 570
570 
Содержание
Мы уже рассказывали, что такое реестр схема Apache Kafka и зачем он нужен. Чтобы глубже разобраться с этой темой, важной для обучения разработчиков распределенных приложений и дата-инженеров, сегодня заглянем под капот Schema Registry и разберем работу этого компонента платформы Confluent Apache Kafka с продюсерами и потребителями.
Еще раз про реестр схем Apache Kafka и форматы данных
Confluent Schema Registry для Apache Kafka предоставляет уровень обслуживания метаданных в виде RESTful- интерфейса для хранения и извлечения схем данных в формате Apache AVRO, JSON и Protobuf. Он хранит версионную историю всех схем на основе указанной стратегии имен субъектов, предоставляет несколько параметров совместимости и позволяет изменять схемы в соответствии с настроенными параметрами совместимости и расширенной поддержкой их типов. Реестр схем предоставляет сериализаторы, подключаемые к клиентам Apache Kafka, которые обрабатывают хранение и извлечение схемы для сообщений Kafka, отправляемых в любом из поддерживаемых форматов.
Реестр схем существует вне и отдельно от брокеров Kafka: приложения-продюсеры и потребители сообщений по-прежнему общаются с Kafka, чтобы публиковать и читать данные из топиков. Одновременно они также могут обращаться к реестру схем для отправки и получения схем, описывающих модели данных для сообщений. Подробнее об этом мы писали здесь.
Таким образом, можно рассматривать Schema Registry как уровень распределенного хранилища для схем, который использует Kafka в качестве основного механизма хранения, воплощая следующие проектные решения:
- глобально уникальный идентификатор (GUID) каждой зарегистрированной схеме. Выделенные идентификаторы гарантированно будут монотонно возрастающими и уникальными, но не обязательно последовательными$
- Kafka обеспечивает надежную серверную часть и функционирует как журнал изменений с упреждающей записью (WAL, Write-Ahead Log) для состояния реестра схем и самих схем, находящихся в нем;
- Реестр схем предназначен для распределения с одноосновной архитектурой, а ZooKeeper или Self-Quarum механизм синхронизации Kafka координирует первичные выборы.
Напомним, реестр схем нужен для сериализации и десериализации сообщений, чтобы передавать данные по сети и/или сохранять их на диске. Сериализация Java делает использование данных на других языках неудобным, а независимые от языка форматы типа чистого JSON удобны для чтения, но не имеют строго определенного формата схемы. Это несет следующие недостатки:
- Недостаток понимания между потребителями и продюсерами данных – отсутствие структуры усложняет использование данных в разных форматах, т.к. поля могут быть произвольно добавлены или удалены, а сами данные могут быть повреждены. Поэтому, чтобы гарантировать взаимодействие между потребителями и продюсерами данных, нужен своего рода контракт между ними, аналогичный универсальному API.
- Высокие накладные расходы на передачу данных, поскольку что имена полей и информация о типе должны быть явно представлены в сериализованном формате, несмотря на то, что они идентичны во всех сообщениях.
Чтобы обойти эти проблемы, было предложено несколько межъязыковых библиотек сериализации, которые требуют, чтобы структура данных была формально определена схемами. Эти библиотеки включают форматы AVRO, Thrift, Protocol Buffers и JSON Schema. Схема четко определяет структуру, тип и значение данных посредством документации, а также помогает кодировать данные более эффективно. Изначально строковый формат Apache AVRO поддерживался Confluent-платформой по умолчанию. AVRO считается более популярным из-за преобразования данных в двоичный формат во время сериализации, что значительно снижает размер полезной нагрузки. Avro требует схемы не только во время сериализации данных, но и во время десериализации данных. Поскольку схема предоставляется во время декодирования, метаданные, такие как имена полей, не обязательно должны быть явно закодированы в данных. Это делает двоичное кодирование данных Avro очень компактным. Подробнее о формате AVRO мы писали здесь.
Как работает Confluent Schema Registry
Итак, реестр схем содержит сопоставление схем и их идентификаторов, используемых для публикации и использования данных продюсерами и потребителями сообщений. Это помогает уменьшить размер полезной нагрузки для каждой записи, поскольку продюсеру нужно просто передать идентификатор схемы, а не всю схему, что повышает производительность. При появлении новой схемы, она сперва регистрируется в реестре, который генерирует ее идентификатор и будет поддерживать сопоставление.
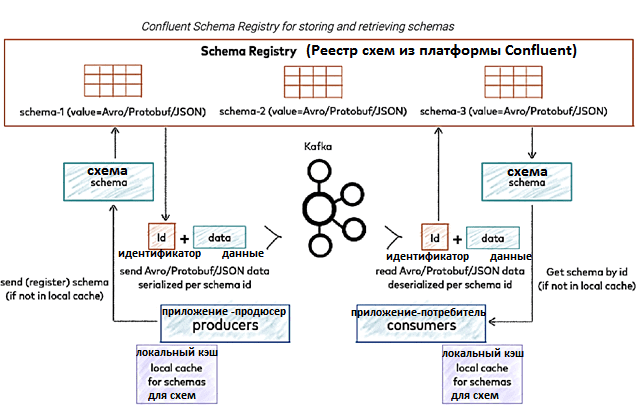
Kafka поддерживает внутренние топики _schemas, где каждая регистрация схемы фиксируется как одно событие. Перед публикацией какой-либо записи в Kafka продюсер обращается к Schema Registry через HTTP-вызов, чтобы получить идентификатор схемы. Вместо отправки всей схемы вместе с записью продюсер будет отправлять только идентификатор схемы, кэшируя его в локальном кэше для повторного использования, чтобы сэкономить на сетевых обращениях.
Когда потребитель потребляет запись, он считывает из нее идентификатор схемы и обращается к Schema Registry для ее получения через HTTP-вызов. Потребитель также будет кэшировать сопоставление схемы и ее идентификатор, которые будут использоваться позже, чтобы снизить накладные расходы на сетевую передачу данных. Экономия достигается благодаря тому, что продюсер и потребитель сперва проверяют наличие сопоставления схемы и ее идентификатора в локальном кэше.
Есть два способа регистрации схем в реестре схем:
- Автоматически, когда у продюсера для параметра register.schemas установлено значение true. Если схема еще не зарегистрирована, продюсер регистрирует ее. Этот подход не рекомендуется для применения в реальных проектах, поскольку продюсер может изменить схему, несовместимую с потребителем, что нарушит интеграционное взаимодействие разных приложений.
- регистрация отдельных схем более безопасным способом с запуском тестовых примеров для проверки совместимости измененных схем, что обеспечит контроль за счет плагинов gradle и maven.
Сервер реестра схем предоставляет несколько конечных точек для выполнения операций CRUD со схемами. На стороне продюсера сериализация и десериализация сообщений реализуется следующим способом:
- Класс продюсера Kafka apache.kafka.clients.producer.KafkaProducer отвечает за сериализацию ключа и значения перед публикацией данных. При использовании реестра схем этот сериализатор будет из пакета io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde, поскольку изначально сам Schema Registry является компонентом платформы Confluent, а не Apache Kafka.
- Смешанный сериализатор будет инициализировать класс CachedSchemaRegistryClient, который отвечает за выполнение HTTP-запроса к реестру схем и кеширование ответа после получения идентификатора схемы, используемого при последующей публикации с ней же.
- Если схема автоматической регистрации включена, схемы не кэшируются, и confluent.kafka.serializers.AbstractKafkaAvroSerializer вызывается каждый раз во время сериализации для регистрации схем, что накладывает дополнительные расходы и снижает производительность.
На стороне потребителя процесс сериализации и десериализации данных выглядит так:
- Класс потребителя Kafka apache.kafka.clients.consumer.KafkaConsumer отвечает за десериализацию ключа и значения перед использованием данных. При использовании реестра схем этот десериализатор будет из пакета io.confluent.kafka.streams.serdes.avro.SpecificAvroSerde, поскольку изначально сам Schema Registry является компонентом платформы Confluent, а не Apache Kafka.
- Смешанный десериализатор будет внутренне инициализировать класс CachedSchemaRegistryClient, который отвечает за выполнение HTTP-запроса к реестру схем и кеширование ответа после получения идентификатора схемы, используемого при последующем потреблении данных с той же схемой.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
15 декабря, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Какие исключения могут возникнуть при использовании реестра схем, читайте в нашей новой статье. А как использовать Apache Kafka для потоковой аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
[elementor-template id=»13619″]
Источники

