 1883
1883 
Содержание
В этой статье для дата-инженеров и аналитиков данных, рассмотрим, что такое широковещательные соединение в Apache Spark SQL, чем оно полезно и как работает на практических примерах. BROADCAST JOIN в SELECT-запросах Spark SQL, а также краткий ликбез по подсказкам или хинтам.
Что такое широковещательное соединение в Apache Spark SQL
Распределенная природа в Apache Spark предполагает выполнение вычислений на разных узлах кластера. При этом фреймворк соблюдает принцип локальности данных, выполняя задачи их обработки данных как можно ближе к месту нахождения, чтобы сократить накладные расходы на передаче по сети. Подробнее об этом мы писали здесь и здесь.
При выполнении запроса в Spark SQL вычислительная работа в рамках задания распределяется между несколькими рабочими процессами (worker’ами). Для выполнения большинства соединений worker’ы должны обмениваться данными, что называется перемешиванием (shuffle). Shuffle-операции замедляют выполнение программы из-за передачи данных по сети. Поэтому их рекомендуется избегать.
Когда датафрейм может поместиться в память рабочего процесса, избежать перетасовки поможет рассылка его полных копий каждому worker’у. Поскольку меньший датафрейм находится в памяти, каждый раздел большего датафрейма, распределенного по рабочим процессам, получает преимущество доступа к полному меньшему датафрейму – требуется просто выполнить поиск ключа соединения для каждой записи. Это ускоряет выполнение SQL-запросов с выражением JOIN.
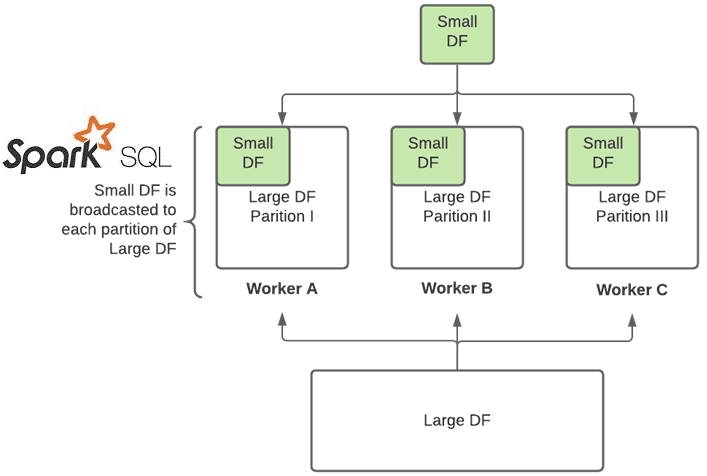
Предположим, в SQL-запросе есть один или несколько операторов внутреннего или левого соединения, INNER JOIN или LEFT JOIN соответственно. При соединении датафреймов разного (в десятки раз) размера в этих случаях рекомендуется применять широковещательное соединение (Broadcasting JOIN). Оно оптимизировано для соединений больших и малых датафреймов, а для соединения больших и больших, средних и малых фреймов данных широковещательная передача будет значительно медленнее или выдаст ошибку нехватки памяти/тайм-аута.
Задать исполняющему движку Spark SQL вид соединения можно с помощью так называемых подсказов или хинтов (hint). Подсказки позволяют пользователю предложить Spark применять нужные подходы для создания плана выполнения SQL-запроса. Например, хинт для широковещательного соединения может выглядеть так:
SELECT /*+ BROADCAST(small_df)*/ * FROM large_df LEFT JOIN small_df USING (id)
Для PySpark можно использовать аналогичный синтаксис подсказок:
large_df.join(small_df.hint(«broadcast»), how=”left”, on=”id”)
Какие вообще бывают хинты в Apache Spark SQL, рассмотрим далее.
Зачем вам хинты или что такое подсказки
Подсказки по разделам позволяют пользователям предлагать стратегию разделения, которой должен следовать Apache Spark. Подсказки COALESCE, REPARTITION и REPARTITION_BY_RANGE поддерживаются и эквивалентны API-интерфейсам соединения, перераспределения и перераспределения по диапазону данных соответственно. Эти хинты дают пользователям возможность настроить производительность и контролировать количество выходных файлов в Spark SQL. Когда указано несколько подсказок разделения, в логический план вставляется несколько узлов, но оптимизатор выбирает самую левую подсказку.
Выделяют следующие типы хинтов по разделам:
- COALESCE пригодится для уменьшения количества разделов до указанного. В качестве параметра принимает номер раздела.
- REPARTITION можно использовать для перераспределения на указанное количество разделов с использованием указанных выражений партиционирования. В качестве параметров принимаются номер раздела и/или имена столбцов.
- REPARTITION_BY_RANGE подойдут для перераспределения на указанное количество разделов с использованием указанных выражений разделения. В качестве параметров принимает имена столбцов и необязательный номер раздела.
- REBALANCE можно использовать для перебалансировки выходных разделов результатов запроса, чтобы каждый раздел был не слишком большим и не очень маленьким. В качестве параметров принимаются имена столбцов, по которым разделяется результат SQL-запроса. При наличии перекосов в данных, Spark разделит неравномерные разделы, чтобы они были не слишком большие. Эта подсказка полезна, когда нужно записать результат SQL-запроса в таблицу, чтобы избежать слишком маленьких или больших файлов. Однако, хинт игнорируется при отключенной структуре адаптивного выполнения запросов (AQE, Adaptive Query Execution).
Подсказки соединения позволяют пользователям предлагать движку Spark SQL оптимальную стратегию соединения. До Spark 3.0 поддерживался только хинт BROADCAST, а в версии 3+ добавились подсказки MERGE, SHUFFLE_HASH и SHUFFLE_REPLICATE_NL. Когда на обеих сторонах соединения указаны разные подсказки стратегии соединения, Spark отдает хинтам в следующем порядке: BROADCAST, MERGE, SHUFFLE_HASH, SHUFFLE_REPLICATE_NL. Когда обе стороны указаны с подсказкой BROADCAST или подсказкой SHUFFLE_HASH, Spark руководствуется типом соединения и размером отношений. Поскольку эта стратегия может не поддерживать все типы соединений, Spark не гарантирует использование стратегии соединения, предложенной в следующих хинтах:
- BROADCAST — широковещательное соединение. Сторона соединения с подсказкой будет транслироваться независимо от значения параметра autoBroadcastJoinThreshold. Если обе стороны соединения имеют широковещательные подсказки, будет транслироваться та, у которой меньший размер, вычисленный на основе на основе статистики. Псевдонимы для BROADCAST: BROADCASTJOIN и MAPJOIN.
- MERGE — соединение слиянием с сортировкой в случайном порядке. Псевдонимы для MERGE — SHUFFLE_MERGE и MERGEJOIN.
- SHUFFLE_HASH — случайное хэш-соединение. Если обе стороны имеют хэш-подсказки в случайном порядке, Spark выбирает меньшую сторону, вычисленную на основе, в качестве стороны сборки.
- SHUFFLE_REPLICATE_NL — соединение вложенных циклов с перемешиванием и репликацией.
Чтобы понять практический смысл подсказок, рассмотрим пример выполнения SQL-запроса с соединением нескольких датафреймов разного размера.
Практический пример оптимизации SQL-запроса с помощью хинта и BROADCAST JOIN
Предположим, необходимо провести вычисления с соединением таблиц в виде следующих датафреймов:
- large_df – большой датафрейм размером 1525 GB;
- small_df_a – небольшой датафрейм размером 0.5 GB;
- small_df_b – небольшой датафрейм размером 1.3 GB;
- small_df_c – небольшой датафрейм размером 0.006 GB.
В высокоуровневом псевдо-SQL запрос выглядит примерно так:
WITH large_df AS ( SELECT * FROM source_table ),small_df_a AS ( SELECT distinct id, source FROM details_table_a ),small_df_b AS ( SELECT distinct id, address FROM details_table_b ),small_df_c AS ( SELECT distinct id, name FROM details_table_c )SELECT * FROM large_df LEFT JOIN small_df_a USING (id) LEFT JOIN small_df_b USING (id) LEFT JOIN small_df_c USING (id)
Без указания стратегии соединения через хинт время выполнения составит около 15 минут.
В рамках левого соединения большого датафрейма с несколькими меньшими, которые все могут поместиться в памяти worker’ов, запустим запрос с BROADCAST-хинтом, явно транслируя меньшие датафреймы:
SELECT /*+ BROADCAST(small_df_a) */ /*+ BROADCAST(small_df_b) */ /*+ BROADCAST(small_df_c) */ * FROM large_df LEFT JOIN small_df_a USING (id) LEFT JOIN small_df_b USING (id) LEFT JOIN small_df_c USING (id)
Время исполнения этого SQL-запроса сократилось до 2-х минут. Такое почти 8-кратное улучшение скорости получилось за счет трансляции небольших датафреймов в память рабочих процессов и отсутствия перемешивания больших датафреймов. Таким образом, широковещательные соединения значительно разных по размеру датафреймов могут выполняться на порядок быстрее. Знание подобных приемов работы с подсказками существенно экономит время аналитиков данных и дата-инженеров. Подробнее про механизмы выполнения соединений в Apache Spark SQL читайте в нашей отдельной статье.
Освойте эти и другие практические тонкости применения Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark

