@emmanueloffisong2002/data-ingestion-from-aws-s3-to-hdfs-a11bfc05b512
- https://NiFi.apache.org/docs/NiFi-docs/components/org.apache.NiFi/NiFi-hadoop-nar/1.5.0/org.apache.NiFi.processors.hadoop.PutHDFS/index.html
- https://NiFi.apache.org/docs/NiFi-docs/components/org.apache.NiFi/NiFi-aws-nar/1.5.0/org.apache.NiFi.processors.aws.s3.ListS3/index.html
- https://NiFi.apache.org/docs/NiFi-docs/components/org.apache.NiFi/NiFi-aws-nar/1.5.0/org.apache.NiFi.processors.aws.s3.FetchS3Object/index.html