
Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...
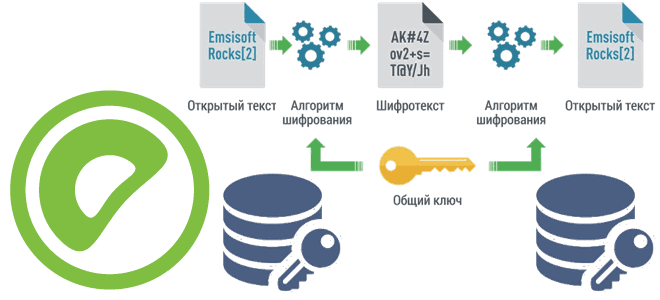
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...
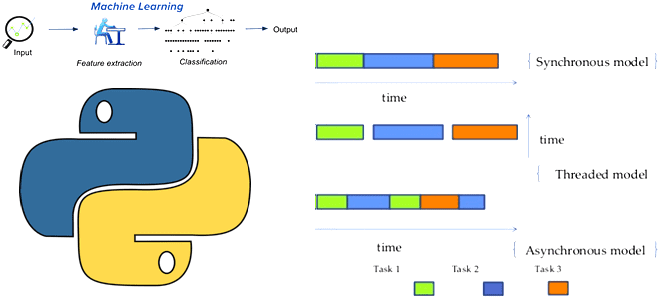
Поскольку концепция MLOps стремится устранить разрывы между разработкой ML-модели и ее имплементацией в эффективный программный код, сегодня поговорим про важную идею программирования, связанную с синхронностью и асинхронностью вызовов. Что такое асинхронное программирования, зачем это нужно в Machine Learning и какие Python-библиотеки поддерживают это. Проблемы синхронных вызовов в ML-системах В реальных...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...
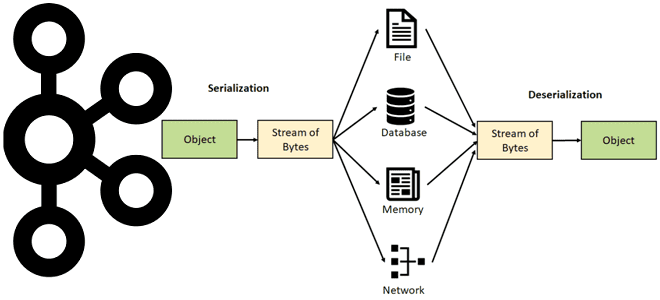
Недавно мы писали про сериализацию и десериализацию данных в Apache Kafka. Продолжая эту важную для обучения дата-инженеров и разработчиков распределенных приложений тему, рассмотрим особенности преобразования и валидации сообщений в JSON-формате, а также поговорим про автоматическую идентификацию формата сообщения. Сериализация и десериализация данных в Apache Kafka Выполняя роль интеграционной платформы, Apache...
В июле 2022 года на конференции Data and AI Summit компания Databricks представила новый проект для экосистемы Apache Spark под названием Spark Connect. Что это такое и как оно пригодится разработчикам распределенных приложений и дата-инженерам, читайте далее. Что не так с Apache Spark и зачем нужен новый проект Databricks Появившись...
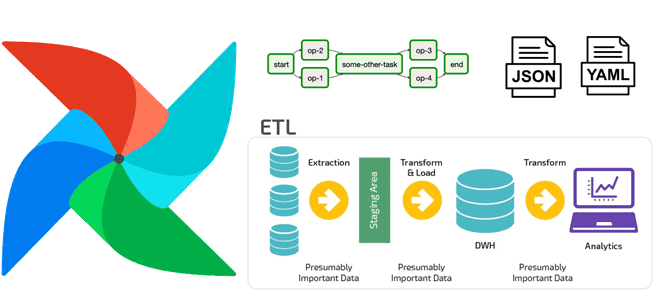
Дата-инженеры часто сталкиваются с изменением структуры конвейера обработки данных в Apache AirFlow, например, когда добавляются новые источники или приемники данных. Однако, менять DAG каждый раз при изменении внешних условий довольно утомительно. Читайте далее, как автоматизировать реорганизацию DAG, используя JSON, YAML-файл или другую плоскую структуру данных для хранения динамической конфигурации рабочего...
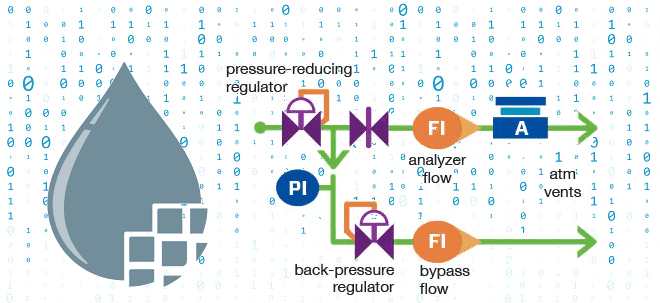
Чтобы сделать наши курсы для дата-инженеров по Apache NiFi еще более полезными, сегодня мы рассмотрим, что такое обратное давление и как этот механизм используется при потоковой обработке данных. Также поговорим про визуализацию back pressure в GUI, математические модели прогнозирования пороговых значения и настройку конфигураций. Что такое обратное давление в потоковой...

9 сентября 2022 года VMware Tanzu выпустили Greenplum 6.22. А спустя месяц, 7 октября вышел апгрейд этого релиза с исправлением ошибок. Разбираем, что нового в этих выпусках: полезные функции, улучшения и исправления ошибок, особенно важные для администратора кластера и дата-инженера. Greenplum 6.22.0 Сентябрьское обновление Greenplum 6.22.0 включает следующие функциональные возможности...
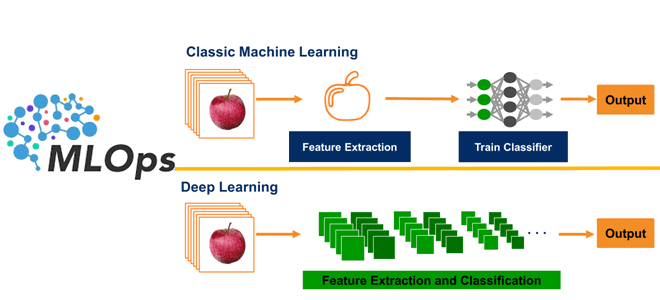
Сегодня разберем, что такое глубокое обучение и почему MLOps очень важен для этих методов Machine Learning. В чем особенности обучающих данных для моделей Deep Learning и зачем дополнять типовые MLOps-инструменты собственными разработками, избегая вредных антипаттернов. Машинное обучение vs Deep Learning: разница для MLOps Создание ML-систем сводится не только к разработке...