 290
290 
В этой статье мы поговорим про функции группировки и сортировки в распределенной СУБД Apache Impala. Читайте далее про особенности работы механизма группировки и сортировки Big Data, которые позволяют Impala-разработчику обрабатывать большие массивы данных любых типов с минимальными временными затратами.
Как работает механизм группировки и сортировки данных: особенности обработки Big Data
Стоит отметить, что Impala — это распределенная система управления базами данных (СУБД), которая дает возможность работать с Big Data структурами (например, таблицы, представления, партиции) с помощью языка SQL (диалекта Impala SQL). Нередко возникают случаи, когда необходимо упорядочить данные или применить к ним агрегирующие функции (например, для подсчета среднего, максимального, минимального значений или суммы). В Impala это позволяют сделать 2 основных механизма:
- группировка (grouping) — разбиение данных по группам (по определенному признаку) путем разделения их на логические наборы. Это дает возможность применять агрегирующие функции к каждой из групп в отдельности;
- сортировка (ordering) — упорядочивание данных по определенному столбцу в таблице. В Impala сортировка бывает имеет 2 категории: по возрастанию и убыванию (параметр категории задается отдельно). Главное преимущество сортировки данных в Impala в том, что ее можно применять как к числовым, так и к строковым столбцам. Строковые столбцы сортируются по алфавиту.
Особенности работы с группировкой и сортировкой в Impala: несколько практических примеров
В качестве примера сортировки и группировки данных рассмотрим данные таблицы Employees (сотрудники).
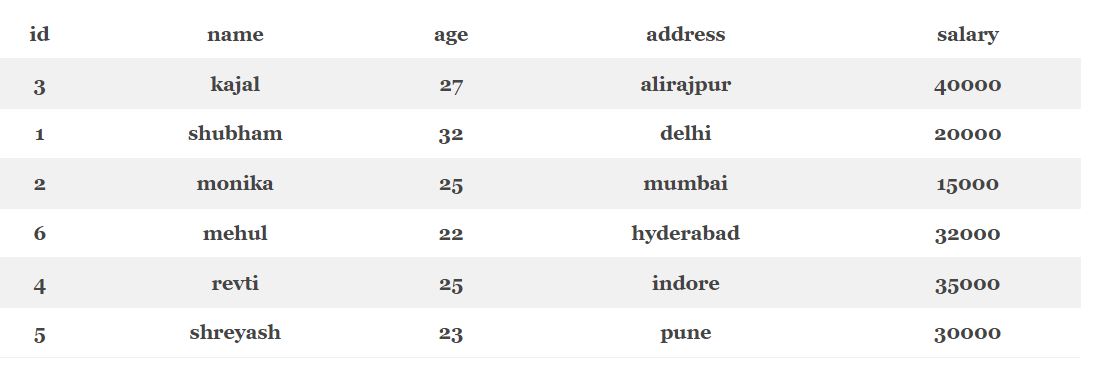
Для группировки данных таблицы используется SQL-оператор GROUP BY, который в качестве параметра принимает столбец, по которому будут создаваться группы. В качестве примера рассмотрим группировку с применением агрегирующей функции SUM для подсчета суммы зарплаты (salary) каждого работника. В качестве параметра группировки будем использовать столбец name (имя работника) [1]:
SELECT name, SUM(salary) FROM Employees GROUP BY name;

Как видно из результата, группировка позволила создать группы из имен рабочих, где каждое имя (name) рабочего является отдельной группой, а также для каждого рабочего была посчитана его общая заработная плата.
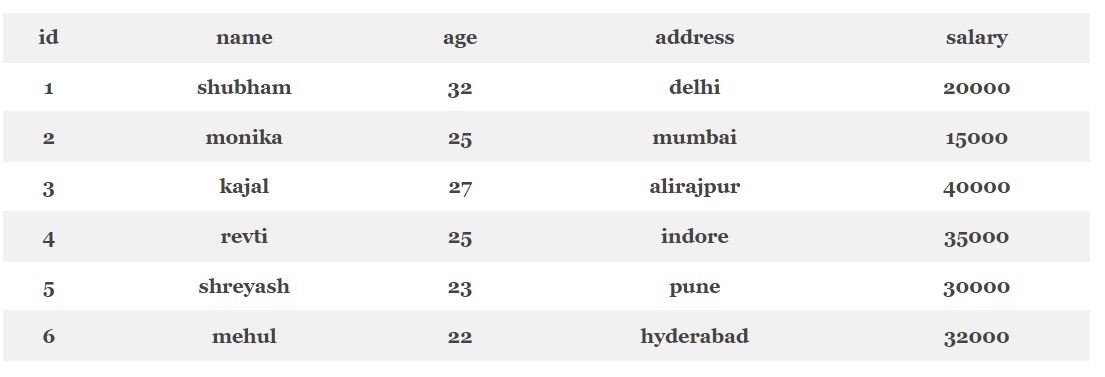
Для сортировки данных в Impala используется оператор ORDER BY, который в качестве параметра принимает порядок сортировки. Бывает всего 2 порядка: по возрастанию (ascending) и по убыванию (descending). В качестве примера рассмотрим сортировку данных по полю id в таблице Employees [2]:
SELECT * FROM Employees ORDER BY id ASC
Стоит также отметить, что параметр ASC (по возрастанию) является параметром по умолчанию, то есть вышерассмотренный фрагмент кода будет идентичен следующему [2]:
SELECT * FROM Employees ORDER BY id
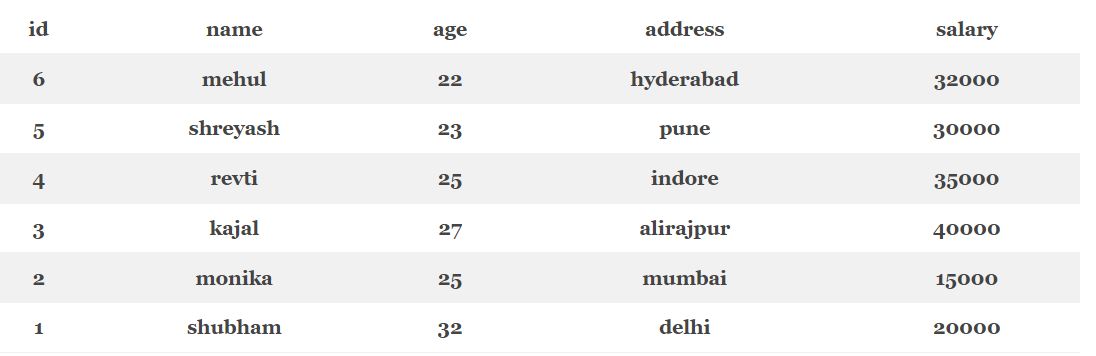
Для сортировки по убыванию необходимо в качестве параметра использовать зарезервированное слово DESC [2]:
SELECT * FROM Employees ORDER BY id DESC
Таким образом, благодаря сортировке и группировке, Impala обеспечивать Big Data разработчику возможность удобной и расширенной работы с большими массивами данных. Это делает Apache Impala весьма удобным средством для работы с Big Data.
Больше подробностей про применение Apache Impala в проектах анализа больших данных вы узнаете на практических курсах по Impala в нашем лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов в Москве:
HBASE: Администрирование кластера HBase
HIVE: Hadoop SQL администратор Hive
Источники

