 1044
1044 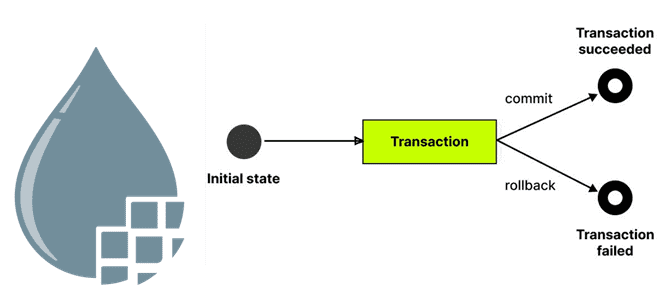
Зачем в Stateless-движке настраивать порт отказа, почему этот механизм в Apache NiFi подходит для надежных и транзакционных источников, но не для всех протоколов передачи данных, а также чем классический режим выполнения эффективнее в эксплуатации.
Транзакционность операций с FlowFile в Apache NiFi
О том, что Apache NiFi поддерживает два механизма выполнения: традиционный и stateless, мы уже писали здесь и здесь. Таким образом, при проектировании конвейера обработки данных в Apache NiFi перед дата-инженером встает не только вопрос выбора подходящих процессоров, но и механизма выполнения. Механизм выполнения (Execution Engine) определяет поведение компонентов в рамках группы процессов (Process Group). Термином группа процессов в NiFi называется объединение нескольких процессоров в одну группу, чтобы лучше организовать потоковый конвейер.
По умолчанию используется классический (традиционный) механизм выполнения Traditional Engine, с которым каждый компонент в группе процессов планируется независимо. Для буферизации данных между процессорами используются очереди. Каждый процессор работает с данными в своей очереди независимо от других процессоров. Традиционный движок является stateful, поскольку сохраняет данные в каждой очереди в репозиториях NiFi, обеспечивая их восстановление в случае перезапуска приложения.
Stateless-движок, как следует из его названия, не обеспечивает сохранение состояний, выдавая группе процессов определенное количество параллельных задач. Каждая параллельная задача отвечает за выполнение всего потока. Source-процессоры, у которых нет входящих соединений, запускаются только один раз. Данные в очереди не сохраняются при перезапуске приложения и теряются. Таким образом, Stateless Engine подходит для работы с надежными и воспроизводимыми источниками данных, поскольку выполняет фиксацию только после успешного завершения всего потока.
Это обусловливает главное отличие механизмов выполнения. В классическом движке процессор является границей транзакции, завершая ее после выполнения действий с FlowFile. Далее FlowFile передается следующему процессору в потоке. В Stateless Engine границей транзакции является не процессор, а вся группа процессов. Поэтому для группы процессов в NiFi введено понятие таймаутов, которое применяется при использовании Stateless-движка. Параметр Stateless Flow Timeout позволяет гарантировать, что данные будут обработаны в течение некоторого ожидаемого периода времени. Если этого не произойдет, вся транзакция будет отменена. По умолчанию тайм-аут установлен на 1 минуту. Любые данные, которые поступают в конвейер со Stateless-движком выполнения, должны быть обработаны в течение 1 минуты, иначе произойдет тайм-аут, и вся транзакция будет отменена.
Помимо таймаутов, Stateless-движок имеет еще одну возможность для обработки сбоев, которая называется порт отказа (failure port). Порт отказа может находиться на любом уровне иерархии группы процессов, откатывая всю транзакцию. Это означает сброс любых FlowFile, которые обрабатываются в этой транзакции. Если источником транзакции является входной порт, переданный через него FlowFile, будет направлен на заданный выходной порт отказа. Если источником транзакции был процессор, он сможет отправить отрицательное подтверждение (NAK) или очистить любые ресурсы по мере необходимости.
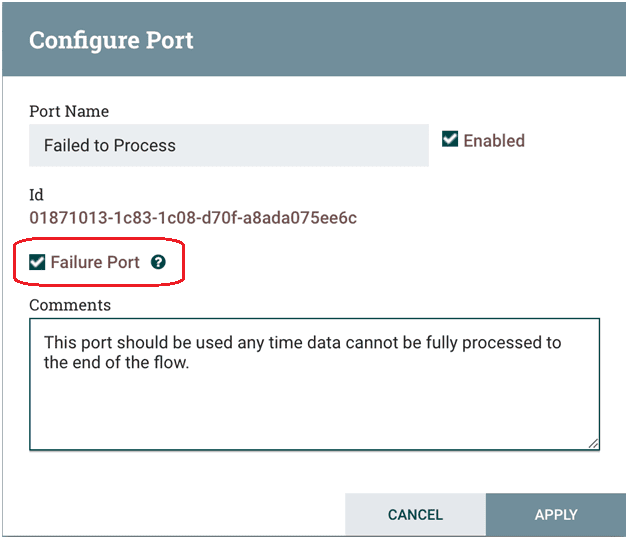
Классический движок при сбое направляет FlowFile в отношение failure и не использует таймауты для потока данных. Поэтому важно учитывать транзакционность, особенно, когда поток начинается с порта ввода данных из разных источников. Аналогично важно учитывать долговечность данных, которая в принципе характерна для NiFi благодаря сохранению данных в его базовых репозиториях. Классический движок NiFi после перезапуска продолжает обработку данных с того места, на котором остановился, обеспечивая надежное получение данных по любому протоколу, даже такому, где получатель не отправляет подтверждения на уровне приложения, например, как прямые TCP-соединения. Stateless-движок сбрасывает данные при перезапуске. Однако, это не имеет значения для протоколов, которые предоставляют подтверждения на уровне приложений, таких как JMS, Kafka, Kinesis и пр. А для таких протоколов, как HTTP, в NiFi есть процессоры, которые могут получать данные, выполнять некоторую обработку, а затем отправлять подтверждение. В этом случае безопасность обеспечивается передачей подтверждения на уровне приложений, которое отправляется из NiFi.
Получается, Stateless-движок можно использовать для транзакционного и надежного источника и единственного приемника данных, а также при необходимости обрабатывать FlowFile на нескольких процессорах как одну транзакцию. Транзакционность источника данных означает, что NiFi должен иметь способ указать того, что он получил данные, а источник сможет повторить отправку при отсутствии этого подтверждения. Это характерно для большинства протоколов очередей, таких как JMS, Kafka, Amazon SQS и Kinesis, а также HTTP и RPC-запросов. Но для прямых TCP-соединений это не свойственно. Stateless-движок рассматривает весь поток как одну транзакцию. Если это не так, нужно использовать классический механизм.
Кроме более высокой надежности, классический механизм выполнения более эффективен с точки зрения эксплуатации ресурсов. Он позволяет ставить в очередь большее количество FlowFile между процессорами и выделять больше ресурсов отдельным процессорам. А если приемник недоступен, Traditional Engine может ставить данные в очередь и периодически повторять попытки отправки данных в приемник, пока тот не станет доступен. Операции преобразования данных при этом не нужно выполнять повторно, поскольку NiFi ставит данные в очередь и восстанавливает их на соответствующем этапе потока. Наконец, если один FlowFile должен быть доставлен в несколько приемников, в классическом движке сделать это довольно просто, чего не скажешь о Stateless Engine.
Узнайте больше про администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

